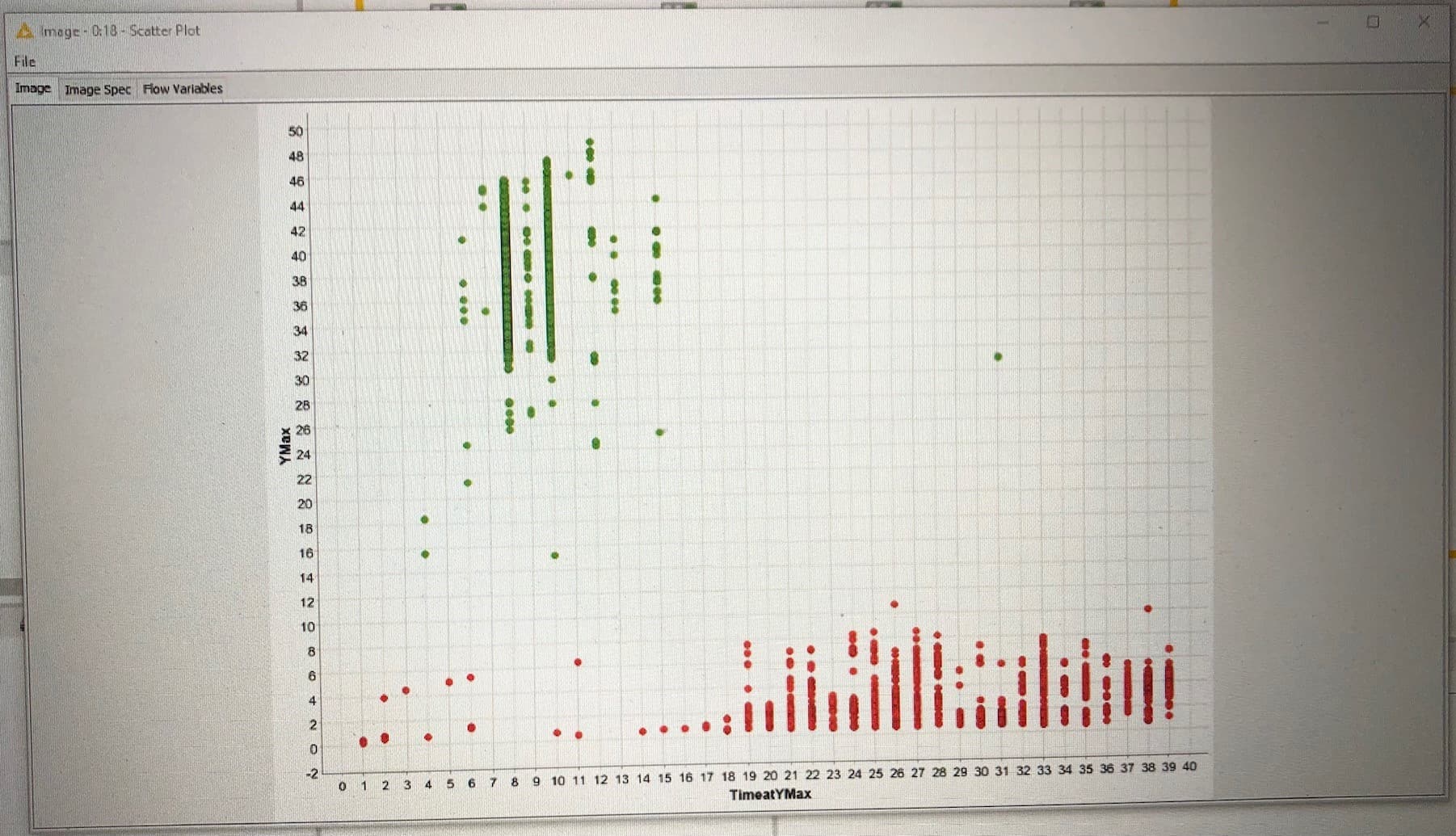
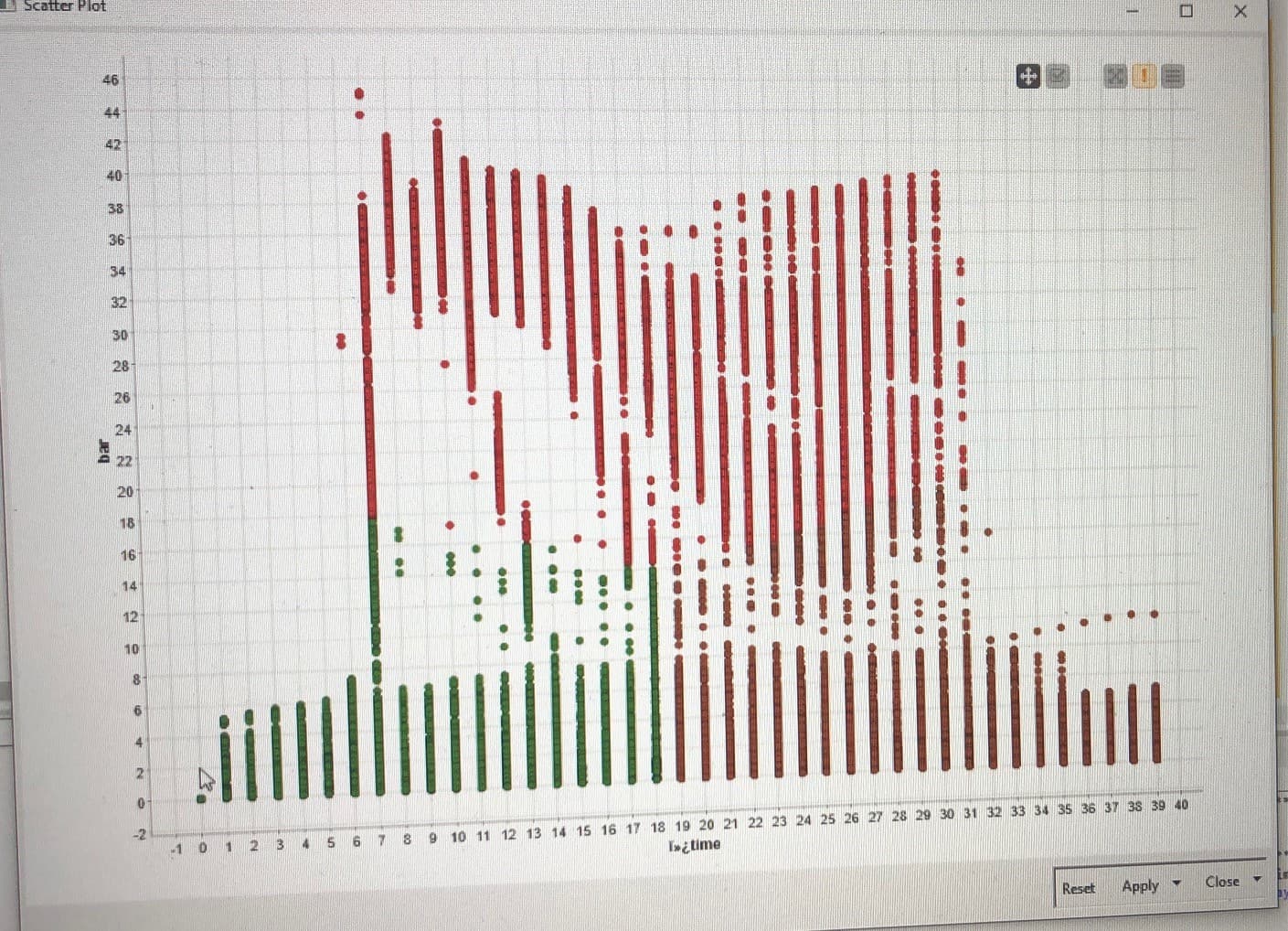
I write my bachelor thesis about quality montiroting in an automotive company. The task is to show, if we can proof a good quality of the product while analyzing the pressure curve. The idea was to train the time series with machine learning methods (unsupervised learning) to cluster the points of the pressure curve and to train with the k-means algorithm. The target is to cluster the stray bullet points with knime so that we can say in the end, if we have a good/bad quality of the product. Is this an good approach to solve the problem or have anybody another idea, how we can solve the problem with knime ?
Looking at the first graph, it seems like there are distinct clusters and so the approach would make sense initially. However, if you don’t know the target values (you are using unsupervised learning), I’m not sure how you would relate these values to the quality of the products? Are there attributes that describe the quality?
Binary Classification (good/bad( would be rather supervised. From timeseries you could extract multiple features (maybe additional ones beside time as well) and then use a ML model or neural net.
br