Greetings! I’m a newbie and learning on my own and full immersion into KNIME. (So forgive me if I’m in the wrong place or not doing something right or…)
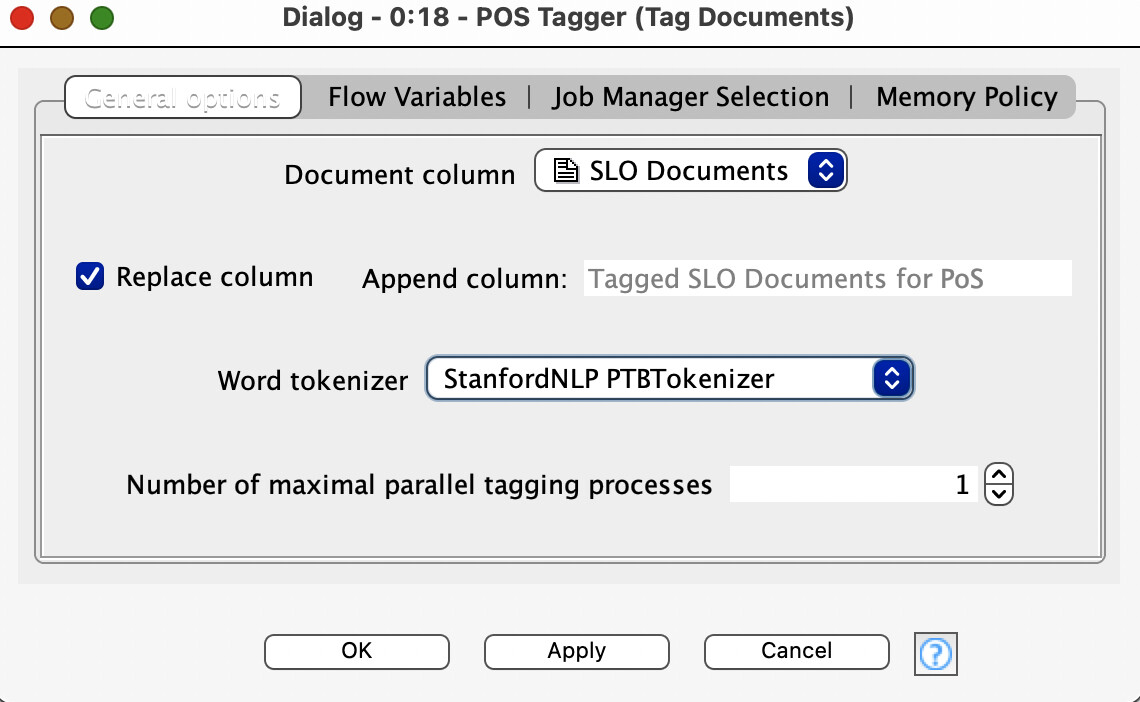
I noticed in the POS Tagger node configuration window that there is an option called “Word tokenizer”. Why isn’t this option called, say, a “Token tagger” or, just simply, a “POS tagger”?
If I have already converted a string-type to a document-type, the document-type has already been tokenized (but then may need some sort of tagging). Yes? In fact, the last option in the String to Document node is to choose a tokenizer and this option is labeled correctly. Then I could use the POS Tagger node to tag the tokens in each of the documents, but the option is labeled incorrectly (IMHO).
Am I missing something or is the POS Tagger node option of “Word tokenizer” confusing me.