In workflow 1 I created a variable with a Math Formula and rounded it to 2 decimals using the Round function. At the end of the workflow I export all data with a Table Writer.
In workflow 2 I import all data with a Table Writer. I then rename the above variable to “v_Price (corrected)”. At this stage I do not explicitly use a Round function, because I already did that in workflow 1. Also, I can see that the variable actually has 2 decimal places for all rows.
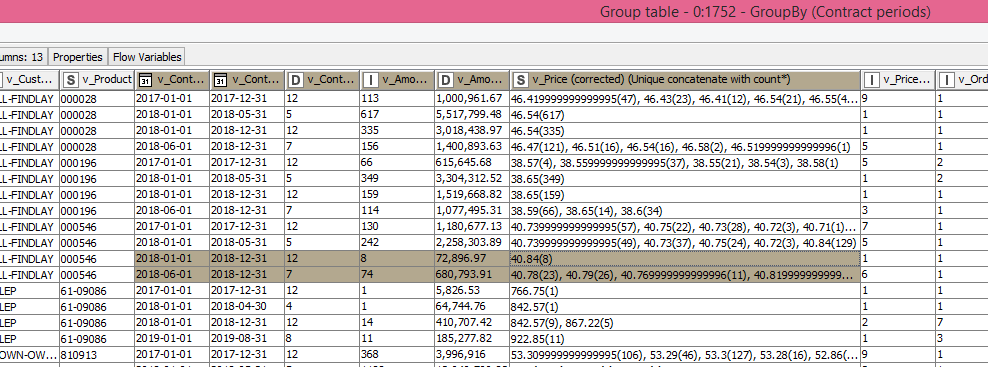
Now comes the problem: when I use a GroupBy node and perform a Unique Concatenate (both with and without count) on “v_Price (corrected)”, the resulting table shows a lot of occurrences with way more then 2 decimals.
I would suggest converting first to string the double columns you want to concatenate. You can easily do this using for instance the rename node. Hope this is of help.
Thanks for the suggestion. For my use it is then easier to explicitly round the value with a Math Formula before I apply the GroupBy. This also solves the problem. But it just does not make sense to me that the GroupBy node creates a lot of decimals for numbers that have been rounded in a previous workflow and only contain 2 decimals for all occurrences. Therefore I was wondering if this is intended or if it is a bug.
I have already experienced this problem in other programming languages. It is probably related to how the cpu internally codes floats and doubles in floating-point and how this is handled in Knime when converting to string. A Knime Team member would certainly provide a better answer to your question of whether this can be considered as a bug.
Hi @Martijn,
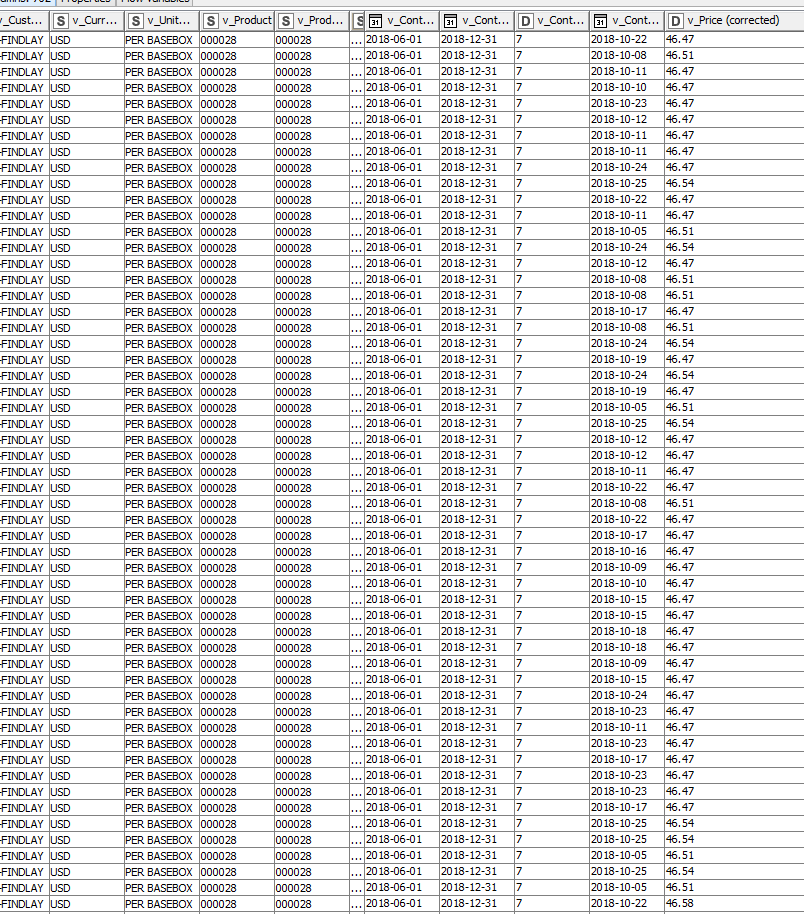
please first check your source table if V_Price (corrected) realy have only 2 digits. You can do this by setting the renderer for this column to full precision to see if the problem is related to the groupby node or not.
