Hi All,
I have the following Problem, that i need to solve:
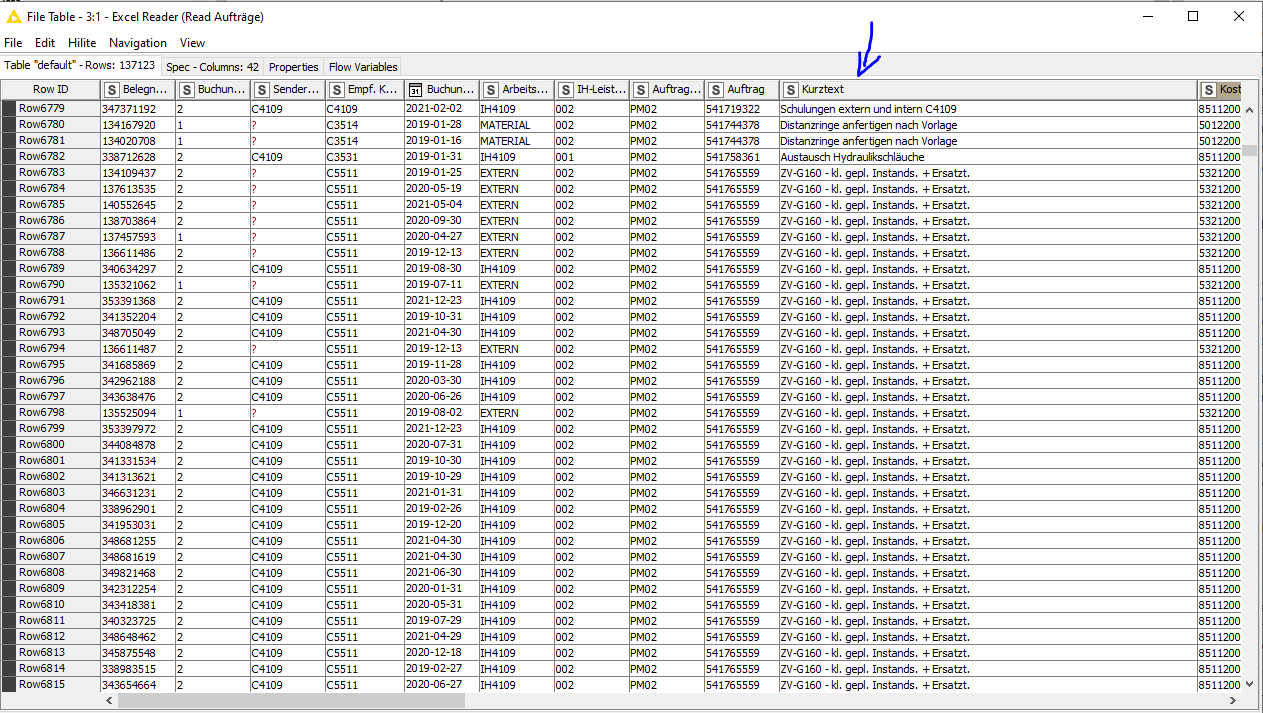
it is necessary to know the machine components that have been worked on. Therefore, we get the components from short text description.
Write an algorithm that analyses column Short text and identifies the components contained there and then writes them to a separate column.
It’s a bit unclear (to me at least) what you’re trying to do. (And despite working for KNIME, I don’t speak German, so that’s another complication )
Do you want to build a supervised model to identify the components? If so, what is your target variable? Or are you wanting to do some clustering or something else? Based on the screenshot above, all I see is some preprocessing of the text, but not much hint of the actual analysis you hope to do.
Uploading your actual workflow in progress (with dummy data, if necessary) would help us help you, so to speak.
The column “Kurztext” contain Component that have been worked on. This Component needs to be identified
For example in the picture from Row 6780 i need to extract “Distanzring” in english (Spacer ring) or Row 6782 “hydraulikschläuche” In english (hydraulic hoses)
What i´m trying to do is to build a model to identify the Component from the text and write them in a new Column
Thanks for uploading your workflow. Since it doesn’t also have the data, I can’t see configurations or intermediate results, but based on the nodes you have available I can’t tell how you plan to identify the components.
In short, how can the workflow extract names of the components if you haven’t provided that information via a lookup table, target variable, or something else? Tagging parts of speech is not likely to get you there all the way.
Do you have a lookup table of typical components that you could use in conjunction with the Dictionary Tagger ?
@samihabid as @ScottF has said: you might have to provide us with more background information. Do you have a list of possible terms that you would want to check. Are the text fields created manually (so we would have to look for typos etc.) or automatically. Also providing some data that would represent your challenge without spelling any secrets might help.
One idea could be to identify ‘rare’ terms like the opposite of extracting topics - terms that are not additional text - if you do not have a reference list. I do not have an example for that instantly.
Would the results be reviewed by someone. You might be able to build a reference list over time.
In the meantime I can offer this collection about KNIME and text analysis: