Hi everybody I was looking some video lectures of "CS231n Convolutional Neural Networks for Visual Recognition" from Stanford U in youtube and in minute 32:53 (http://bit.ly/2BKJ2Bk) the lecturer mentions about splitting the data in three sets named: Train, Validation and Test.
In Knime you can split your data using the Partitioning Node, but (I guess) into just the Train and Test set. I wonder if there is some way to include the validation test in knime or the prediction nodes must be modified to have the Validation test input.
Hi vijayv2k, I think that splitting the data in 3 is a mean to an end. This webpage mentions http://bit.ly/2laa363 the difference between the test and validation set:
That the “validation dataset” is predominately used to describe the evaluation of models when tuning hyperparameters and data preparation, and the “test dataset” is predominately used to describe the evaluation of a final tuned model when comparing it to other final models.
So I wonder if it's worth to consider this in a future release
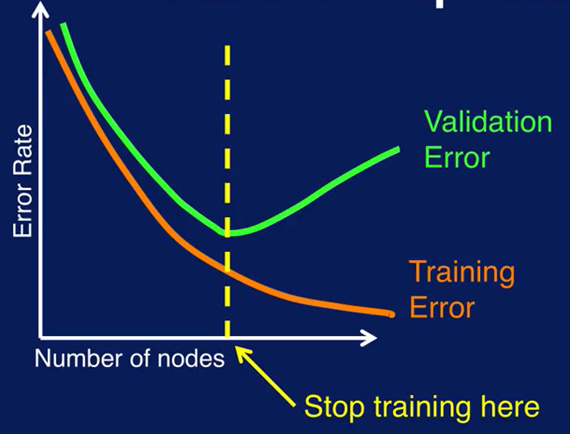
Hi everybody, I came again with the concept of “validation set” which is “used to determine when to stop training to avoid overfiting” see this video in Coursera: Using a validation set
I wonder how it can be done in Knime since you can only have test and training set.
A validation data set would need to be used inside the node. Consider a decision tree, you would calculate the first two splits and after each split you apply the preliminary tree to the validation data set. If the error goes down, you continue splitting, if not you stop and output the tree.
This could be doable with looping and restricting the tree to a fixed number of levels.