Hello, I am trying to automate a workflow for cleaning the data.
First step in cleaning is to check the datatype of the columns of input file.
I want to generate different variable for each column if it differs from the reference file. How can i do it?
Hi @Mitesh_Dama , welcome to the KNIME community forum,
I’m not sure what you mean by “generate different variable for each column if it differs…”. Can you show us what output you are wanting to achieve, preferably with a simple example.
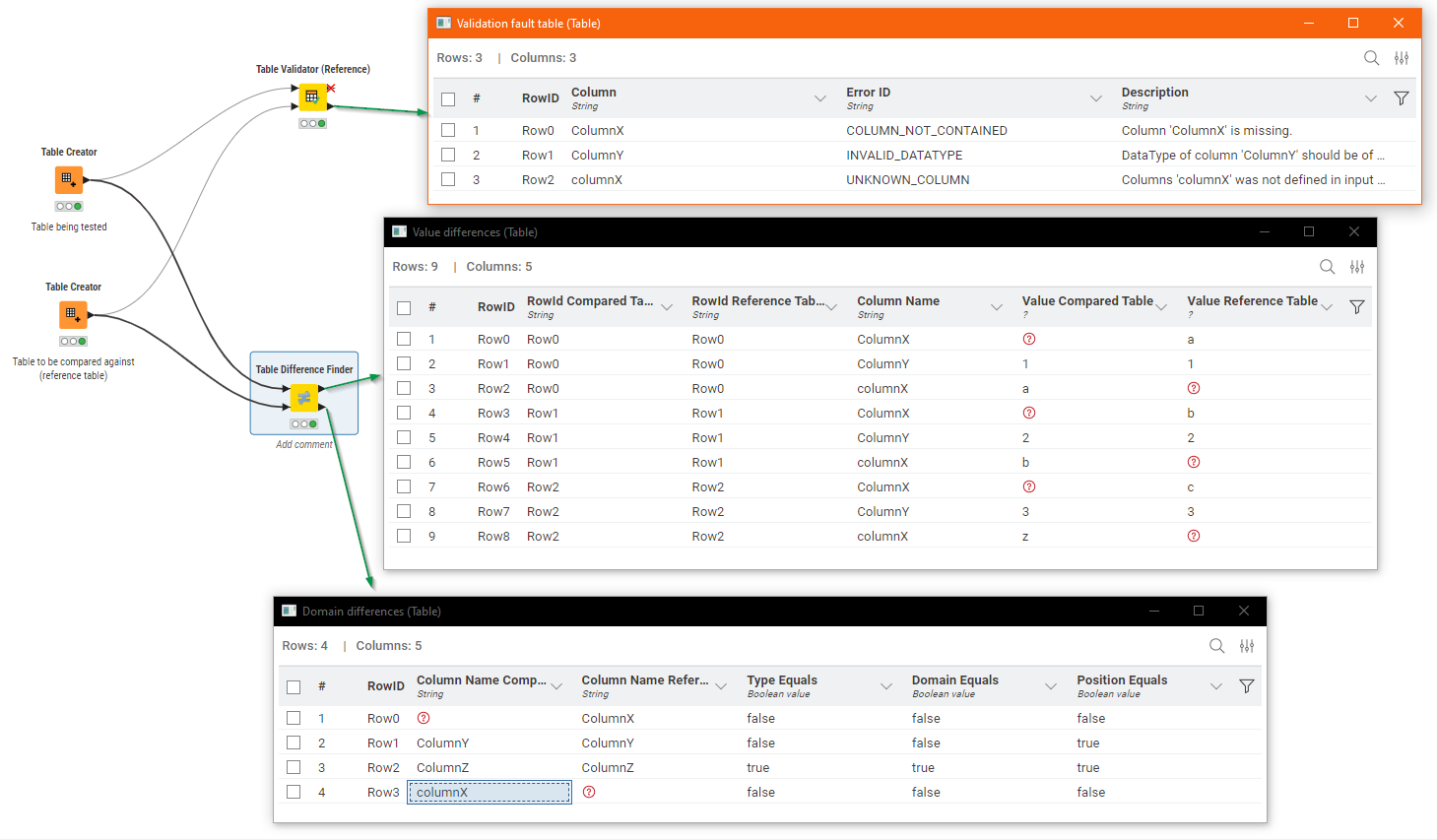
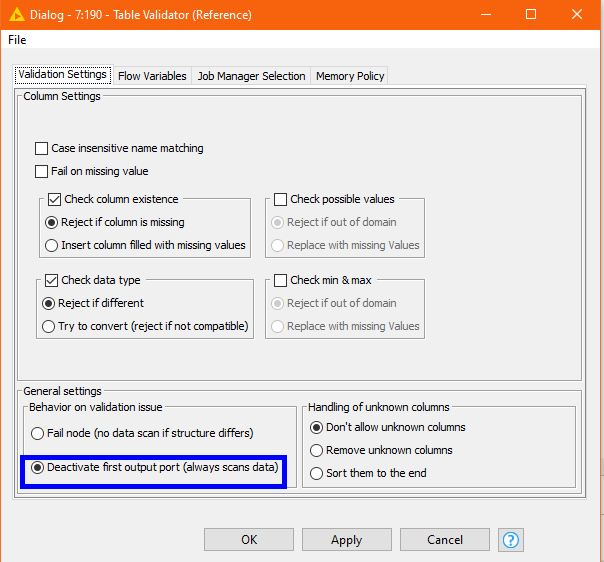
The Table Validator (Reference) node can be configured to return some table structure differences, whilst the Table Difference Finder will provide information about data differences.
