Hi friends… I have a question want to test a file containing say 50 columns with different datatype such as string integer date and time and perform manipulation on each column according to its type… I have used a column lis loop but can anyone help me how to test the datatype for column inside this loop my dataset is around 50 million rows with 50 columns
Look if
works for you. Use second port output.
Hi izaychik63… Thanks for the reply…I dont want to convert one datatype to other…I want to segregate the mentioned above three datatypes and perform a different manipulation for each datatype … Can you please elaborate on the approach
Hi @ponting ,
I’m not sure I understand your problem
A) you know the correct (target) column types
You want to group the columns by type in order to perform different transformations on each group
- A.1) taking for granted that each value is correct, i.e. compliant with the column’s type
- A.2) checking the type of each value
B) you don’t know the column types and you want to set the correct type before performing step A
Thanks @duristef , Let me reframe in depth for you
I know the datatype of columns for my table ( A staging file having 50 million rows and 100 columns is, known to me … File is unique at id level)
… I need to perform the following task
a) If the column type is a date type… I need to calculate the fill rate for ids
b) if the column type is a dimension … I need to group by on this column and counts the ids
C) if the column type is a measure… I need to perform some aggregation say count sum based on requirements… .
I haved used a column list loop to iterate over one column at a time how to proceed further keeping in mind the volume of dataset is large…
@ponting the Column Filter nodes has a type selection. Would that help?
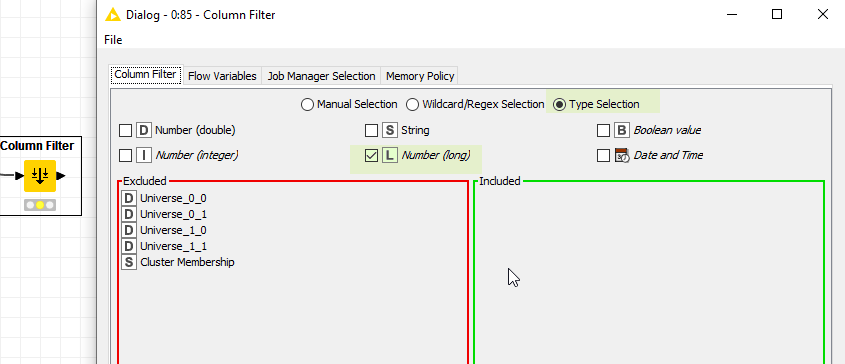
2 Likes
This is a partial solution, maybe it can help
KNIME_project.knwf (31.0 KB)
The data table has 5 columns: ID (string), int_1 (integer), int_2 (integer), string_1 (string), date_1 (date).
In the reference table of the “Reference Column Splitter” node I put the names of
(a) the columns of type int (int_1 and int_2)
(b) the columns I need in order to manipulate (a) (“ID”, since I want to group by ID)
In the loop, columns (a) are “included” (that is, they are available only in a single iteration), columns (b) are “excluded” (that is, they are available in any iteration)
The “Group By” node aggregates by ID the columns of type “integer”, resulting in a new column per iteration. The new column is added to the table
(I moved this to a new topic to keep the forum tidy, since this discussion was attached to a three year old thread.)
3 Likes
Hi @mlauber71 …Thanks for your efforts …If I use a column filter node based on type selection …I am not able to handle Date fields ( datatype for Date fields in my Dataset is Date cell and this type selection will filter values of Date & Time) …Are you aware of any conversion that converts Datecell to Date and Time format in type selection option of Column filter…All other Datatypes can be easily handled as per type selection suggested by you.
Hi @duristef …Thanks for the solution…I want to handle 50 million rows and 100 rows based on type which I think makes tedious for table creator to handle this data…Also it puts a restriction on manipulating data if exactly I use table creator approach…In a single loop can we perform the operation based on datatype for 100 columns
Hi @ponting ,
If you want to get the types of all columns, you can use the Extract Table Spec node:
This will give you all the columns of a table and their respective types.
