The cell appears to be empty, but a filter does not recognize it as either an empty or missing value.
The cell appears to be empty, but a filter does not recognize it as either an empty or missing value
Hi @Istvn_Fazekas , Welcome to the KNIME forum.
Can you add a little more information to make it easier for people to assist, please.
e.g.
Which filter node are you using?
What data type is the column containing the cell?
What does your data actually look like?
What does you config look like?
and anything else you can add.
Posting a sample demo workflow containing sample data that demonstrates the problem is always most likely to get you to a solution faster. thanks
2 Likes
I usually start by checking to see if it is just a single space character, then copying and pasting the contents of the offending cell into a hidden character viewer like this…
2 Likes
Hi @Istvn_Fazekas ,
what do you see in the output of the String Format Manager – KNIME Community Hub , if you check the “Show line break and carriage return as symbols” and “Show other non-printable characters as symbols” settings?
2 Likes
Thank you for the helpful comments. In the meantime, I managed to solve the problem based on the descriptions I read on the Hub. I traced back to where the “it looks like the cell is empty” phenomenon was appearing. The input text (.txt and .pdf) already contained double spaces, which were then passed on by the process. The String Cleaner node helped (Remove duplicate whitspace).
I have been using the KNIME framework for a relatively long time. But I mostly use it only to solve emerging challenges, not continuously. The problem arose during a report creation, where I had to create a summary (report) from several - mainly text - input files. I would like to insert the appropriate values based on the keywords into a table in the target document (.docx). I have reached a state (output) that provides appropriate content for manual creation of the report, but I cannot implement full automation.
Since the community is so helpful, I will describe the essence of the project in a few words:
input files (.txt/udf, .pdf) → reading files → extracting file content (text) → splitting content into lines to make it searchable → searching in the file lines based on keywords ->…
Here I am now.
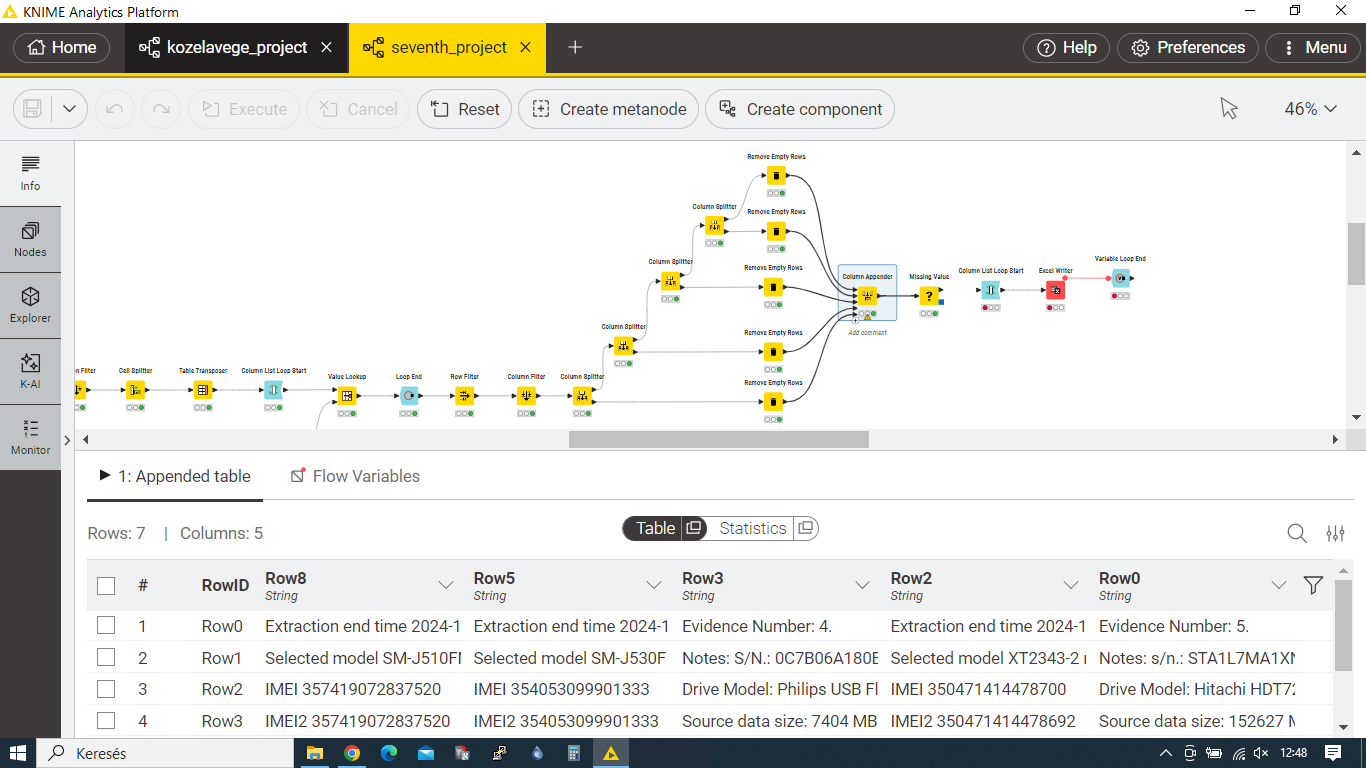
All my files are divided into lines (one line: expression + value) in one column. The column headers are the file names (‘something’ and ‘something ()’ ). I need to solve this so that I can transfer adjacent columns () in pairs to a separate table. So in the end I will have a number of separate tables equal to half the number of columns in the original table. The problem is how to extract the columns in pairs into separate tables. The situation is complicated by the fact that the number of input files varies. Thus, in the state before splitting into Tables, the number of columns also varies (but is always even).

