Hello KNIMEONAUTS,
i have set up KNIME 4.1.3 and i am running some models using the KERAS plugin.
I have the workspace on D drive.
On C:\Windows\users\myUser\AppData\Local\Temp there is a
knime_container_DATE_someNumbers.bin.snappy
created for EVERY epoch trained (400 MB each). This makes training horribly slow and the machine unusable when HDD is full :(.
Why is this happening? And how do I end this nightmare??
Thx!!!
Niko
Hi there @niko314159,
welcome to KNIME Community!
Moved your question to new topic. The original one is a bit old and possibly not related 
Br,
Ivan
1 Like
THX Ivan!
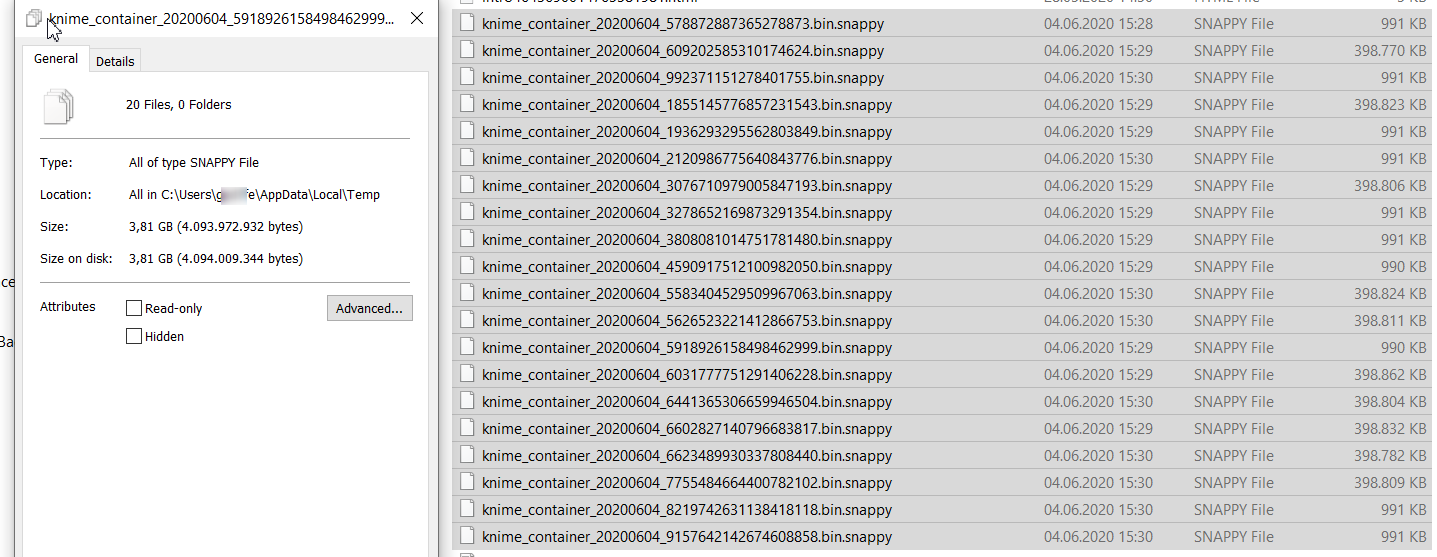
I have double checked. Rrunning “Keras Network Learner”
Running 10 epochs leads to 20 Files with 3.81 GB.