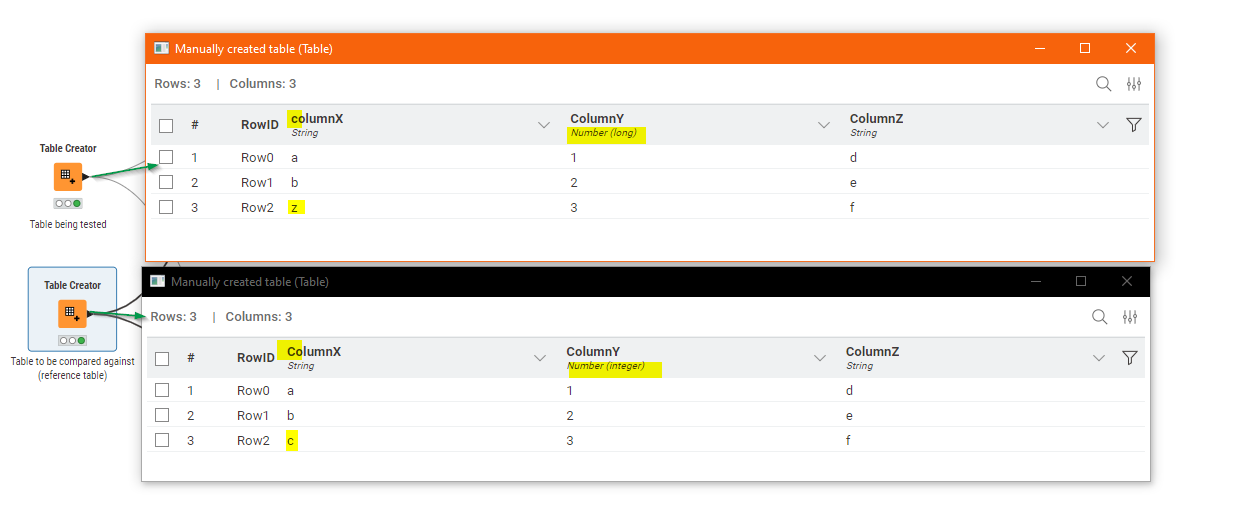
Take for example two data tables, with differences that I have highlighted:
Thanks @takbb . What I want to achieve -
I want to clean the table which has name and dimension columns.
As a refernece - Name should be string and dimensions should be number double datatype.
When I start cleaning input data, if any column is not according to correct data type, It shoud show in a separate table where I can use Case switch later to clean/ process this data.
Is there any other way to do this?
Thanks in advance
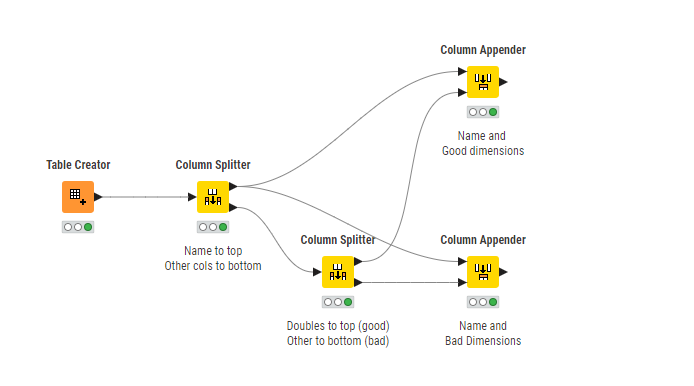
Hi @Mitesh_Dama , if your data is just Name column plus other columns that should be all doubles, can you not make use of the Column Splitter to break it up into two tables.
I’m sure this is over-simplified, but without seeing your data and knowing exactly how you will go about processing it, it feels like it might work. You could also use Extract Table Specification to get a list of the column names and data types and then maybe process that information to split out the columns, but the Column Splitter seems the simplest for what you have described.