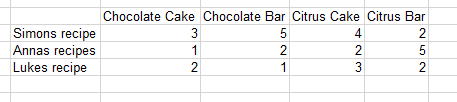I’m looking to create a table similar to this from using a bunch of PDFs and the co-occurence node (these are not exact keywords, just combinations, to be clear):
Where I manually input the keywords to look for co-occurences for. I.e. in the case above, I manually provided the flow with the words “cake, bar” in one column, and “chocolate, citrus” in another. In other words I don’t want to look for the co-occurence of “cake and bar”, but rather for “chocolate+ bar OR cake, and citrus + bar OR cake”. Hope this is somewhat comprehensive.
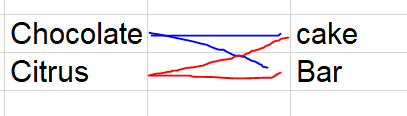
The relationship should be something like this:
Alternatively a matrix
Any ideas on how to create such flow? I cant seem to feed the co-occurnce with 2 columns to cross-check between …
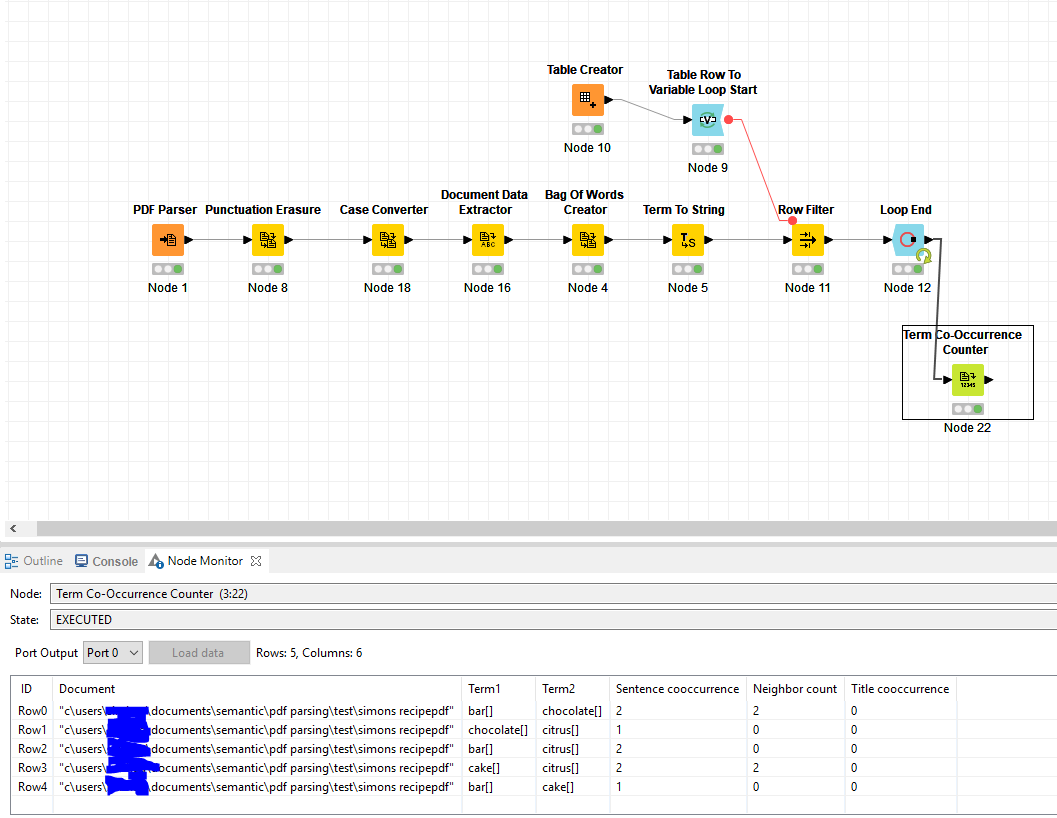
So I am able to get a co-occurence of specific keywords, but they all end up in one big bucket… for example:
Chocolate
Citrus
Cake
Bar
which gives me the output:
Chocolate Citrus - 1
Chocolate Cake - 1
Chocolate Bar - 1
Citrus Chocolate -1
Citrus Cake -1
Citrus Bar -1
Cake Bar - 1
What I want is to make sure that Chocolate and Citrus are not counted with one another … kinda like making 2 buckets where they just check against each other, and exclude words from the same bucket (see “bar cake” or “chocolate citrus”).
I would have suggested exactly the same like @iperez
Using this approach you only need to add the NGram Creator node (with N=2) in your preprocessing and then filter based on the table created by iperez workflow.
I think I might just be bad at explaining the problem (sorry, English is not my first language!). I am not looking to create NGrams, but rather I’m just trying to make sure that certain words are not counted as co-occured with one another …
Right now it mixes all my keywords with each other, but what I’m trying to do is make sure some words are not (in this case, “cake” and “bar” or “chocolate” and “vanilla”) because they just don’t make any sense to mix. My example is bad because “chocolate cake” happens to be an Ngram but it could be anything else, like the sentiment on wether or not something is good for example.
Imagine these sentences:
The chocolate cake is delicious, I really prefer them over a bar.
I really like chocolate - especially when it is cake.
