I’m struggling to achieve something simple with knime and need help.
I have thousands of text files ( .r file extension ) that i need to parse to extract data from.to populate a a database.
I have figured out how to setup a loop using file list variables, and how to read files using different nodes.
It’s the parsing and text manipulation that bugs me. Which nodes should I be using to achieve it.
The file’s structure is as follows :
Every file is hundred of thousands of lines long and every item in the text file has around 50 rows I need to extract and transform in database columns,
Each item in the files have the following rows with field name and data :
RECORD #input_id 1595372832x003_001176 #output_id #input_type ggsnPDPRecord #output_type ggsnPDPRecord #addkey #source_id INJGGSN #filename GGSNPK5_20200720000113_56446
F RECORD_SEQUENCE_NUMBER 1
F recordType 19
F servedIMSI 546010100927694
B ggsnAddress
F iPBinV4Address CA57965A
.
F chargingID 3466766265
B sgsnAddress
F iPBinV4Address CA579681
.
F accessPointNameNI IM
F pdpType 0121
B servedPDPAddress
F iPBinV4Address 0ADA3760
.
F dynamicAddressFlag 255
B listOfTrafficVolumes
F qosNegotiated 0323931F9396789774810846
F dataVolumeGPRSUplink 221371
F dataVolumeGPRSDownlink 4899678
F changeCondition 2
F changeTime 2007192359442B1100
.
F recordOpeningTime 2007192358292B1100
F duration 75
F causeForRecClosing 16
F recordSequenceNumber 173
F nodeID GGSNPK5
F apnSelectionMode 0
F servedMSISDN 19687515603
F chargingCharacteristics 0400
F chChSelectionMode 0
F sgsnPLMNIdentifier 45F610
F servedIMEISV 3579521061955701
F rATType 1
F mSTimeZone 4400
F userLocationInformation 0145F610000A7B4B
F localSequenceNumber 832259057
.
What have you tried so far? Can you provide an example of the kind of text file you’re handling?
There is no standard approach to this. My most recent workflow that involved text parsing involved reading in a handful of output files, each of which had on average 220k rows, and was divided into individual records spanning hundreds of rows.
The first task was to get rows for each record. My approach was to:
