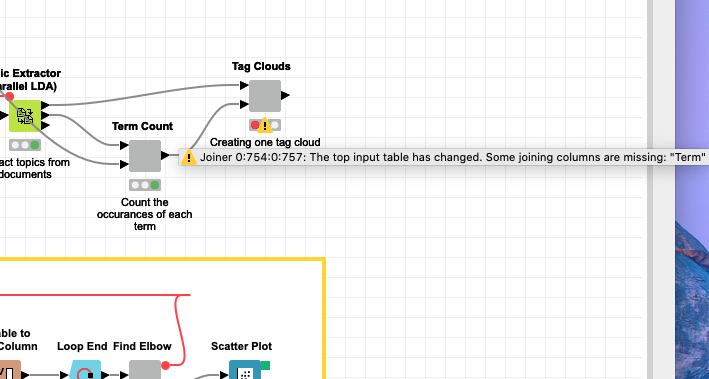
I am trying to create tag clouds for each topic using Knime’s already existing workflow called “Topic Extraction: Optimizing the number of topics with the elbow method”. I am done with all topic extraction except the last node of the workflow that has been giving me an error when I try to create tag clouds for each topic. I attached the screenshot of the error I am getting and would be glad if you can help me with that!
I actually tried that but it did not help. I attached the workflow I have for your reference. I am also trying to match the number of rows with the original data and the output data but I am getting error for that one too. I would be really glad if you can help me with these.
It’s hard to be too specific about what might be going on since you didn’t include an example dataset. Also, your screenshot seems to differ somewhat from the workflow you uploaded.
That said, at a glance, it appears that you were initially trying to join two fields named “Term” and “Term as String” in your Joiner node, but then you changed the connections being input to the Joiner so that now the “Term” field isn’t present any more.
If you are able to upload an example set maybe we can provide more help.
Actually I am just trying to match the row ID’s in the original data and the output data. I tried to do it but not sure if I include the correct nodes in this workflow. I adapted the nodes from a different workflow.
I attached the sample data and would be glad if you can help me with that. I am also having problems in creating tag clouds in this workflow. It keeps on giving me an error.
I want to create something similar to the screenshot I attached but not sure if this is doable via Knime and with the tag cloud node.
I really appreciate your help with this! Thank you!
I am still waiting for your help in matching the rows from the original data with the output data and would be glad if you can let me know if this is possible to do so. I have a deadline for this project so that is why I am in a rush. I really appreciate your help with this in advance!
I’ve uploaded a workflow with my corrections. I’ve left some red annotation boxes to mark where I made changes. A few comments:
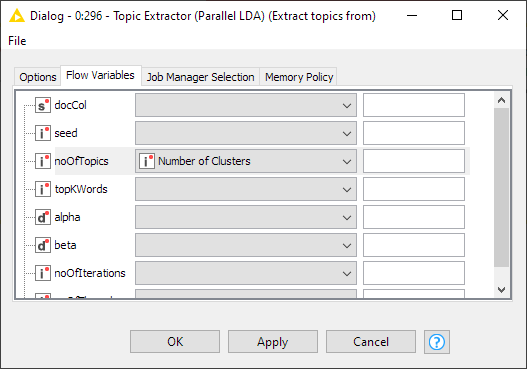
The Elbow Method section serves no purpose currently since you are manually selecting 8 topics in the LDA node. If you want the Elbow Method used, you will need to apply the flow variable it creates to the LDA node.
You were missing some connections to the Term Count and Tag Clouds components, so I added those.
The configuration of the RowID node was why your rows weren’t joining. I changed it so that the RowID node generates a standard RowID, instead of one based on the text of your dataset.
Inside the Tag Clouds node, you were grouping based on Term instead of Topic, so I made changes to a couple of nodes there to reflect that.
Hope this helps. I would encourage you to carefully compare the changes I made to your previous workflow to make sure you understand what I did - it’s possible I didn’t make the best choices, after all. Definitely don’t just accept my updates as gospel!
I really appreciate your help with this. I went over your changes and have few questions.
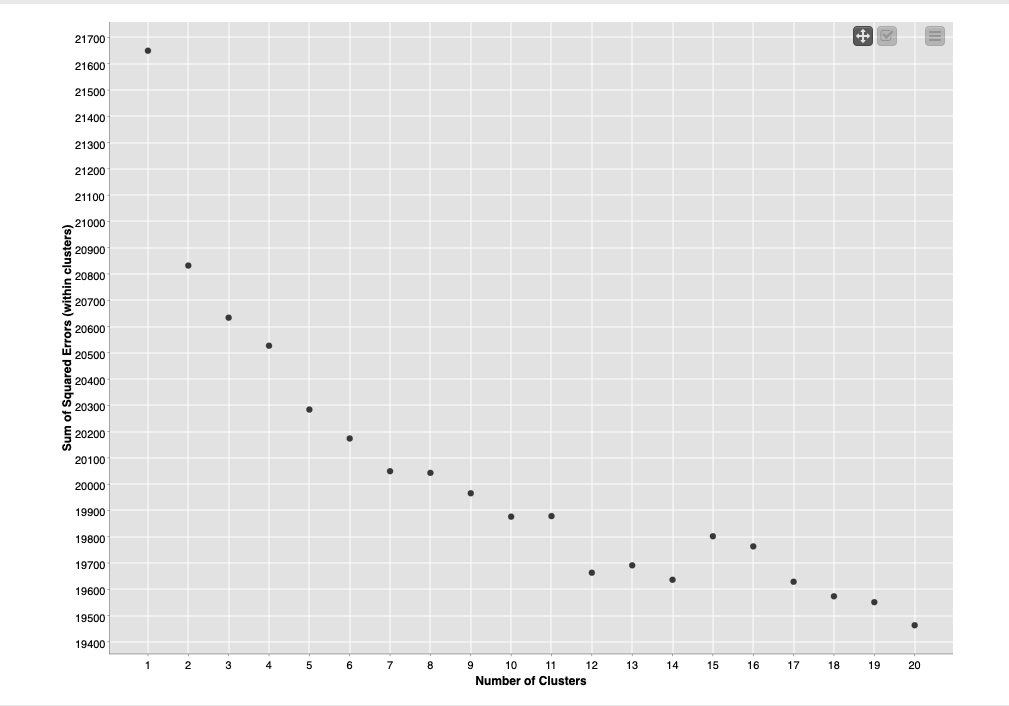
1- Regarding the elbow method, before I was told (not you, probably it was someone else who helped me) to check the scatter plot first and then enter the number where the number of topics started to decline. I attached the screenshot of the scatter plot. This is the reason I selected 8 topics. However, I do not understand how to apply flow variable. I want to apply elbow method in the LDA so currently, I was thinking that I did it correctly. I would be glad if you can explain me more about how to apply the flow variable.
2- When I re-ran the workflow with your edits by using the sample data I shared with you, I saw that number of rows of the original data is equal to the number of rows of the output data (N=20). However, when I imported the whole dataset, number of rows of the original data is 395 and number of rows of the output data is 392. Am I missing something? I attached the whole dataset and would be glad if you can let me know if I am doing something wrong.
1 - You can apply the flow variable in the LDA node like this:
Based on the scatter plot I would say that 2, 5, and 8 are candidates for the number of clusters, and the Elbow method section of the WF will choose 2.
2 - It looks like the last three documents are being removed in the last GroupBy node contained in the Preprocessing component. It’s not immediately clear to me why this is.