I have a question on this node:
I tried to compare two tables, wheater there are differences. The problem is that this node kind of compares everything with everything. How can i adjust this, so that both tables are compared by using the unique row ID and only those rows who have the same ID are compared?
Or are there other solutions to this problem?
Thanks a lot
Hi @Mo_Gha , since you’re comparing row-to-row by their unique IDs, you can use the Joiner Node and configure it that way. After it joins two tables using the unique row IDs as the reference, there are multiple options to do comparisons in KNIME. The Column Comparator Node can be one of them. (If you deal with numbers, the Math Formula will calculate it for you). So, the option depends on what you want to do, given the data you have. There are many nodes available.
So basically i have two big excel sheets, that i want to compare. The first sheet is my test data and the second one is my reference data. I want to check if the values of my test data are different (or the same) to the values of my reference data. The attributes are the same in both sheets:
example:
ID | attribute 1 | attribute 2 …
12345 | value 1 | value 2 …
23456 | value 3 | value 4 …
…
As output i need an excel sheet with all the differences (and similarities) and the percentage, that shows how much of the testdata matches the reference data.
I hope I could describe my problem a little bit better than before.
So you suggested to use the joiner node to make one big table and then compare it to the reference table, did I understand that right? But for that i have to use a loop or something like that in order to compare all columns? And can I then compute all my results into one excel sheet?
Regarding the big table making it harder to compare selected columns, there’s nothing I can suggest specifically without looking at the table itself. Speaking generally, one of the many options you have includes unpivoting with a certain configuration, followed by the Duplicate Row Filter. Done correctly, this method will work. The only thing is whether the table is big enough that the unpivoting process might take a long time to finish.
You might want to share the table so I can see the header names and table dimension. Values are not important at this stage. (Header names are important to see if regex can be applied somehow).
…
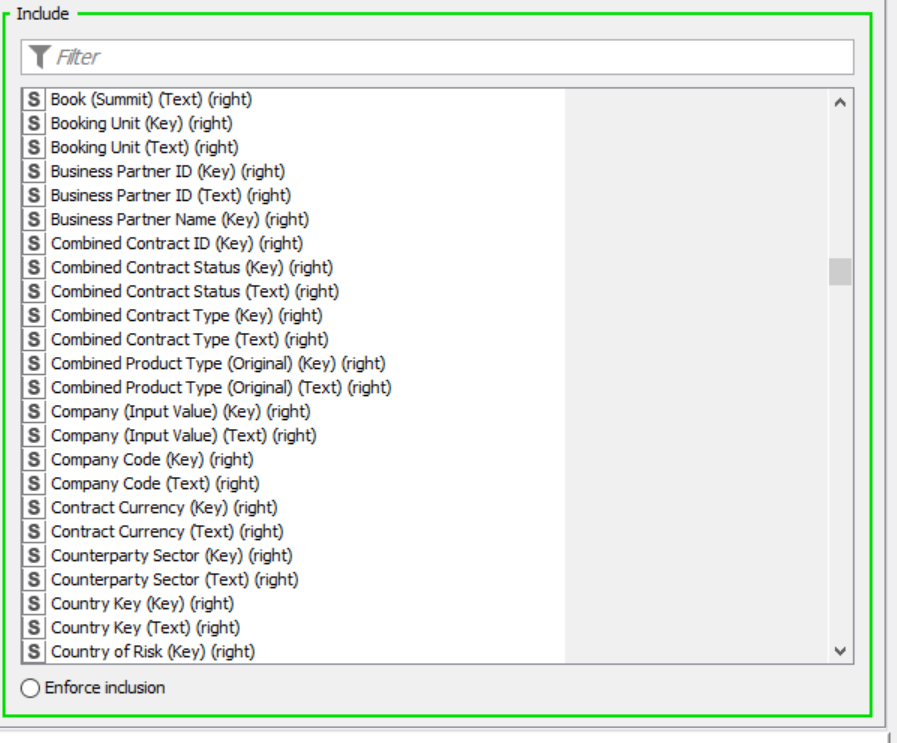
UPDATE: I’ve looked at the description of the Table Difference Finder node, and it mentions:
" The list contains the names of those columns in the reference table to be included for the comparison. It allows you to select the columns manually (by moving them to the right panel), via wildcard/regex (all columns whose names match the wildcard/regex are included) or via type selection (all columns with a certain type are included). In case of manual selection, the behavior for new columns (i.e. that are not available at the time you configure the node)can be specified as either Enforce exclusion (new columns are excluded and therefore not used for comparison) or Enforce inclusion (new columns are included and therefore used for comparison)."
Have you considered wildcard/regex for column selection?
ok thanks alot.
No, to be honest i did (do) not know what this option exactly means. Is this something like a filter/ criteria, which I can use for detailed comparison ? And what is the difference between wildcard and regular expression?
And you wanna compare the deadline columns once the two are joined, where the rest of the columns don’t share similar name patterns, then you use wildcard to compare only amongst the Deadline columns.
ok in that case i need the regular expression option. But what i meant is, if I use this option for example for the ID, does the node compare just the ID- columns of both tables or does it compare the whole tables by using the ID as s “criteria”.
I’m afraid I dont fully understand. Forgive me, but if you only want to do comparisons for a certain number of IDs, you can always use the row filter to filter in only the IDs you need, before joining tables/comparing. That way, all processes will apply for the target IDs only.
I want to compare the tables by using the IDs, kind of like a vlookup. For example, i want to compare the row with ID 12345 from test table with the row from reference table with the same ID and want to check wheater there are differences in the values or not.
I want to do this for all IDs included in the test table.
@Mo_Gha You can use the Reference Row Filter Node to filter out the IDs from the reference table that are not in the test table. If you configure the Joiner Node properly, you can even skip this step.
I’m afraid this is where I’ll pass the baton to someone else. I like helping people, but without figures or something to work with, there’ll be misunderstandings/miscommunications, and a lot of unnecessary going back-and-forth.
I try to do it with the joiner node, but how can built in that loop/workflow? Do you have any ideas? Both columns from both tables has to be the same, when they are compared.
Sorry btw i am new to KNIME and i am not used to it yet
Thank you very much for helping
I tried this, but the joiner excecution stops at 99 % and do not finish ??
This workflow extends Ipazin work to compare 2 tables with same structure meaning they have same number of columns and matching columns have same names and types. Comparison is done in a loop using Column Comparator node. In each loop iteration two columns are compared and and additional column with values TRUE or FALSE is created.
Aditionaly writes excel file with separated sheets for delete, inserted, updated, unchanged records
I loaded your workflow and just attached two excel lists instead of the table creator, but i quite dont get the methodic. In the end i get in the last column filter (which is named “same ones”) a table with four times as many columns as in my table? What does this exactly say?
Or did i make a mistake?
Thank you for your help.
i loaded the workflow but i still dont get the result. As before i get the same results. Do i have to exclude all other columns despite my relevant columns? The columns i mean by excluding are the columns that include (right) or (right)(right)? This is what i did not get yet ? Thank you very much !