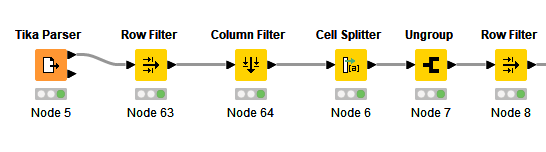
Start with a Tika Parser node which read in all the files I needed to process
Use a row filter node to select the content of the individual file I wanted to process. I could have set up a loop to process all the files sequentially, but I didn’t bother.
Use a Cell Splitter node to split the file into individual records, based on whatever string of characters delineates individual records. In my case it was " **** MOLECULE: ****"; in your case it might be “RECORD”. I made sure that the output of this node was a list.
Ungroup to obtain individual rows, one for each record.
Use a row filter node to remove the header section of the file, which contained information that I didn’t need
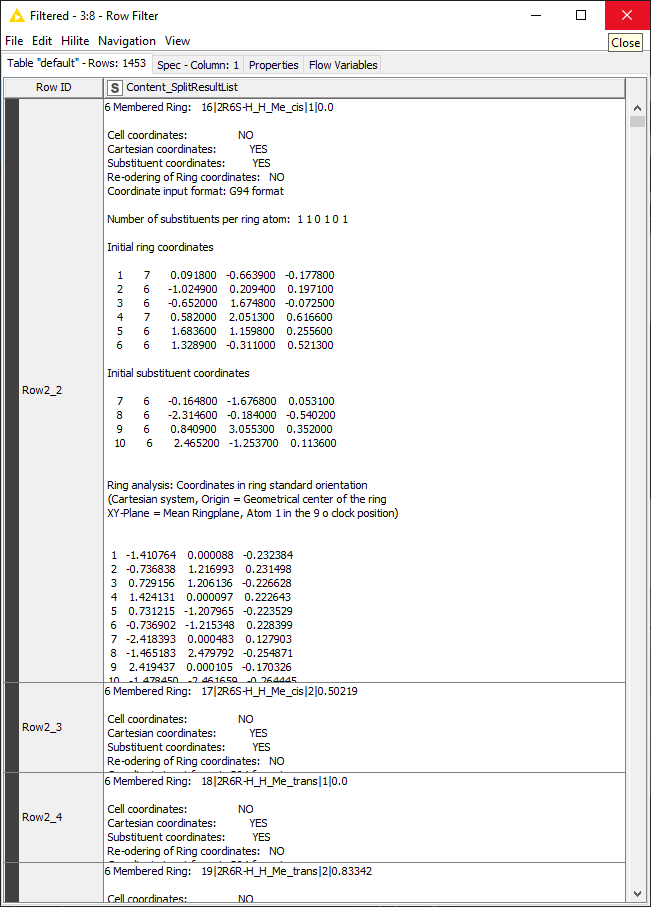
The incoming text file was split into 1453 records, each in its own row, and each cell now has about 350 lines of text in it. The next task it to sift through that text to extract the information I want. I used a series of cell splitter, row splitter, and filter nodes (inside of a metanode to keep things need) to whittle things down:
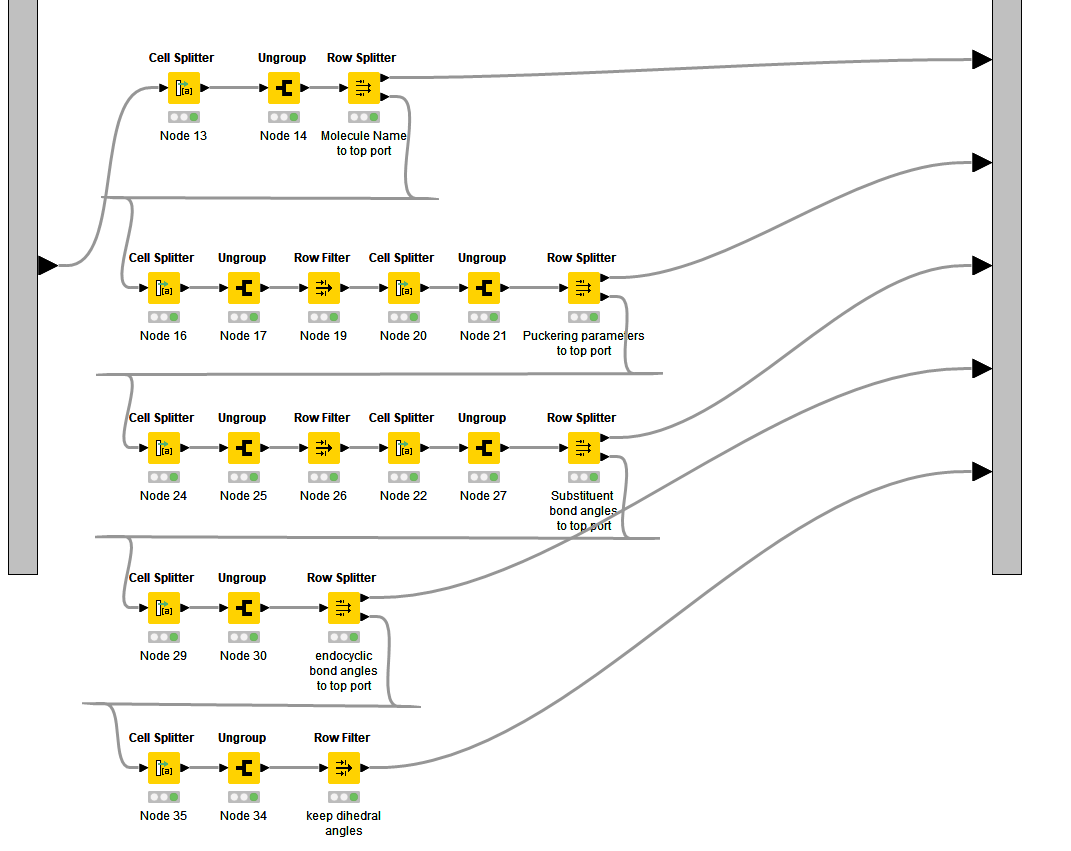
You’ll need to identify the unique text that marks the data you want to extract, and use the appropriate splitter to isolate them as individual rows. In my case, I had unique subsections that I was after.
Each of the metanodes in the image below consists of a series of splitter nodes that isolates the data in subsections I need as individual rows, then as columns.
Thank you very much for taking the time to answer this topic.
I should say that i have some experience using KNIME from another project i made parsing XML files, which was really easy with Xpath node, i could isolate each XML item to create corresponding columns.
For this case, I have tried using Tika parser but it seems it does not support or recognise the files i’m feeding it. they are “.r” format text files. I can’t manually change the extension of the files since it is supposed to be an automated task that runs contineously when new files are generated.
