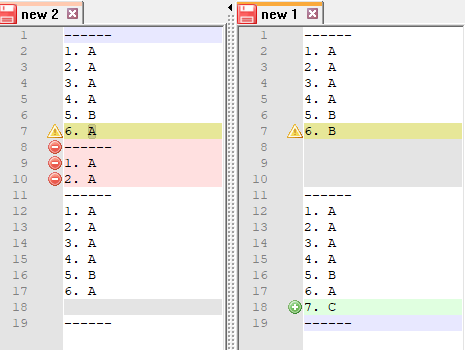
I would like to compare two “same” program code.
I would need a solution similar to Notepad++'s “Compare” solution.
The “Table Difference Finder” (TDF) provides a partial solution.
Because I need to search for line pairs (e.g. I insert a new line in the compared program code) - TDF does not track it.
I asked around a bit internally on this one. Although KNIME AP has a feature that allows you to compare workflows against one another in this way, there isn’t a node specifically for comparing external text files to each other like Notepad++ does.
I think your best bet here would be to implement this in a Python Script node.
You might also try calling Notepad++ directly from the command line using the Bash or External Tool nodes.
Hi @Miracolum , since @ScottF that there is no node that does this sort of comparison, you can try “comparing” 2 tables via an outer join.
The full outer join will show you what’s from the left table but not in the right table, and similarly what’s in the right table but not in the left table, and of course, will show you what’s in both tables.
This can be achieved via the Joiner node
This of course will not do a row by row comparison, but rather data comparison.
For row by row comparison, you will need to join on RowID, and then do comparison via Rule Engine
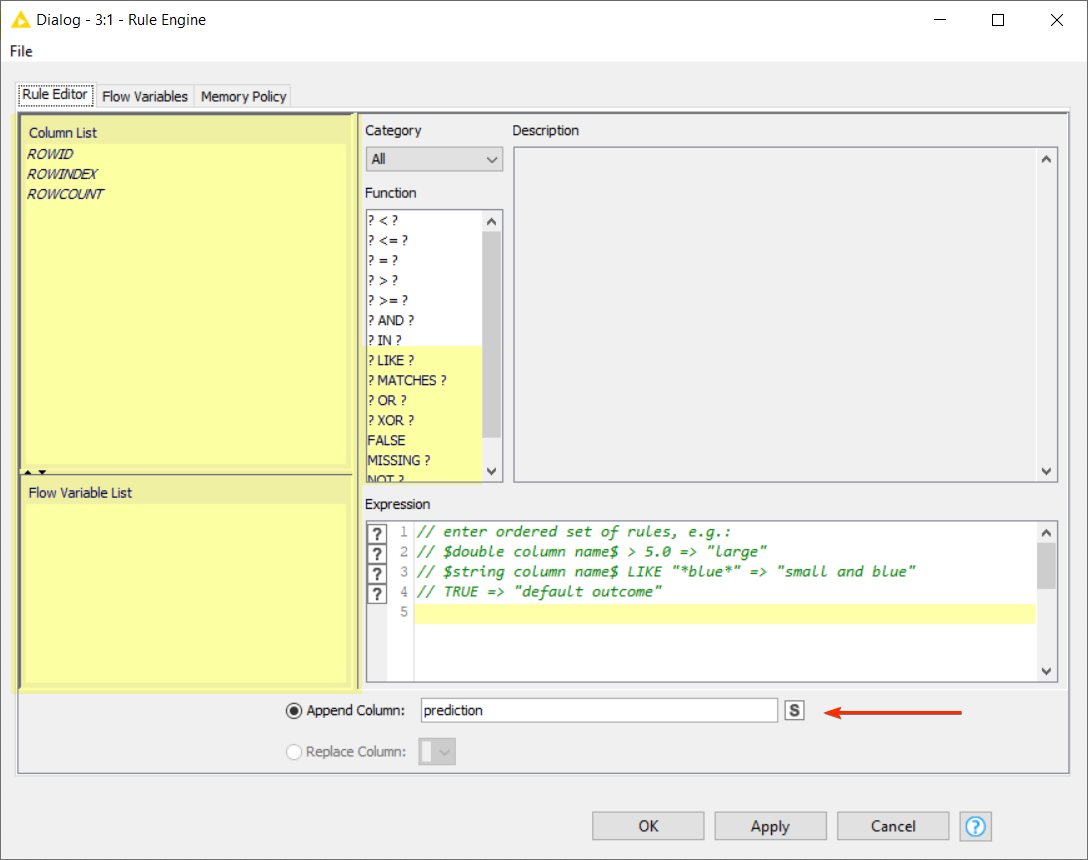
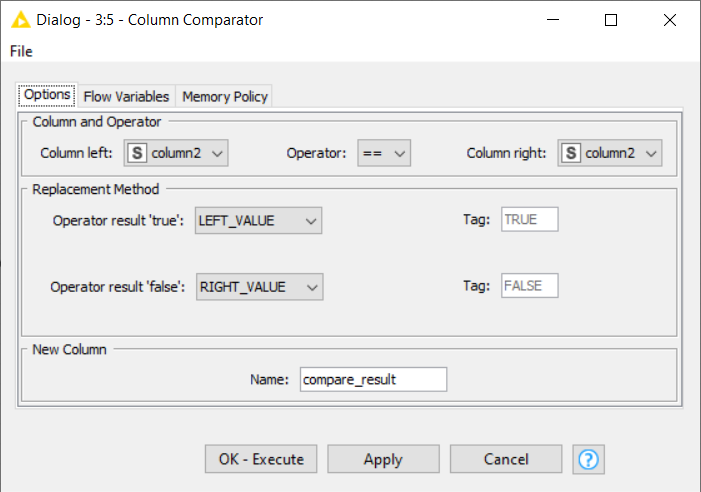
Maybe you can use Rules to compare line by line ou current line. The Rule note can be used from variables and have some compares:
“Like” or “Match” can solve your problem in this case… Like use ? and * to fill the data… Match use regular expression… so, maybe you can match and set some rules and after that, just use the rows filter/split to direct the action…, What do you think???
You can set a field as a flag to confirm or not the information and use it after, as you can see at the image above, there are some tips to use it, and you can use different kind of rules nodes (variables, table, predictor…), Tryout and tell us your results.
And use the flow variables tab to sed the right and the left data… A tip here is to use the chunk loop start, setting 1 to 1 row… so, you can pass all the table from both sides and check… There is a good pratice to order the text for both texts. If you’d like to find a term/variables to all column, use a loop settings to control it.
Hi @denisfi , I’m not sure why you’d want to use “LIKE” or “MATCHES” in the Rule Engine if you are doing an exact match comparison. I mean, why not use “=”?
There is also no need to do a Loop here. You can “force” the join to join line by line by joining on something like the RowID, or some auto incrementing value such as a counter via the Counter node. This will be much faster than doing 1 line at a time via a chunk loop
The result can be the same, you can just choise the best for you, i just give an example for others here that you can use extra resources if necessary… Thanks for your notes about it. The loop tip is to make a flag position if you’d like to search where the information gone at the end… 1 row, 2 rows… to the last row… you can check line by line if are your wish… just it…