I do not like citrus, but I love vanilla.
I prefer chocolate over anything else although I love cake.
I want to use the words “delicious” or “prefer” or “like” and similar to find their co-occurence with “chocolate” or “citrus” or “vanilla” to figure out what the author thinks of them. But I don’t want to check the co-occurence of “delicious, prefer and like” because they are not relevant when checked against each other.
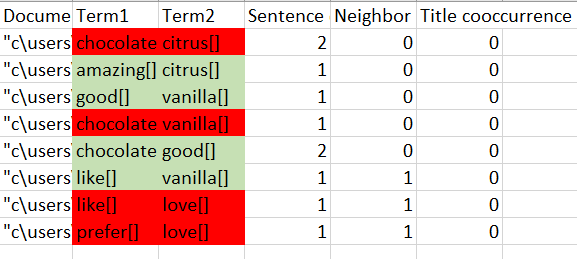
This is the output I get now:
Red = bad
Green = good
I don’t want the red results to show up at all, because again, they they dont make any sense. I want to ensure that the words “love” and “like” are not counted as a co-occurence, but “like” and “chocolate” or “love” and “chocolate” counts.
So to clarify: I don’t want to check the co-occurence of the words in column 1 in picture above, but rather the co-occurence of word 1 column 1 (delicious) with ALL the words in column 2 - then move on to word 2 in column 1 with all the words in column 2, etc, etc.
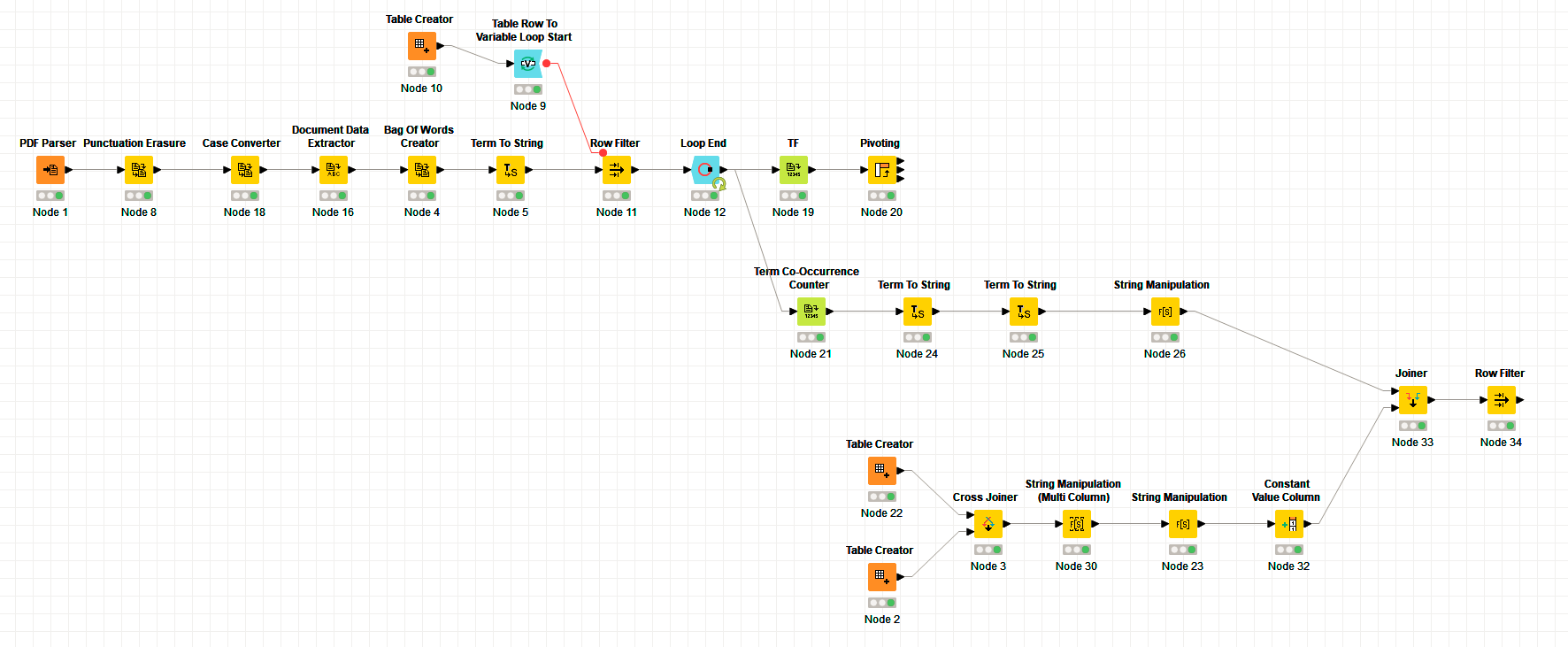
OK so building from this flow I’m trying to create a final step where it would extract the sentences of the co-occured match, so for example for the match "chocolate and “love” it would output the sentence for that match, like: “chocolate fondue is something I really love!”.
Any ideas on how to move in that direction? I’ve spent the last couple of hours trying to achieve this with the sentence extractor but it just parses every single sentence from the pdf files … =/
This workflow finds the sentences on which a couple of words appear. I’m a little bit confused about the previuos filters. Could you please restate the full problem?.