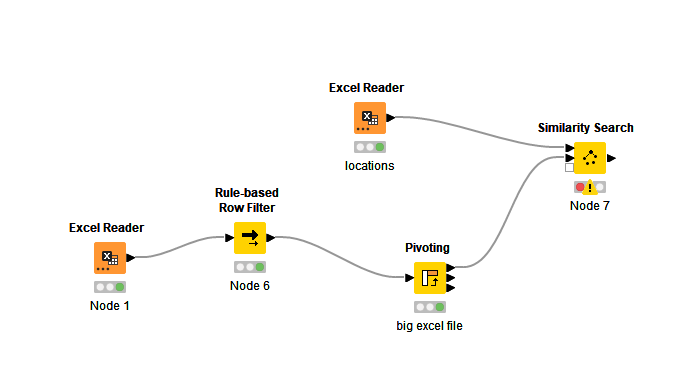
I am trying to solve a data-clearing issue using text similarity node. Let me define my problem first, I have a list of locations (correct names); in another file, I have different columns, including the location, but the values are misspelt, and my problem is to replace the wrong values.
The workflow looks like:
Now the problem is : when I am trying to configure the text similarity node (using Levenshtein), the list of columns is empty (none of the columns from the locations are shown).
I can’t tell from your image if you already have the vectors inside to compare. Maybe this link to the hub will help you. If you can’t use directly you can pick pieces out of it. Another option is to use the string matcher node.
Besides Palladian comes with the handy String Similarity Node that calculates various string similarity metrics between two strings, like n-gram overlap, Levenshtein, and Jaro-Winkler. Just string/text in and a similarity score out.
Palladian can be downloaded from this update site: https://download.nodepit.com/4.7
Example workflows and discussions are linked on NodePit.