Dear Knime community,
first of all it’s really amazing to have this very vivid and supportive community and I hope you can help me with my case.
For my Master Thesis, I want to research the differences of company values between family and non-family firms. Therefore, I would like to conduct a Text Mining task on the company’s annual reports (in PDF format) in which you usually find the company’s values and beliefs.
So as an outcome, I would like to generate a list of words/terms that represent the most stated values for each, a family and non-family firm.
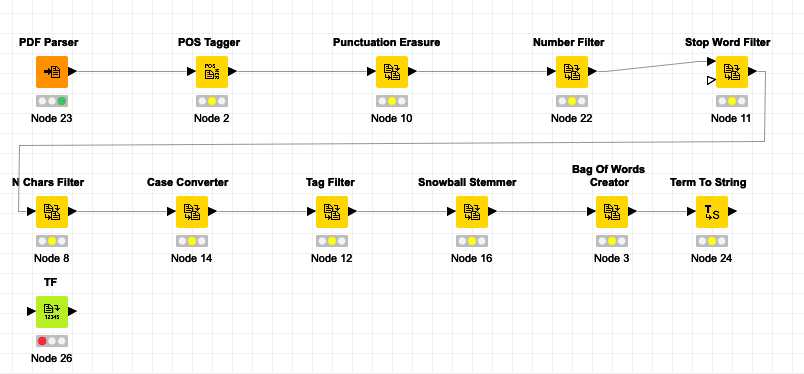
I’ve already started working on a workflow which you can find attached. However, I do need your help for a couple of points to make it as good as possible:
-
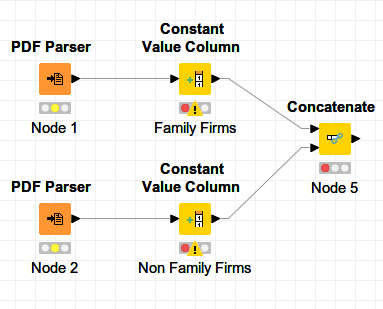
I didn’t find a way how to separate the analysis for family firms vs. non-family firms. Should I feed in the annual reports via 2 separate PDF Parser or is there any way to split up the documents depending on family firm / non-family firm? Right now, I have all the documents in one column, so it’s not possible for me to separate between the organization forms.
-
Based upon my first question: Is there any tool to analyze/compare the outcomes of family firms/ non-family firms?
-
Is there any tool to additionally filter the terms in such a way, that there will be only company values generated such as diversity, team-orientation, respect, collaboration and so on?
-
Do you have any other analyses in mind how to draw some more findings/insights out of it? For example, would it make sense to do a sentiment analysis?
Sorry for so many questions at once but I’m new to Knime and not aware of the endless opportunities this program offers.
Your support would be highly appreciated!!
Cheers,
Christopher