Hey everyone,
first of all: I’m not totally new to KNIME but far awy rom an expert-level and started a few weeks/month ago with text-mining/-preprocessing of a text-corpus consisting out of 306 texts (appr. 1.6 mill. words) with different length for reasearch-project. The texts are now all local stored in pdfs and were generated out of scans, e-book, -papers etc. The language is german. My major goal for now is: getting some good lda-topics with a adaptable preprocessing-workflow. First, I used the “standart-workflows” delivered by the KNIME-Cources und Forum, which helped me and I adapted them for my needs. But step by step i recognized many fails in my data caused either by the data itself (ocr-errors/converting fails etc.) or by preprocessing-workflow-misstakes/bugs.
To cut a long story short: Could anyone help me with the my major-problem, which I could hopefully solved by a workaround:
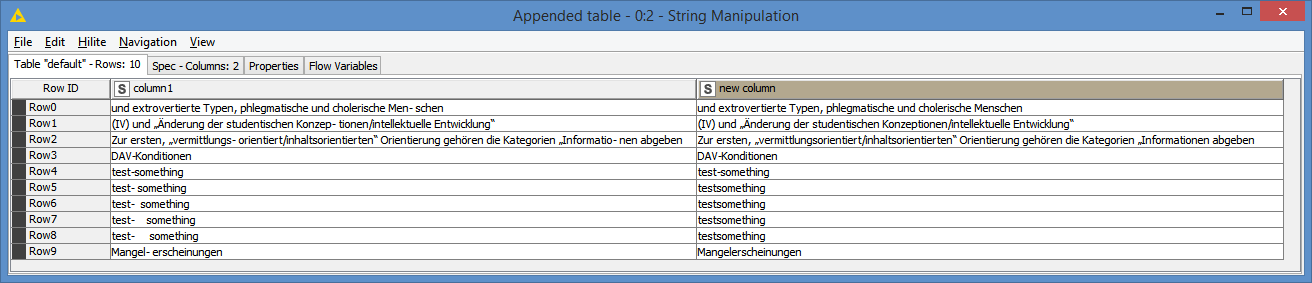
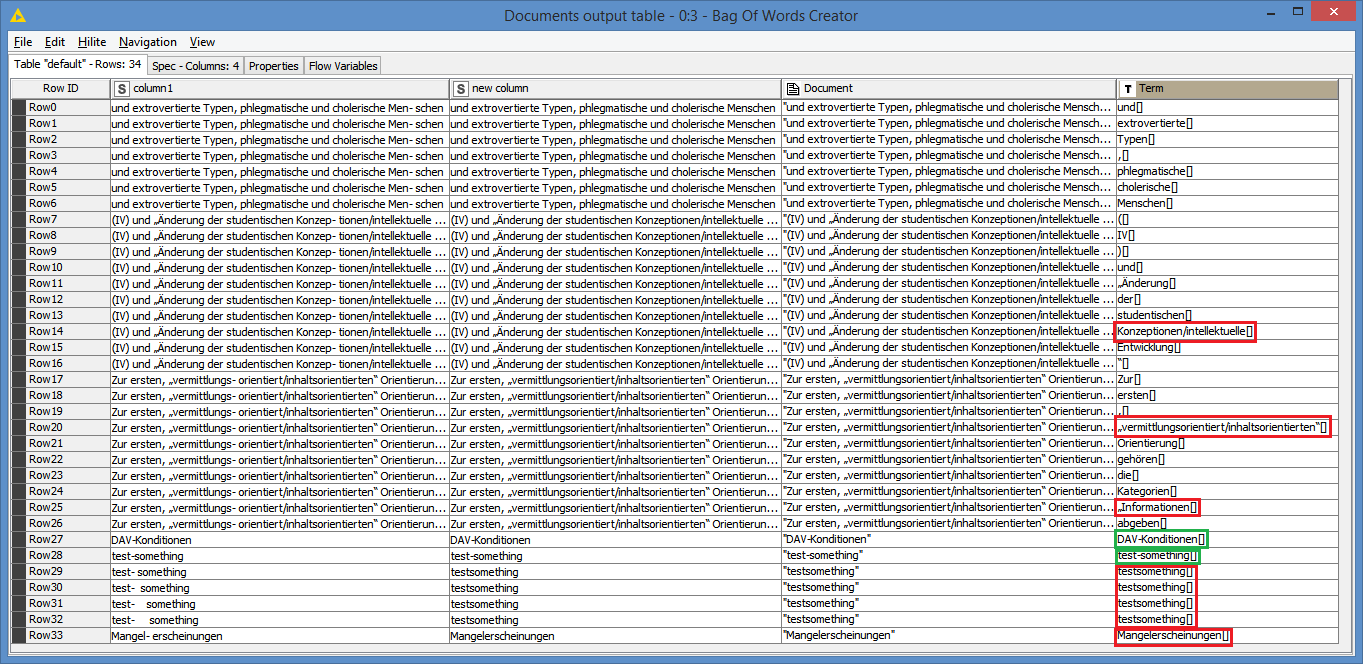
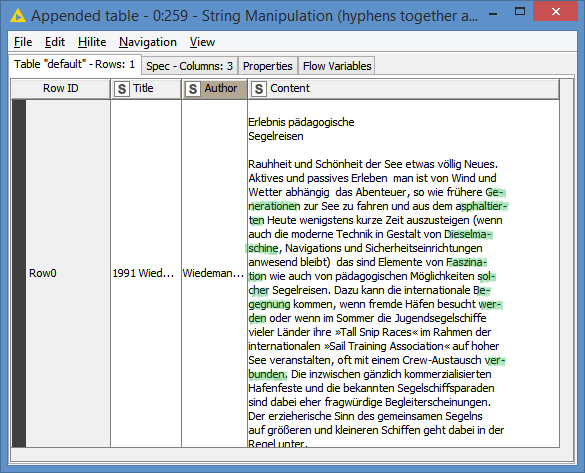
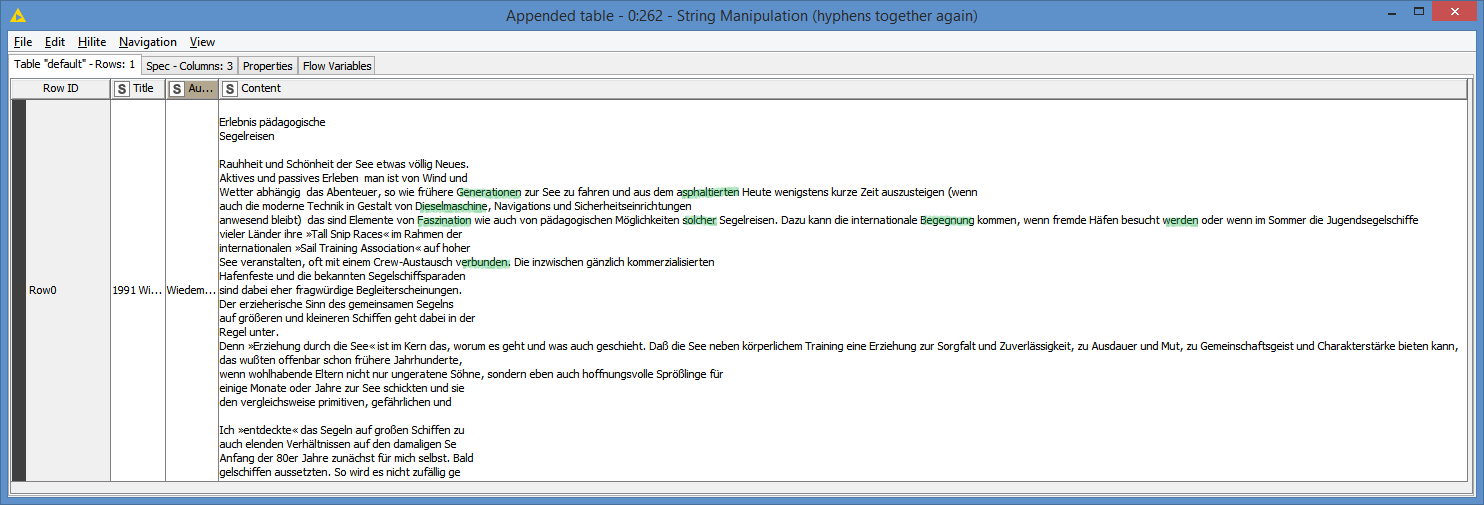
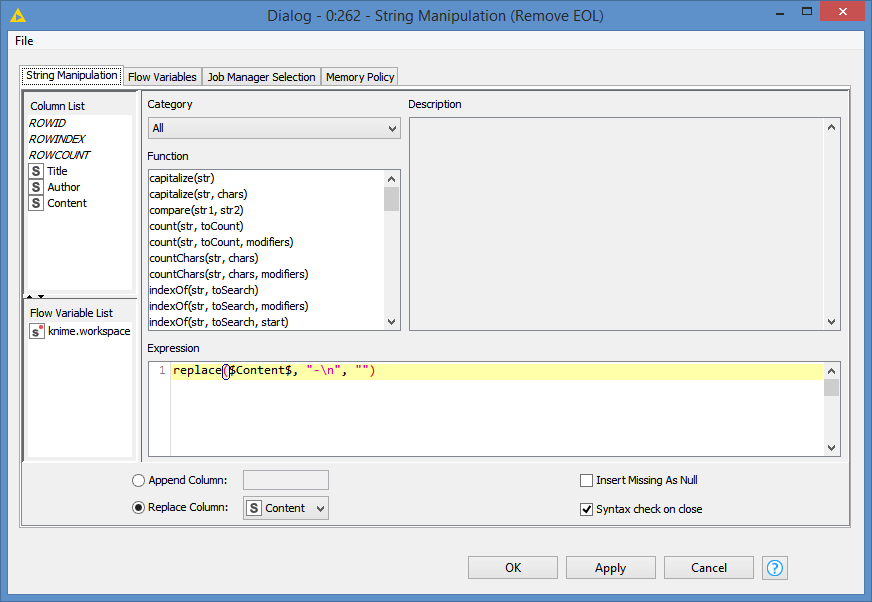
I read all my files by the PDF Parser node, but with none of the tokenizer it was possible for me to get hypenated words (at the end of a line in a pdf) tokenzied as one word. In some cases the hyphenated word are “correctly” displayed in the Document Viewer Node (means together), but afterwards I find them still seperated e.g. in the Bag-of-Word-Node. Could the solution lie somewhere in a data-preperation (like a convertion of the pdf file in a readablie format with a charset that could be read by the PDF parser node?) or ist there any workflow/ node to get these hyphenated word “back together” afterwards and then tokenized as one word?