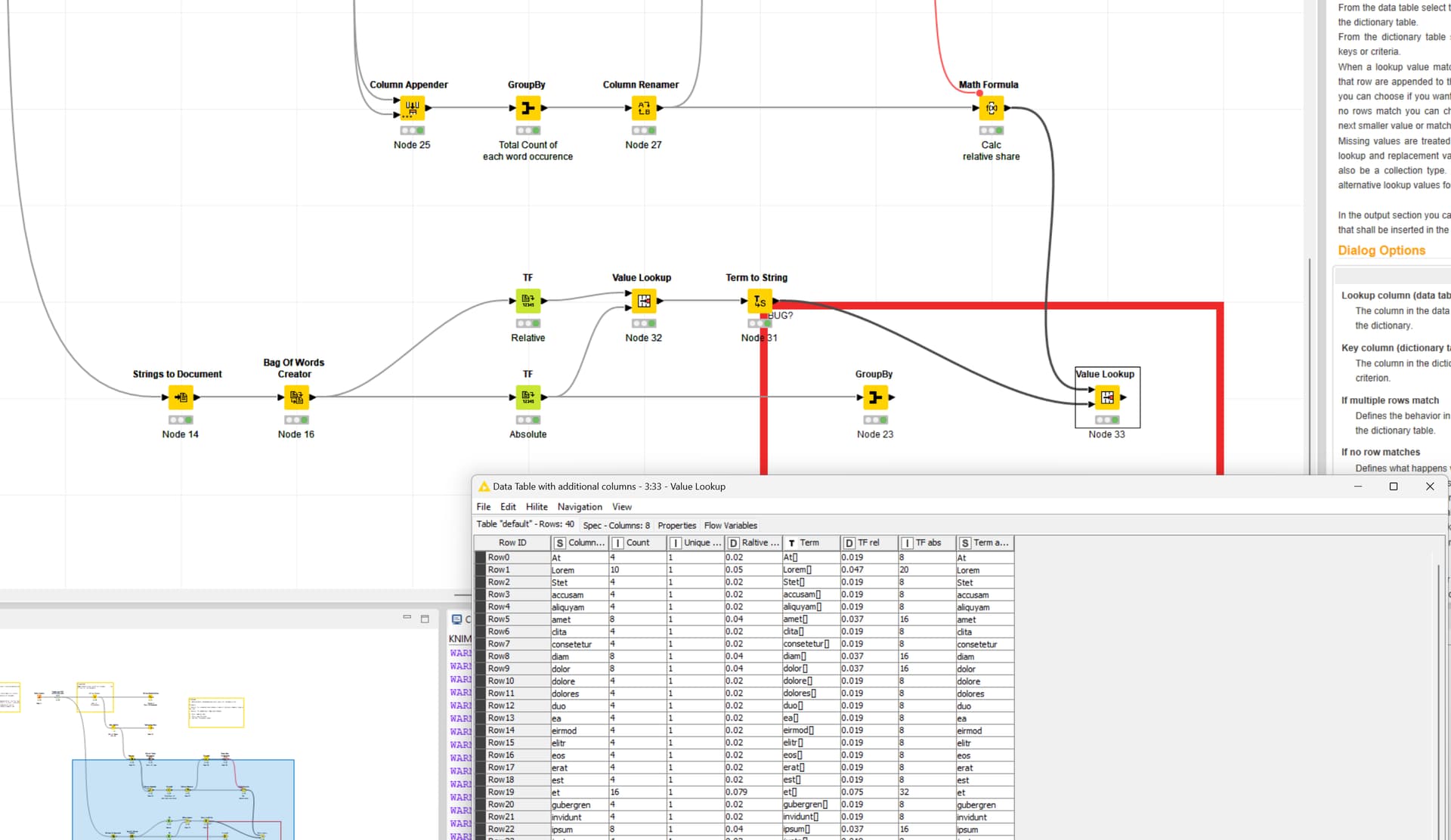
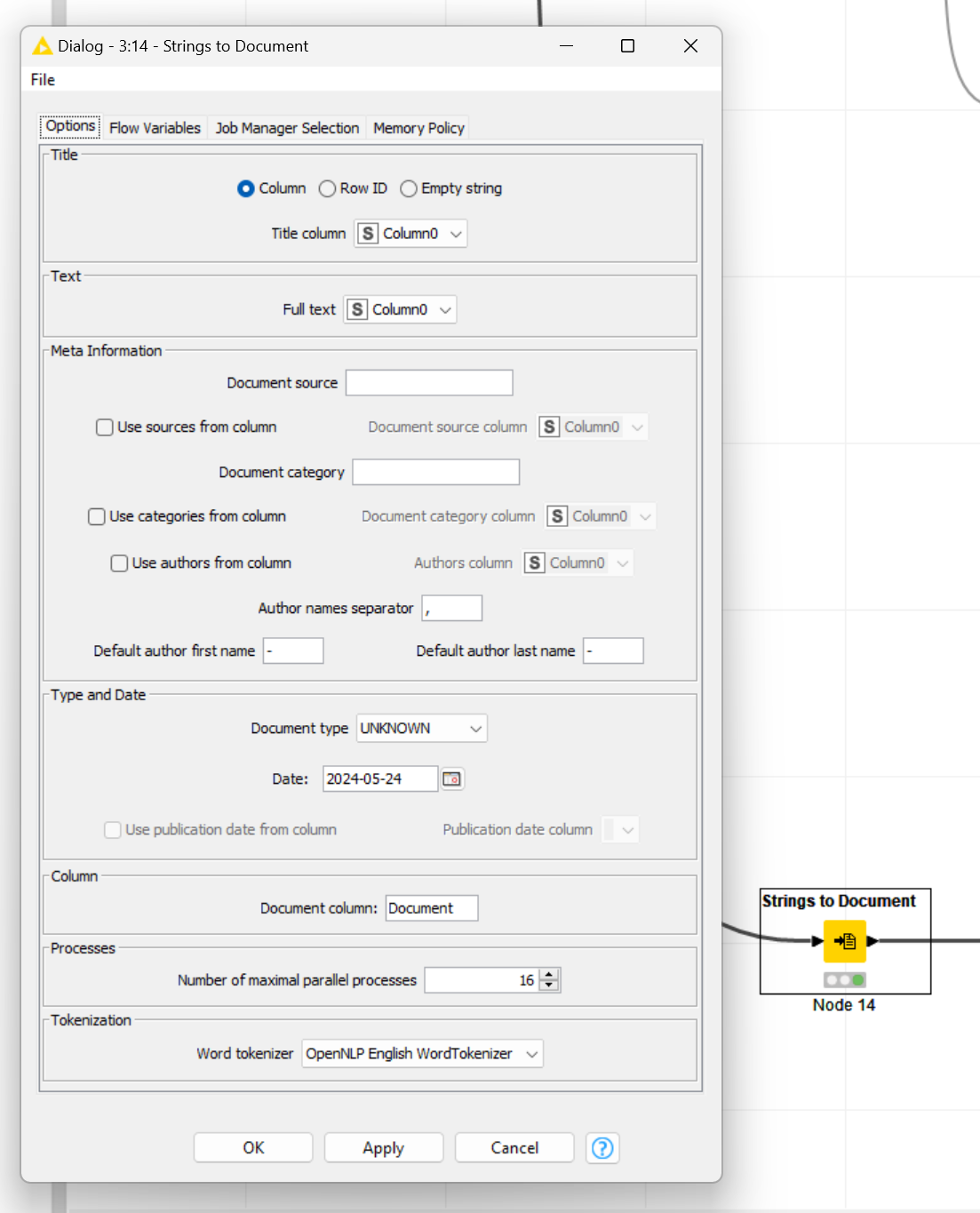
You’ve likely assigned the same column to both ‘Title’ and ‘Full Text’ column in the Strings to Document node, The TF node counts words in both these fields. To double check, use the Document Viewer node.
To fix this, either create an empty column named “fulltext” and assign it to Full Text in the Strings to Document node. Or, use the Math node to divide the term frequency by 2.
Computes the relative term frequency (tf) of each term according to each document and adds
Apparently the title belongs to the document so maybe a good compromise is to add the ability in the TF node to select to count the whole document or aspects of it:
Title
Text
Meta: Whole, Source, Categories, Authors
Interestingly, the meta information is not taken into account by the TF node currently.
I updated the test workflow for reference in case anyone stumbles across that subject.