My goal is almost the same as the creator of the post, but once I try to apply my files I get the error in the title that the “Argument Contains Duplicates”. Does anyone know why or how to fix it?
I’ve tried so hard to figure out a solution but I can’t find it (I have little experience I premise)
Thank you very much in advance to everyone for your help!
I have downloaded the workflow you posted (actually the same as I posted as solution in the mentioned thread) but it doesn’t have your data associated to it. Could you please upload your Excel files here too so that we can check what is not working ?
Hi @aworker , I think there wasn’t a better person who could answer me
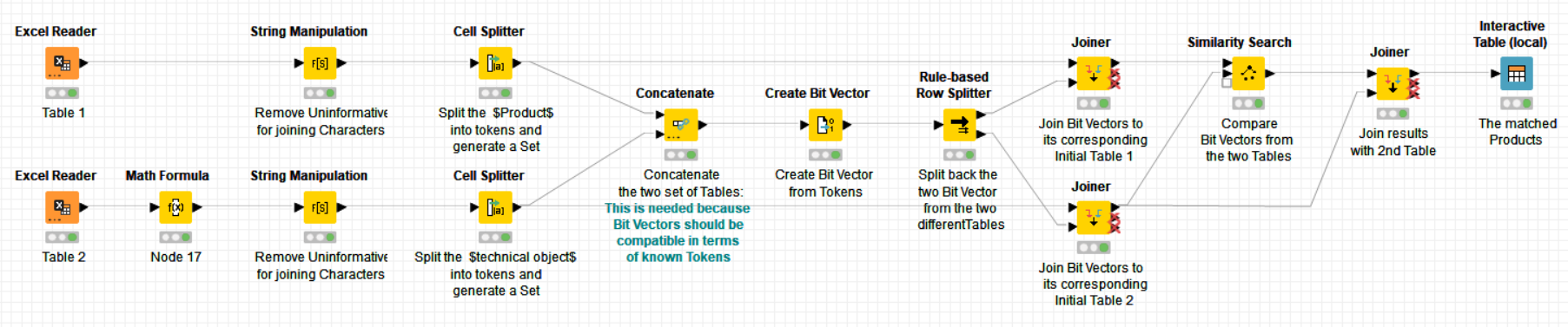
I attached basically your same workflow because I tested some variations but without success and your one is still in m opionion the closest to the result.
They are very similar btw each others but now I’m going to tried to expain you the situation:
I have two retailers which have several product with different specs (brand, name, pack);
Some of them are shared across the retailers but maybe with slight differences.
My goal is to merge all the specs (column “unire”) and be able to run a Text Similarity to identify the “common” products. The perfect output should be to be able to set an x value as threshold and to return a final table with the name of both “similar” products with theri relative score.
I believe the difficulty was that the products didn’t have a column of associated unique identifiers to be able to achieve the last -Joiner- node matching.
However, I would like to ask you a question, how does this similarity work if you know?
Having like 10 elements I would have expected to find an exponential number of results because every value in one table was compared to every value in the other table however it seems to me that this is not the case…
Can you help me understand this situation and if so how would I go about getting “exponential similarity”?
I hope to have given you enough information. if not I am always available to talk about it!
Thank you very much in advance to everyone for your help!
I’m answering quickly but shortly because already out of office and hence answering from the mobile phone.
The -Similarity Search- node has mainly two options to control the number of pairs of matches returned at the end. One is the maximum number of returned pairs of matches w.r.t. each reference table row and the second is the maximum allowed distance. When sat, these two thresholds control the final number of total matched pairs.
Hope it answers your question.Otherwise please reach out again.
Hi @aworker ,
I am finally back in the office after vacation and first of all thank you very much for your reply.
I didn’t understand too much about the two options for pair number control…
What I would need is to have all the possible pairing options, how would you recommend I do that?
In addition I see you know a lot about this, do you happen to know if you can do the analysis even to more than two “datasets”? For example with three/four starting columns (to make you understand the flow example above is at two)
How would you deal with this problem?
Thank you very much in advance to everyone for your help!
“All options” depends on the distance threshold you set I suppose. If you want everything with everything do a crossjoin but I do not see any value in that for similarity matching
br