Is there an experienced KNIME user who has experience or ideas on how to automatically generate tables (standalone, separately manageable tables) with one of the nodes, even with a loop solution? My solution currently has quite a few limitations in terms of flexibly tracking changes in input data (files).
Hi @Istvn_Fazekas , welcome to the KNIME forum.
Are all these questions related, or different topics? I’m having difficulty following the thread. If they’re different we’ll get them split out into separate threads with their own titles, because otherwise it can get really confusing. And is there any reason for it having the “bug” tag, as I cannot see anything in what you’ve written that suggests a bug.
Generally it’s easier for people to help you if you can upload some sample data and ideally a sample workflow that demonstrates what you have done/are trying to do, so people can more easily understand and assist. ![]()
1 Like
These belong to the same topic. I put it in the “bug” topic because of a problem experienced in this workflow (empty cells that have no visible value, but cannot be deleted with the ‘delete empty row/column’ node, or the ‘value’ cannot be converted to the missing value in them). At the moment, the topic is really not about a bug.
My goal is the following (this is a kind of algorithm of the process):
1, adding input documents
2, filtering input documents (by extension)
3, converting input documents to text
4, cleaning text input templates
5, generating a catalog of search/keywords (based on the texts)
6, making input texts processable (searchable): a search/keyword and its corresponding value are placed on the same line (breaking the text into lines) … this is usually the case in the original text.
7, line filtering based on search/keyword (true/false output)
8, writing the tables created in this way to an Excel table (each table on a separate worksheet). Important information: each table contains values from one document (header is the document name). I created a workflow based on a train of thought.
Currently I have achieved:
- all documents are divided into rows in a single table
- each column contains rows of the same document
- each such document column is followed by a column containing a true/false logical value
- these have a logical value depending on whether there is a search term hit in the document row (if there is a search term/keyword in the row, then true, otherwise false)
for example:
doc1 hit1 doc2 hit2
EndTime: 12/2024 true IMEI: 8972654982 true
Examiner: Khaterina false Location: Bp. false
…
I’m stuck here.
The excel table in the example would contain two worksheets (doc1 sheet, doc2 sheet),
on the doc1 worksheet there is a value: EndTime: 12/2024, (hit: true)
on the doc2 worksheet there is also a value: IMEI: 8972654982 (hit: true)
There are as many worksheets as there are ‘doc…’ columns in the table (this depends on the input documents. Whichever document has a search/keyword hit is included in a column).
I have two thoughts in mind:
-
I treat the columns (e.g. doc1/hit1, doc2/hit2 …) in pairs.
First I copy the first two from the original table to a separate table (table creator?), then I delete them from the original table. So I always have to copy the first two columns. I’m going to loop through this until I run out of ‘doc/hit’ columns from the original table. Here, each column pair is put into a separate table.
But this doesn’t seem to be a viable option. There’s no way in KNIME for a node to generate another node. -
the other idea is that I don’t copy/delete columns. I’m just going to loop through the columns directly. So there’s no need to create nodes. But in this process, I need to filter. Only the corresponding rows (hit: true) from the ‘doc’ columns can be output. So I need to filter based on the values of the ‘hit’ column. A value from the ‘doc’ column is output if the value of the row in the ‘hit’ column next to it is ‘true’. All this so that the next pair of columns is written to another Excel worksheet, the third pair of columns to a third separate worksheet, and so on.
I would like your help with this. Since I am not familiar with coding, I avoid solutions such as Java or expressions. I welcome any ideas. Thank you.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.