Happy New Year KNIMErs!
I am moving into processing text entries in our OIS (MOSAIQ). Many moons ago I tried to get our dietitians to enter their assessments into pre-formatted assessments but they resisted and continued to enter their dietary assessment as free, though partially formatted, text. I am looking to extract this data and analyse.
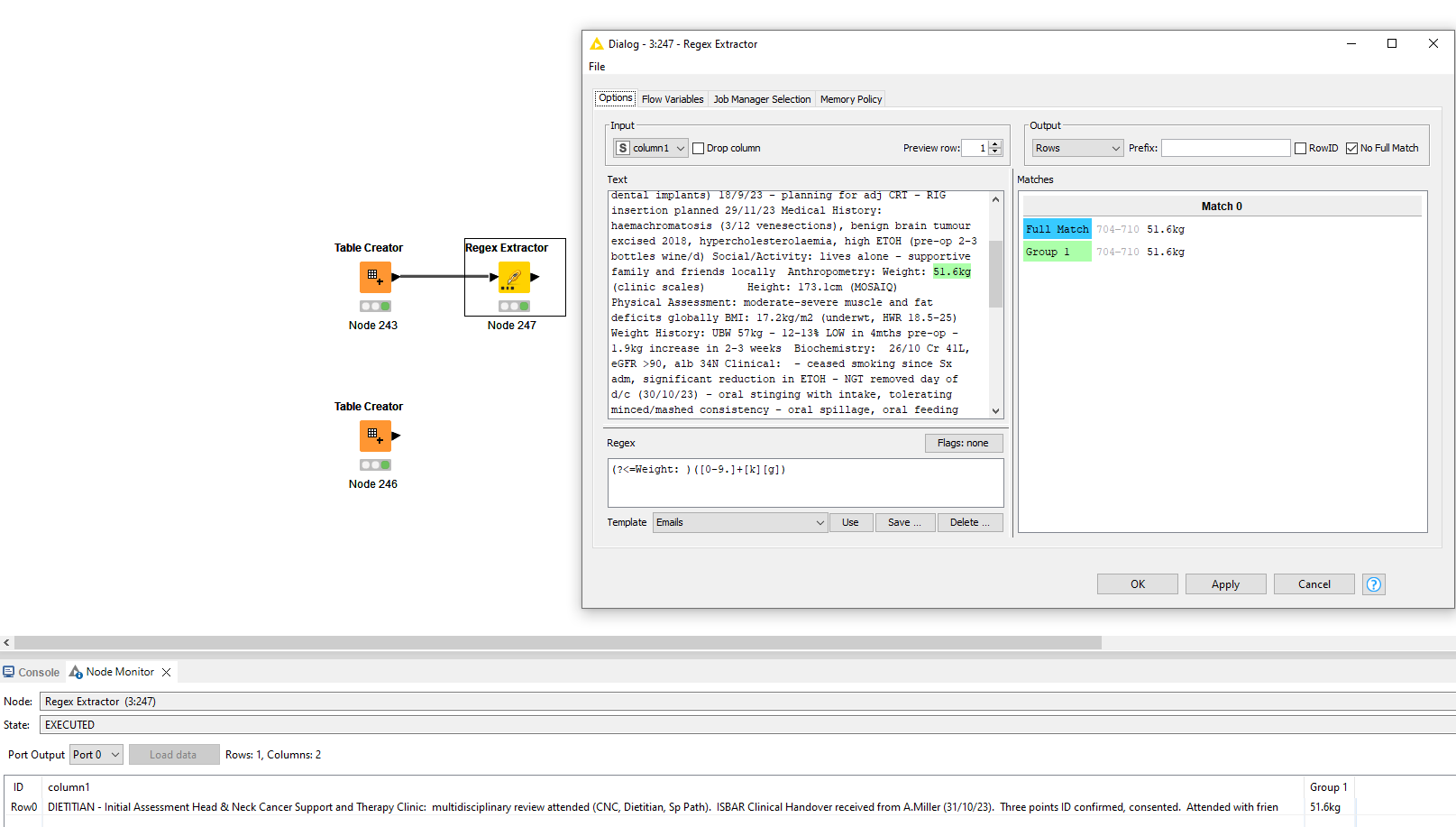
I have pulled all of the Notes which contain the text “DIETITAN - Initial Assessment” into a table which includes Pat_ID1 (patient identifier), Notes (the entered text) and Create_DtTm (Date of Note Creation). The text below is a typical free text entry. It is all deidentified.
DIETITIAN - Initial Assessment
Head & Neck Cancer Support and Therapy Clinic: multidisciplinary review attended (CNC, Dietitian, Sp Path). ISBAR Clinical Handover received from A.Miller (31/10/23). Three points ID confirmed, consented. Attended with friend.
Dx: FOM SCC pT4aN1M0
Treatment: ant segmental mandibulectomy + bilateral ND + free flap recon (R fibular donor site, dental implants) 18/9/23
- planning for adj CRT
- RIG insertion planned 29/11/23
Medical History: haemachromatosis (3/12 venesections), benign brain tumour excised 2018, hypercholesterolaemia, high ETOH (pre-op 2-3 bottles wine/d)
Social/Activity: lives alone - supportive family and friends locally
Anthropometry:
Weight: 51.6kg (clinic scales)
Height: 173.1cm (MOSAIQ)
Physical Assessment: moderate-severe muscle and fat deficits globally
BMI: 17.2kg/m2 (underwt, HWR 18.5-25)
Weight History: UBW 57kg - 12-13% LOW in 4mths pre-op
- 1.9kg increase in 2-3 weeks
Biochemistry: 26/10 Cr 41L, eGFR >90, alb 34N
Clinical:
- ceased smoking since Sx adm, significant reduction in ETOH
- NGT removed day of d/c (30/10/23)
- oral stinging with intake, tolerating minced/mashed consistency
- oral spillage, oral feeding slow
- good appetite
Estimated Nutrition requirements (51.6kg)
Energy: 1290-1550kcals/d (25-30kcals/kg) maintenance + 500kcals/d wt gain allowance = 1790-2050kcals/d
Protein: 60-65g/day (1.2g/kg)
Fluid: 1800mL/day (35ml/kg)
Diet:
- texture: minced/mashed diet, thin fluids
- supplementation: 5x200ml Ensure TwoCalHN (84g protein, 2000kcals, 705mls fluid)
- intake: 3 small meals - combined diet and supplementation providing ~120g protein, ~2500-2600kcals
- fluid: ~1900mls/d
Assessment:
PG-SGA = B13
Moderately MALNOURISHED but demonstrating clinical improvement as evidenced by
- wt gain in 2 weeks on background of severe LOW (remains underwt BMI)
- tolerating adequate intake orally with substantial contribution from ONS
- meeting wt gain allowance
Negotiated Goal/s:
- continue supplementation to facilitate wt gain
Recommendations:
1. continue HPHE minced/mashed diet
2. 3-5 x 200ml Ensure TwoCalHN
- encouraged to titrate volume according to diet tolerance / avoid displacing diet intake by satiating with ONS
Plan: RIG education post SIM
Contact 555-555-555
I wish to be able to do two things:
- extract relevant variables, such as:
Weight: 51.6kg (clinic scales)
To get a feel for the process, I wish to do something simple (for you, hard for me!):
a. find the text “Weight:” inside Notes [I can do this already]
b. extract the following text up to and including the letters “kg”
c. export the text " 51.6kg" into a column named Weight
d. have an associated column for Create_DtTm
- substitute text
For example, expand ‘underwt’ into ‘underweight’