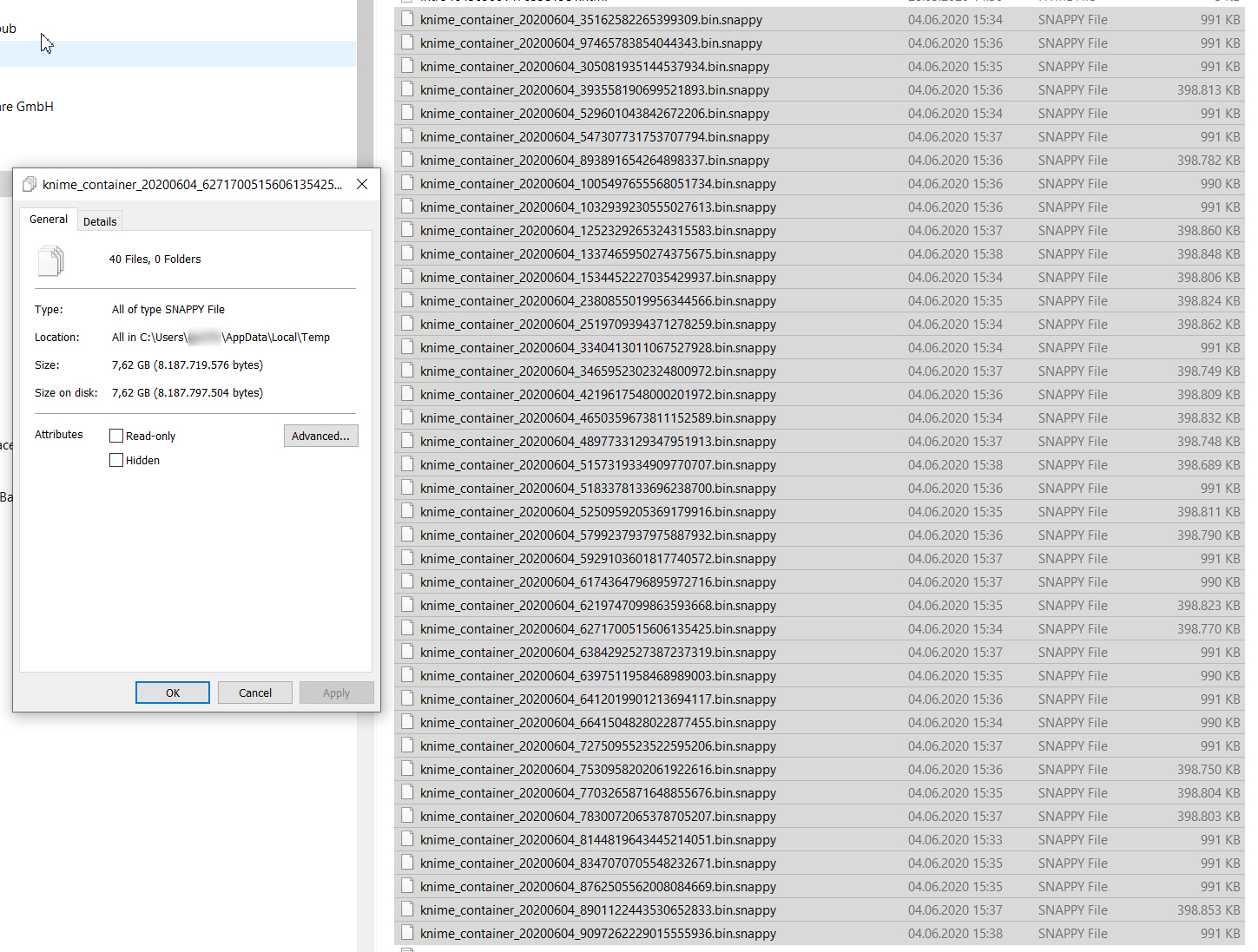
Running 20 epochs leads to 40 Files with 7.62 GB.
When i close the workflow all files are deleted.
I was not aware of your topic @niko314159 when I created a similar topic, but for Ubuntu this afternoon. Also Keras, also these bin.snappy temp-files.
Because of the large temp-files I run into disc space issues.
Maybe both issues are related?
Hello !
I have a similar problem with temporary files saving on my principal disc :
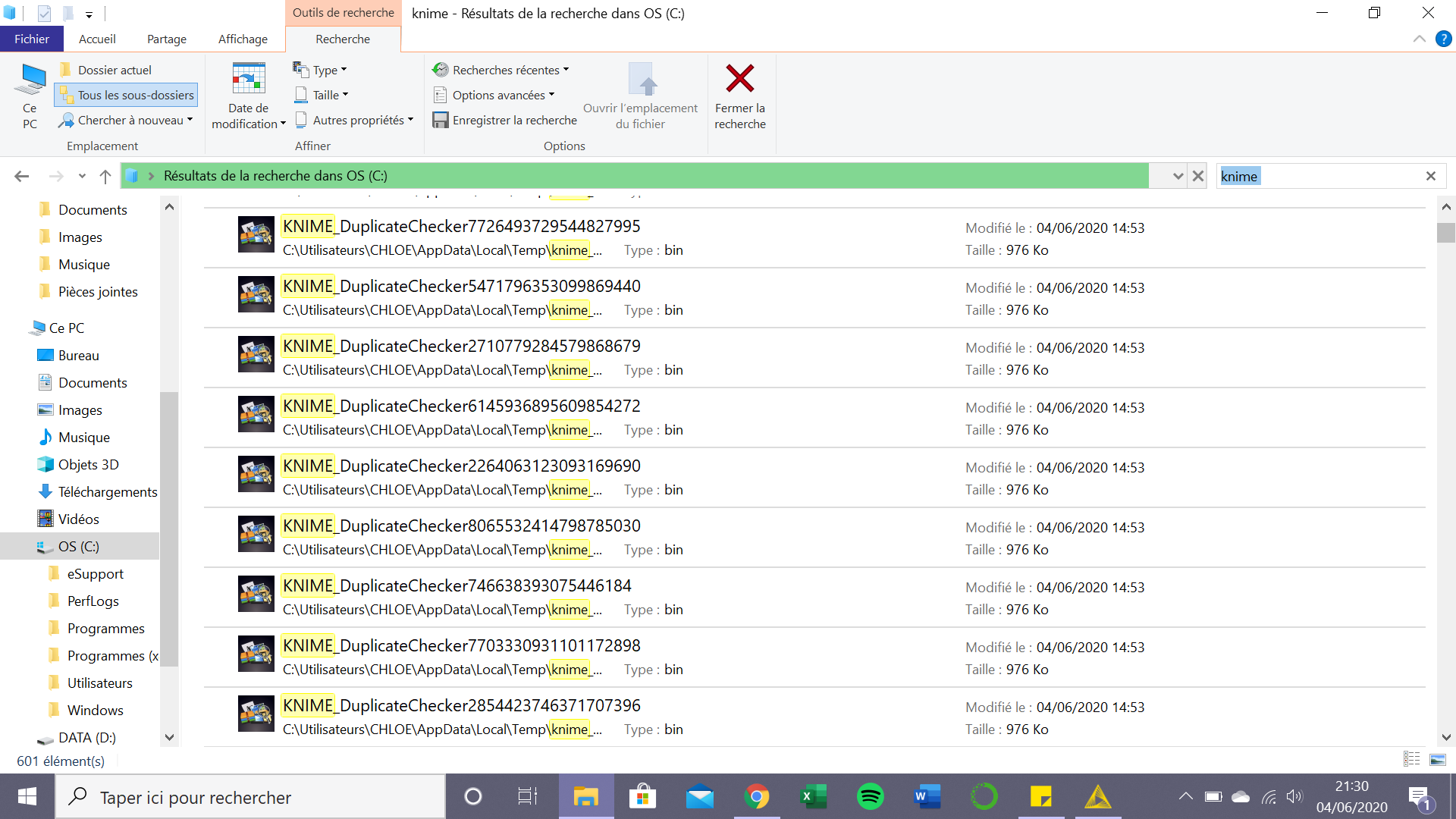
Can still my workflow work after delating these files ? Thanks
Chloe
Hi @niko314159,
You probably have the same problem as the problem linked by Jan. During shuffling of the input data intermediate tables are created which are not deleted again. You can disable shuffling for now (Can you confirm that this helps with the temp files?) and hope that this does not hurt the model performance too much. We are working on fixing the bug and I will let you know.
Best,
Benjamin
Hi @chlovi,
Can you describe what nodes you are using in your workflow? If it is not related to the “Keras Learner” you might want to create a new topic.
Best,
Benjamin
Hi Benjamin ( @bwilhelm ),
thanks for your reply!
