My input data (big text) for each feature is distributed among multiple columns. X1 X2 … X10. All this data belong to the same feature X. Is there a way to concatenate these in one column before training? I have few features like this in the same input excel sheet. The input is in .CSV format.
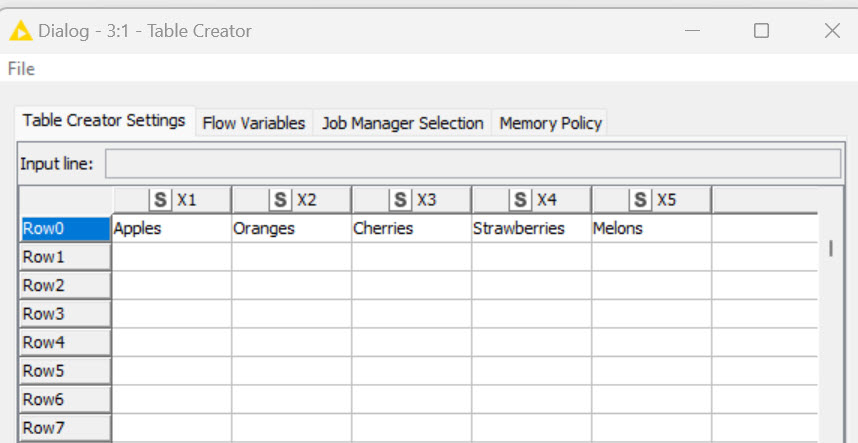
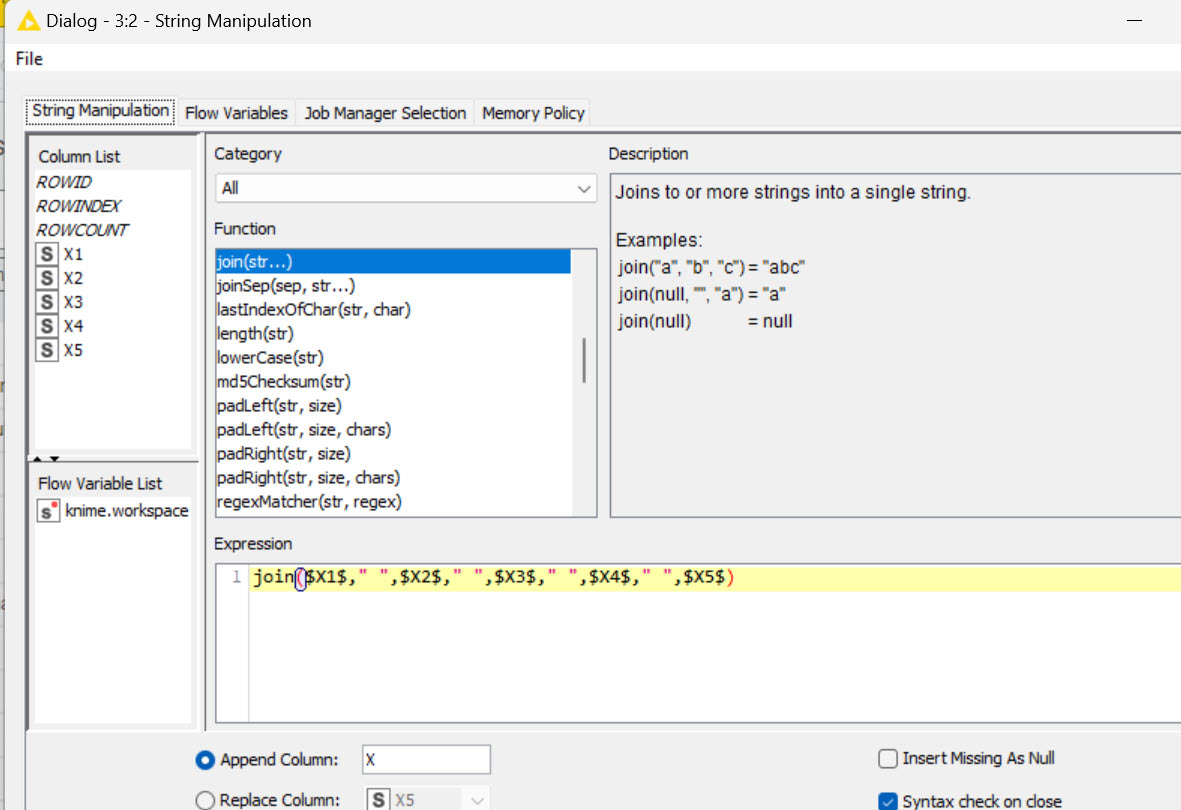
Thank you, Mr. Feigel. My dataset is very large and I would like to have an easier way to take that input data and concatenate the cells in one new column (with one different name). I do have multiple of these in this dataset.:
X1 X2 … X10 ==> X
Y1 Y2 … Y5 ==> Y
and so on…I would appreciate any help.
How is the data structured? If you have different Xs, Ys, etc what are the column headers? Could you post some sample data?
Hi @haniassi,
I created a demo workflow which you could try out. It is based on the idea that the first letter of each column header defines the group. A1, A2, A3, … , A10 > Group A
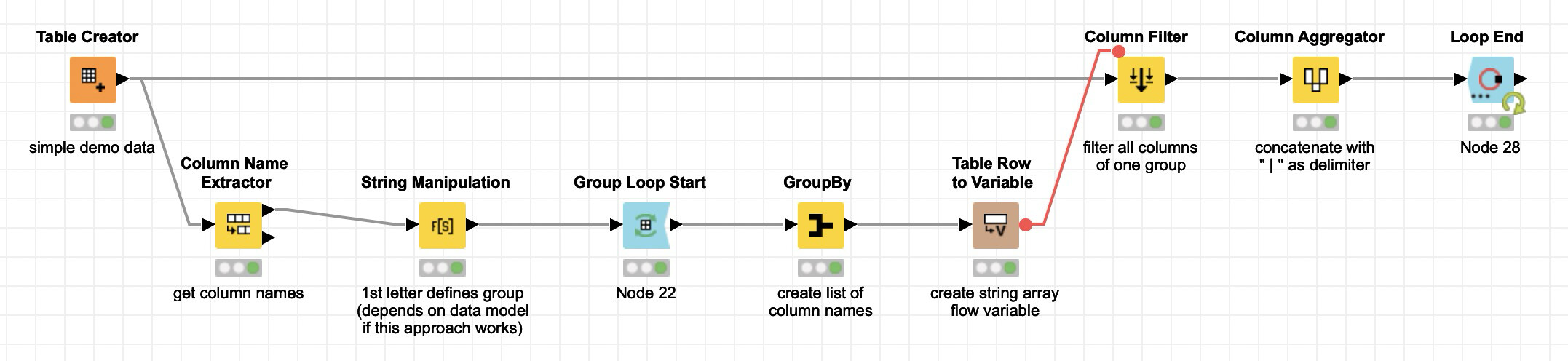
All members of the group get concatenated using the Column Aggregator node. The loop iterates over all existing groups.
Here is the link to the workflow. Please let me know if this was helpful.
2 Likes
Thank you JLD. Appreciate your time. I am trying to avoid creating a table from scratch. Want to start from a CSV file I have already. Any pointers would be great.
Alternatively, if there is a solution to overcome the limitation of the number of characters in an Excel cell that would solve my problem as well (I don’t have to use X1 X2…).
Why can’t you feed your csv file into @JLD’s workflow replacing the table creator which he’s using since he doesn’t have your data? Also, what’s the original format of your data, i.e, txt, a database, etc.? If you could give us a more complete description of what you’re doing it would help.
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.