I have a big challenge and I would really appreciate your help.
I need to do a forecast study, it should be done as follows, I have 3 tabs, each tab has a date period and some are repeated.
So I have the Forecast -3, the forecast -2 and the forecast which is the newest and most revised.
I would like to gather the date information of all the files but if it repeats itself it considers it the newest.
Example in forecast -3 I have the day 12/8/2023, resulting in 2,401 in forecast -2 it appears 2,322 and in forecast 2,666 so it should bring me 2,666
I’m leaving the flow below, if you got confused I can explain again.
But in short, I want to join all 3 tables and if any date is repeated it brings the newest information considering that -3 is the oldest, -2 is new and forecast is the most recent. KNIME_project2.knwf (503.1 KB)
Hi @Gabriel2020 , I think this flow would achieve what you need.
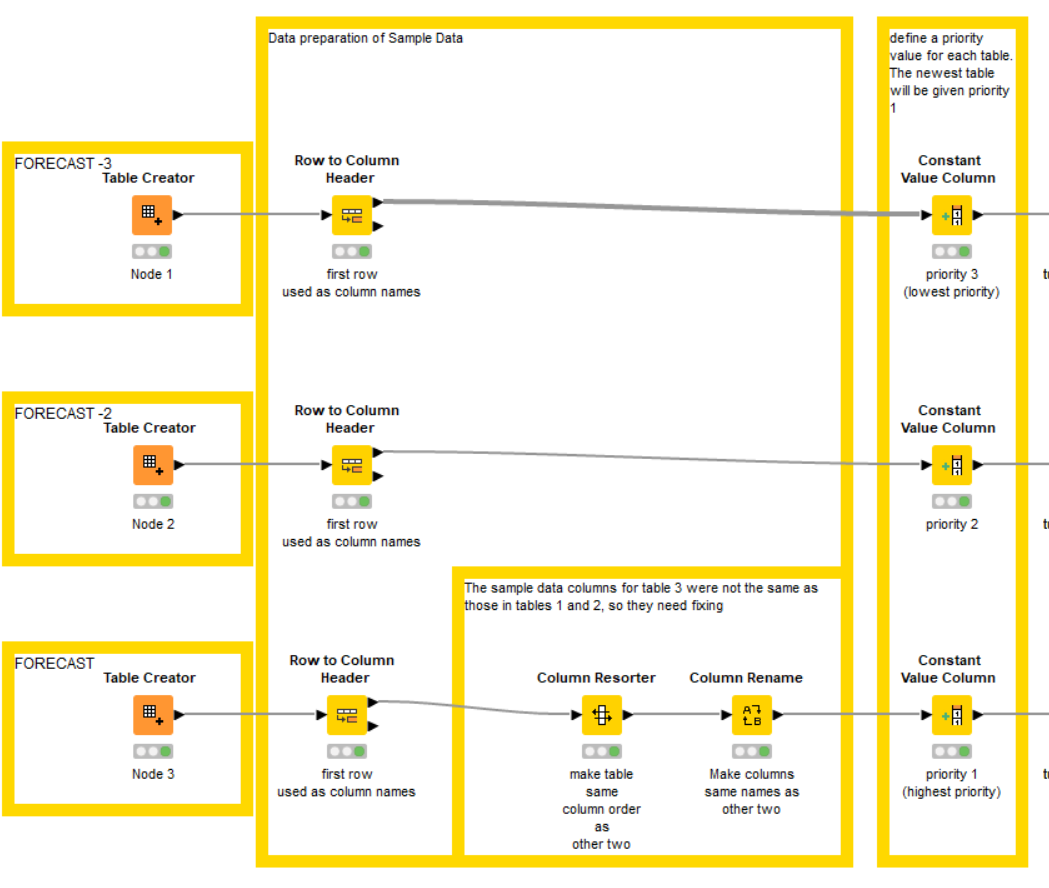
I have annotated the flow, so hopefully you can follow what it does.
