I am new to KNIME but find the platform pretty intuitive and powerful.
One thing has me stumped and I am not finding a solution using the forum or google: I cannot get any tagger to work. I have tried the POS tagger, the OpenNLP NE tagger, and the StanfordNLP NE tagger.
As input, I am using the output from the PDF parser (have also tried TikaParser>StringtoDocument).
The taggers do create a new column (as per my settings) with the supposedly tagged documents, but I don’t see any tags anywhere.
I am using the DocumentViewer to look for the tags in the text.
I am not getting any error messages using the POS and OpenNLP taggers.
I would be most appreciative if someone could help me figure out what I am doing wrong, or where to look for the tags.
Thanks for your help!
(once I get this to work, I would also like to know how to use the Stanford tagger with the usual Stanford tags, e.g. as used in the python package; i.e. without me having to train it using the learner node).
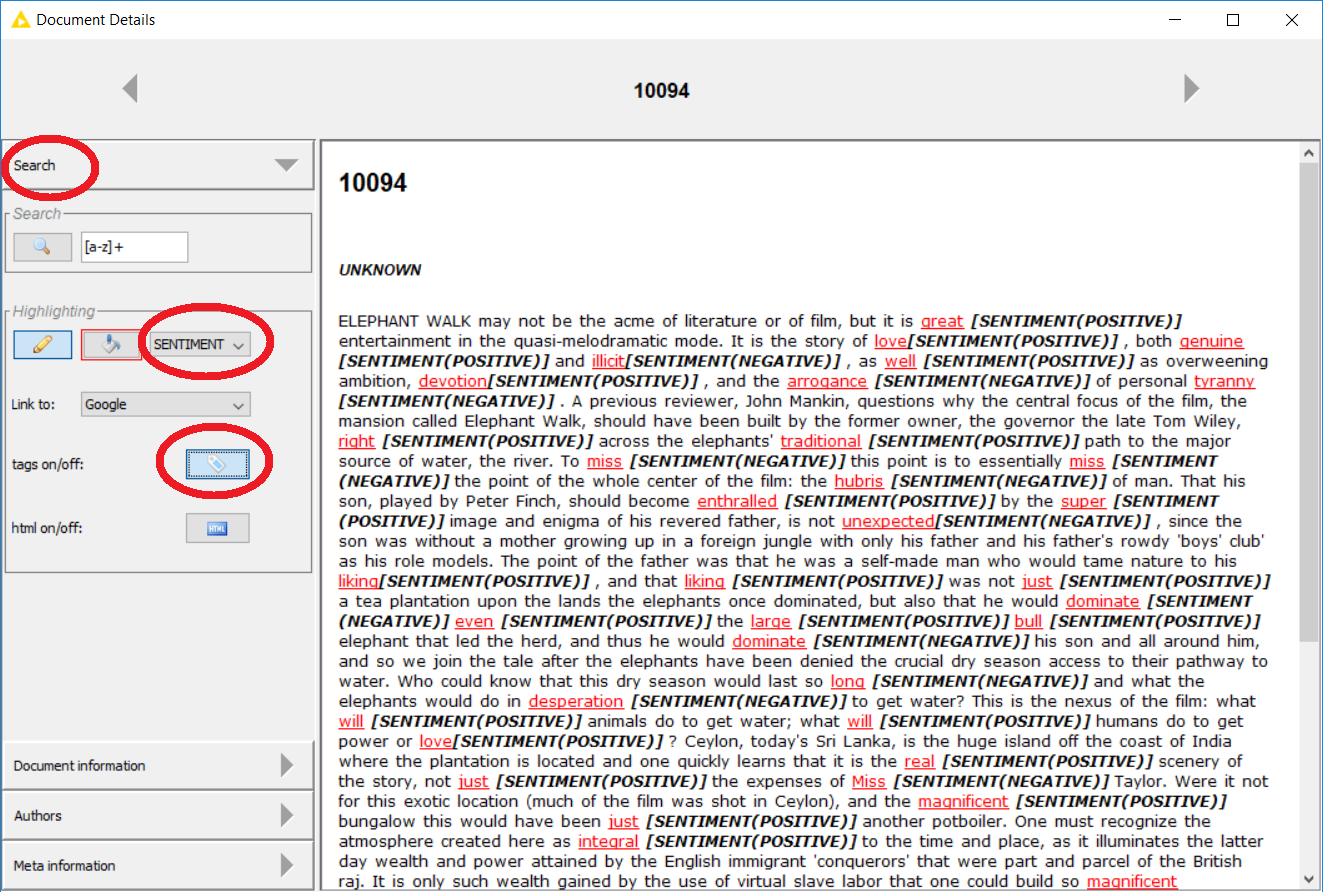
I’ve attached a screenshot of some sentiment tags as shown in the Document Viewer node. You do have to drill down a bit and select the appropriate options to actually see the tags - they won’t just appear by default. In my case I’ve selected SENTIMENT tags for highlighting, but for you it’s probably POS or something else. Also, make sure you’re clicking the tags on/off button.
If you configured the Document Viewer properly and still are not seeing tags, it might be another issue. In that case, are you able to post a minimal example workflow that would help diagnose the problem?
you can also use the Modifiable Term Filter node that removes all terms from the Document that were not tagged. Afterwards the Bag Of Words Creator node can be used to create a list of terms occurring in each document which also shows the corresponding tag.
About the Stanford Tagger:
There are two different Stanford Tagger nodes, the Stanford tagger which is a part-of-speech tagger and the StanfordNLP NE Tagger node which is used for named-entity recognition. Both nodes provide built-in models while the second one also provides the possibility to use a model that has been trained with the Stanford NLP NE Learner node.