I have uploaded a file sample here, that i changed to .txt because the website would not accept the original extension as well and only kept the first 1800 rows. sample.txt (40.5 KB)
I have managed to read the files using flat file document parser node, or line reader node.
Now, I will toroughly try to understand what you have done in your project and try to adapt it to mine as much as possible, and hope it all becomes clear.
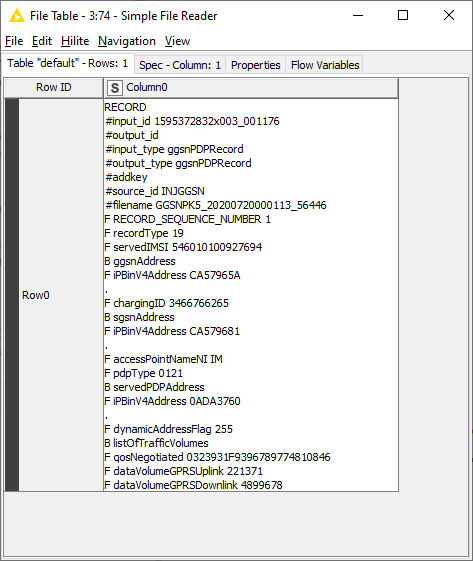
If you use the Simple File reader with (for example) a comma as the row delimiter, you’ll get the entire .r file in one cell, since there are no commas in the file:
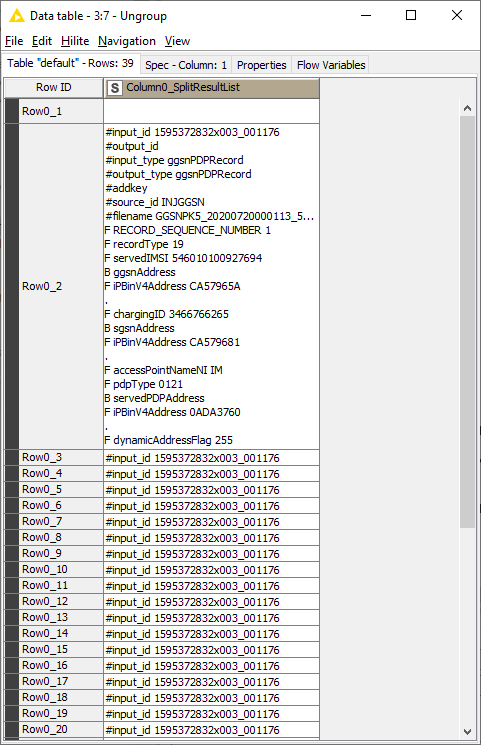
From there, the cell splitter node can separate out the individual records if you use RECORD\n as the delimiter (this is just the word RECORD in all caps followed by the new line character) and choose “As list” as the output. Ungrouping gives each record in its own row:
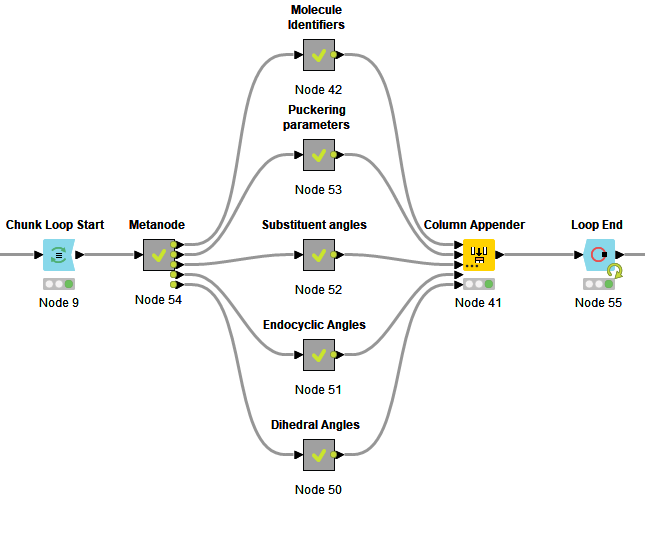
Filter out the first row since it’s empty. Then you can use a Chunk Loop start to operate on each row in succession and extract the individual fields with more Cell Splitter, Ungroup, Row Filter nodes, and whatever else is necessary.
The files are read in completely, each row one file, and then divided into the individual RECORDS. Each line one RECORD.
The RECORDS are then divided into the individual items. Each line one item.
The original RECORD RowID is used as selection criterion for the groupwise processing of the datasets.
Finally, the column names are created from the FieldNames and each RECORD data is transferred into a row, together with the original file name.
If the memory is not sufficient, the files can be processed individually by using an additional chunk loop.