Hi ,
i been working on something for a friend but i ran in to something odd.
the speed of the loop decline exponentially with the no of data row input.
i tested with 10k row as a sample and the speed was fine.
However when i put the full set of data in ( 1 million row) , the processing speed seem to have drop significantly.
is it a hardware issue or some other issue i have overlooked?
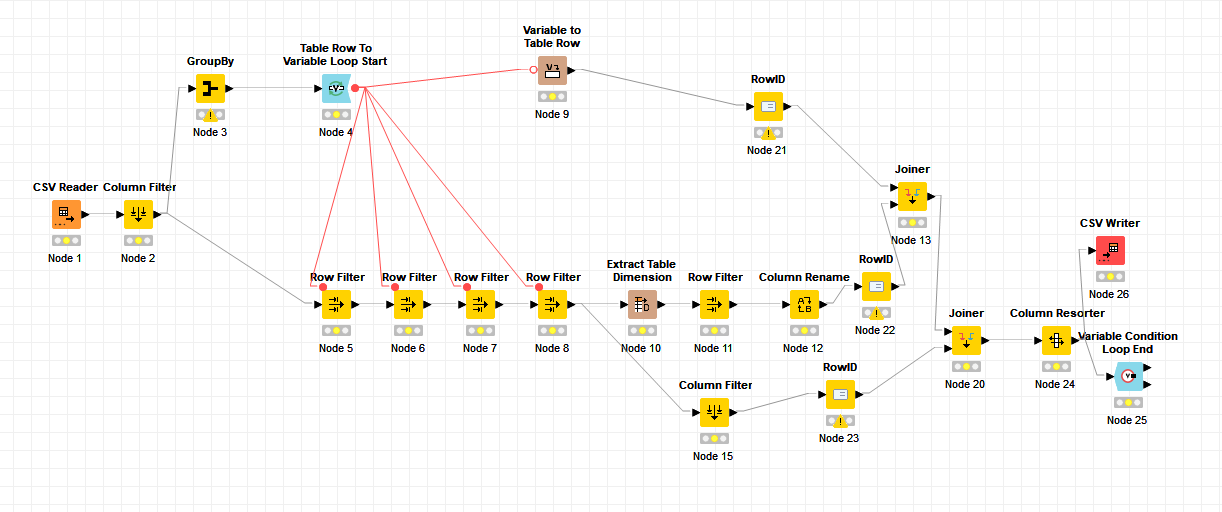
the aim of the flow is to sort row of data by a unique set of 4 criteria and count how many of such row there is and write it down in a csv file
Eg Tom apple 3 usa and tom apple 5 usa | is 2 different unique set of criteria
well if you are running a 1 million iteration loop it should take a while. And why are you using Variable Condition Loop End in combination with Table Row To Variable Loop Start node? You are not processing all rows or? Maybe better way is to use Group Loop Start node for your use case? First impression is you could use speed it up with different design. Can you share your input file (if confidential small dummy works just fine) and desired output?
I cannot help, but I can definitely confirm this behavior – I made these experiences as well (with any kind of loop node types). In case of larger tables, the loop execution time never seemed linear, but continuously slowed / dropped during execution (in other words: first iterations are quick, but become slower and slower with more iterations).
That used to be a problem with our loop nodes, however we fixed this. Now the time is constant if the data is not increasing over time. e.g. if with each iteration more data is processed, the iteration gets slower.
I made a small workflow which I used to test this:
Hello @ipazin
I was mainly using variable loop for some other dataset which is a lot smaller and was not aware of the group loop node. (since the variable loop node work and speed was not a concern)
Either case , i tried your suggestion and it seem to work a lot faster and was able to finish in less then 10 min, compare to the several hours before . Thank you for the suggestion
P.S: it about 1 million data row but about 80,000 iteration.
Hello @Iris
this is interesting , i will take a look when i have the time
Thanks
flow variables are available to all downstream nodes regardless of connection type (meaning you don’t need to pull 4 flow variable connection to each Row Filter node)