Thanks BR. The insight of the full precision helped to spot the problem.
Full precision already shows more decimals for v_Price (corrected). It is renamed from UOM_Price (corrected) and full precision also shows more decimals here. I then noticed that I did not explicitely round UOM_Price (corrected) to 2 decimals. I remember not explicitely rounding it because it is the sum of 2 variables that have explicitely been rounded.
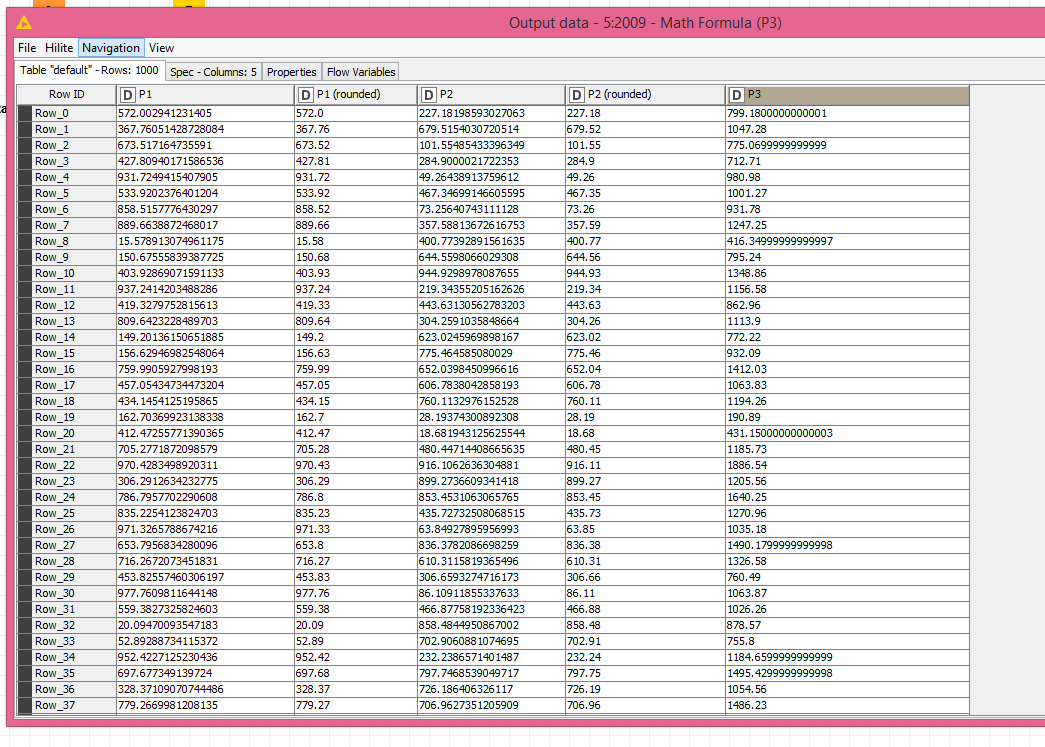
So now we know that the problem is not caused by the GroupBy, but by the Math Formula that calculates UOM_Price (corrected). Apparantly, adding two variables that have been rounded to 2 decimals (also only 2 decimals visible with full precision) can lead to a new variable with more than 2 decimals.
“P3” adds “P1 (rounded)” and “P2 (rounded)”. Both are rounded to 2 decimals as confirmed by looking at full precision. Initially “P3” appears to only have 2 decimals, but full precision shows that “P3” obtained decimals out of nowhere.