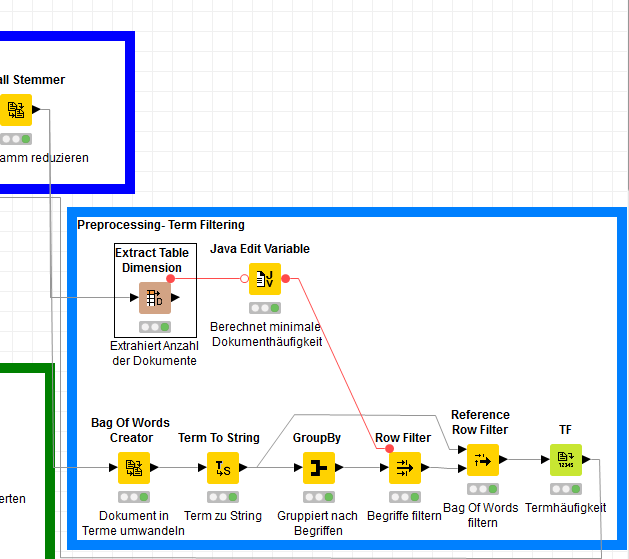
I have to classify texts … In order to minimize the dimension of my vector space, terms were conceived … Now I have the problem that my texts contain spelling mistakes and for example the words ‘proces’ and ‘process’ are not considered to be the same word. How can I handle such problems? Where would I have to build the node in my workflow.
there is no node that handles spelling mistakes. You can replace these words yourself e.g. using the Dict. Replacer node. But besides that there is no way to handle this. How many mistakes do you have? Is the a significantly large number?
If the number of miss-spelled terms is not significantly large I would simply ignore it. It takes a lot of effort to handle this by using dictionary based replacements.