Initially it does some data prep as you have what I think are the column names as row 1 in each, so this is fixed for processing… and it applies a constant “priority” of 3, 2 or 1 to each table,
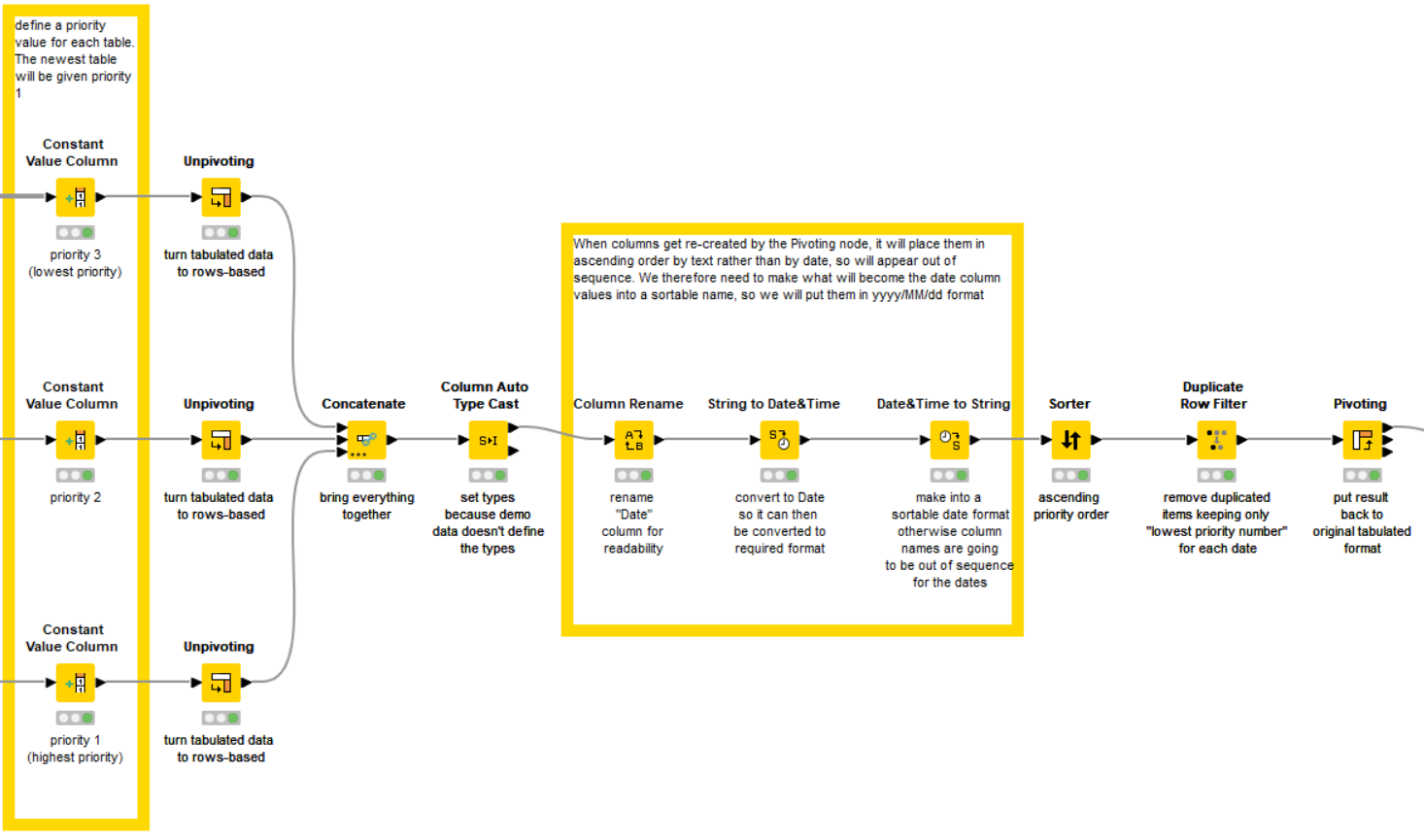
It then unpivots the tables so they are in row-format. After that it can concatenate the rows from each, sort them based on the 1,2,3 priority value given to each , remove duplicates for a given date, hub, etc and then pivot back into tabulated format.
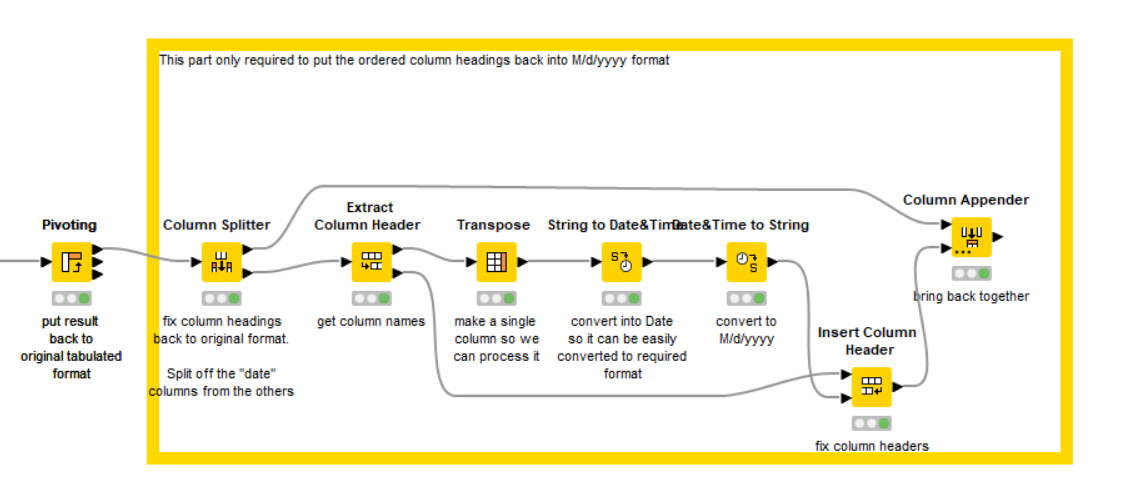
Your dates aren’t in a sortable format, so it adjusts those to be yyyy/MM/dd format prior to the Pivot to ensure the pivoted columns are in the correct sequence…