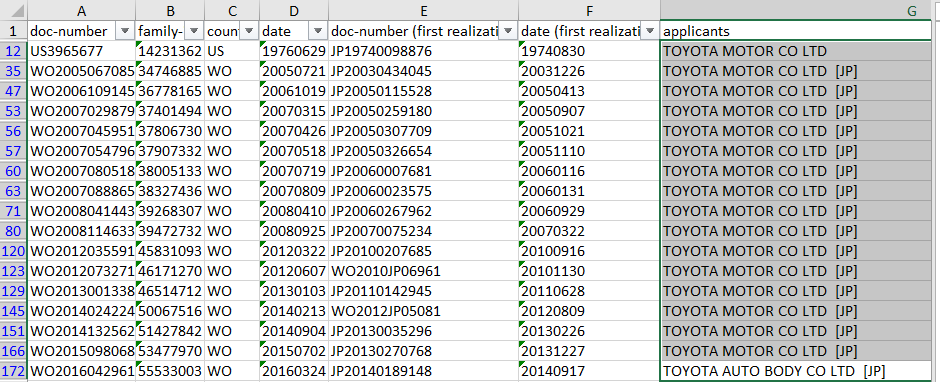
I try to track similar words of specific column and use the most overlapped word for each line entry . In the picture below, you can see the specific column called “applicants”. If there are 3 words for example Toyota Motor, Toyota Auto Body Co Ltd (Jp) and Toyota… I like to replace every single line entry with the simple word “Toyota”. This precedure I would like to implement with all other line entries within column “applicants”. Can you help me with this precedure?
Hi @8bastian8 , In your example, “CO LTD” could be similar words. Unless when you say “track similar words”, do you mean from left to right, meaning each row of that column that starts with the same word (which in your example would TOYOTA)?
But you mentioned that it could be similar words, in which case, “TOYOTA MOTOR CO LTD” could qualify as result, as well as “TOYOTA MOTOR CO LTD [JP]”.
So, what is the logic to qualify “similar words”? Is it just the first word?
And is a word always separated by a space, or there could be other delimiters?
If it is just the first word and separator is always a space, then you could simply extract the first word of each row in that column.
Can you show us all unique applicants so we can see what type of pattern you are looking for?
PatentdatenbankNEW.xlsx (35.9 KB)
Hello,
I have looked through the column “Applicants” and It would be make sense If the first two terms within each row should be extracted. Is this possible?
Many thanks for your help. I just attached you the file!
Hi @8bastian8 , it looks like you are adapting some logic on the fly
There’s only 1 case from your list that might be a problem:
COMMISSARIAT ENERGIE ATOMIQUE [FR]
COMMISSARIAT L ÉNERGIE ATOMIQUE ET AUX ÉNERGIES ALTERNATIVES [FR]
The “L ÉNERGIE” from the second one is meant to be “L’ÉNERGIE”, the “L’” meant to be “LA” but in french becomes “L’” because the next word starts with a vowel, and “LA” simply means “THE”.
So, with the logic you are proposing, you will end up with:
COMMISSARIAT ENERGIE
and
COMMISSARIAT L
I would suggesting updating the data for the "COMMISSARIAT L " cases rather than changing the logic of 2 words.
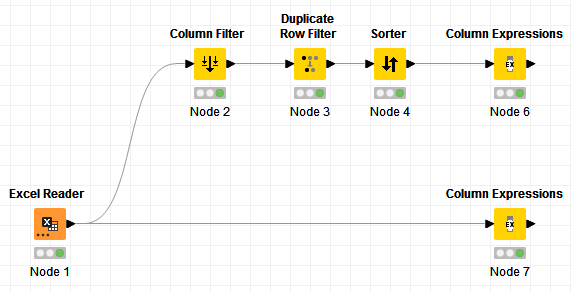
I put something together to retrieve the first 2 words. This is what it looks like:
You really need just the Node 7 there, but the top part was to check what kind of applicants values you have.
Hi @8bastian8 , no, both column expression are the same, they do the same thing. The first path (top one) simply retrieves unique applicants values, to give an idea what will be transformed, and the second path (bottom one) processes the whole dataset.
I did not modify your data as I don’t know what you want to modify. You can either do the modification directly in the excel file, or apply a string manipulation to do a replace.
You can change “COMMISSARIAT L ÉNERGIE” to either:
“COMMISSARIAT ENERGIE” to make it consistent with the other one
or
“COMMISSARIAT LÉNERGIE” which will give you a different record