And yes it fixes the problem of saving to disk 
BUT
- convergence seems to be a matter of luck now [with standard options for Adam optimizer]
- If it converges i see very high spikes in the loss over epochs. My dataset has 250k rather similar curves and i have used random shuffling to initially split the set. If i use tiny batches (128 instead of 2048. the later works fine with batch shuffling option) it still spikes badly

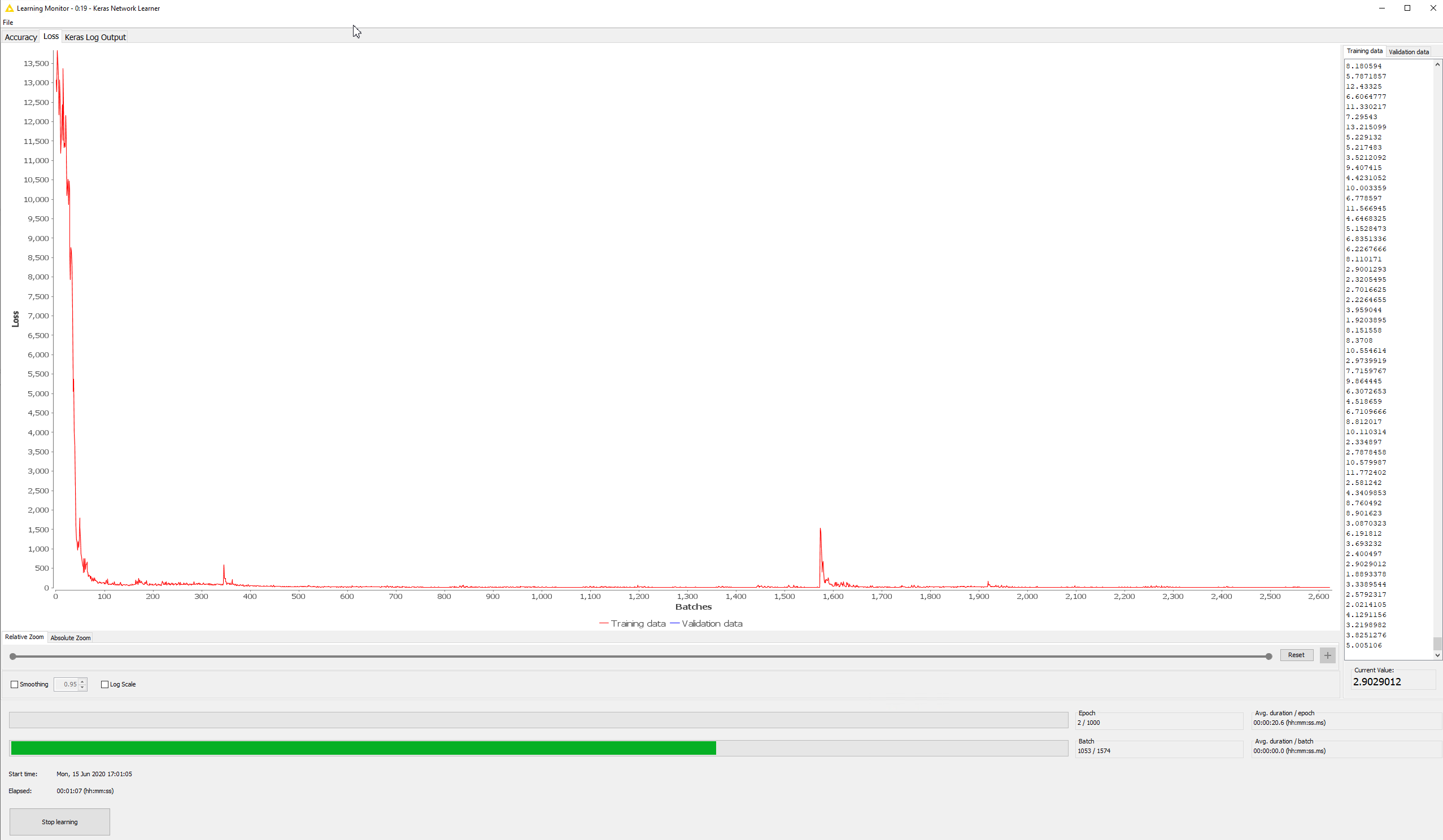
Any ideas on that?
Best
Niko
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.