EDIT: The Extract Table Spec is to help you determine what data type each column is.
For your complete issue, you may need to provide some sample data with their expected results for us to fully understand what you are trying to achieve.
First of all, it is not clear if all columns are of the same type or you can have different columns with different types, in which case, if you can’t do aggregation for all of the columns, then you will have more than 1 output in the end - aggregated outputs and non-aggregated outputs
3 Likes
Hi@bruno29a,
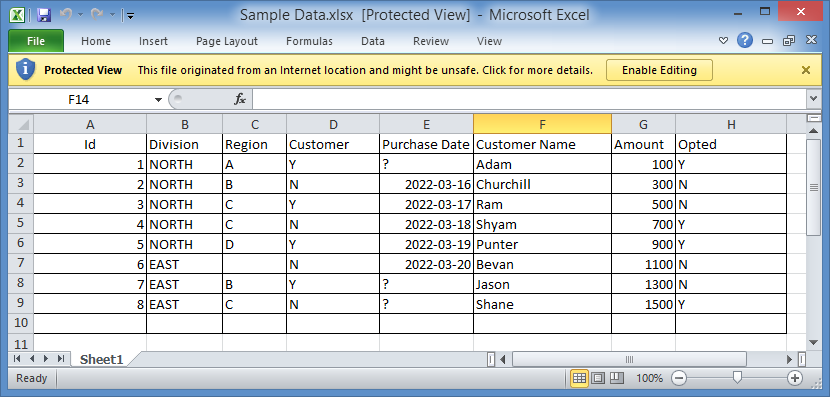
Thanks for your inputs…Here is the full ask with a sample data
I have attached a dummy Data …I want the output at level of column 1Xcolumn 2xcolumn 3
a) If the column type is a date type… I need to calculate the fill rate for ids
b) if the column type is a dimension … counts the ids
The flow needs to cater this need for 50 million rows and 100 columns.
Please let me know this data makes sense to you or not…
Sample Data.xlsx (9.0 KB)
Hi @ponting ,
It would have been more helpful to see what the expected results should be in order to understand how to present the result.
I have a few questions:
- What does “the fill rate for ids” mean?
- What is a column type “dimension”? Integers columns?
Hi @bruno29a ,
-
The date field is populated or not (for each id at division X region level)
-
I want to group by the categorical columns(non-numerical columns). (for each id at division X region level)
Please let me know if still it is not clear…The output level is shown below

Hi @ponting ,
I’m sorry, but I still do not understand…
Is this Output what’s expected for both requests? Where did the values Z, X, and Y come from in the output? I only see values A, B, C and D as Region in the sample.
If you want to group by non-numerical columns, are grouping them all at once, or each individually? The expected results is “counts the ids”, so I was expecting to see some counts, so numbers in a column.
So, I’m a bit confused about what you are looking for…
This is the file you shared:
As soon as you connect a date column type to the column filter (as suggested by @mlauber71 ) you can see the date in type selection
br
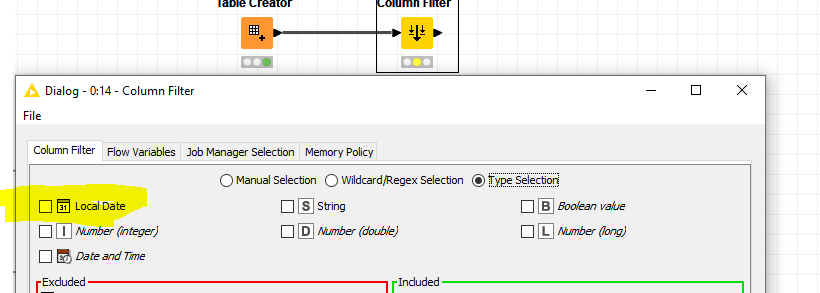
1 Like