Hello,
I want to transcode data into text files.
As a starting point I have a folder with a variable number of files in csv format. The content may vary from one file to another: different number of columns and different data. But I need to change all 18 character text strings starting with “000” by replacing the first 3 characters with “100” for example.
Could someone help me, I’m new with such tools.
Regards
JMarc
Do you want to write out separate files with your data corrections? Can the character string you want to change appear in any column in the files? If your data isn’t proprietary it would help if you could upload several example files.
1 Like
Hello
First thank’s for taking time to help me.
Do I want to write in separate files : yes
Can the character string appear in any column : yes
I will upload 3 input files and 3 output files as result looked for.
JMarc
Input files exemple :
fichier1_in.txt (366 Bytes)
fichier2_in.txt (567 Bytes)
fichier3_in.txt (1.3 KB)
result expected :
fichier1_out.txt (366 Bytes)
fichier2_out.txt (567 Bytes)
Here is the last output file expected
fichier3_out.txt (1.3 KB)
Hi @JM64 , are the files always tab separated values?
Hello @takbb
Yes always tab separated.
The number of columns may change.
If the string type I’m looking to transcode is present in one column it means that all the column will be concerned because of its character size of 18 char. But I may have several column in some files.
Files provided are not real ones but really representative.
Regards
JMarc
@JM64 one thing you could do is employ Python and ChatGPT to create a small Python code to do what you want and put this into a KNIME workflow to handle the rest of your tasks.
The code would look something like this:
import knime.scripting.io as knio
import numpy as np
import pandas as pd
# Step 1: Import the file
v_import_file = knio.flow_variables["File path"]
df = pd.read_csv(v_import_file, sep='\t', dtype=str, header=None)
# Step 2 & 3: Scan each column and replace strings
for column in df.columns:
df[column] = df[column].apply(lambda x: '100' + x[3:] if isinstance(x, str) and x.startswith('000') and len(x) == 18 else x)
# Step 4: Save the modified DataFrame (optional)
v_export_file = knio.flow_variables["result_file"]
df.to_csv(v_export_file, sep='\t', index=False, header=False)
knio.output_tables[0] = knio.Table.from_pandas(df)
4 Likes
I’m impressed. You did great.
Thank’s a lot !
JMarc
1 Like
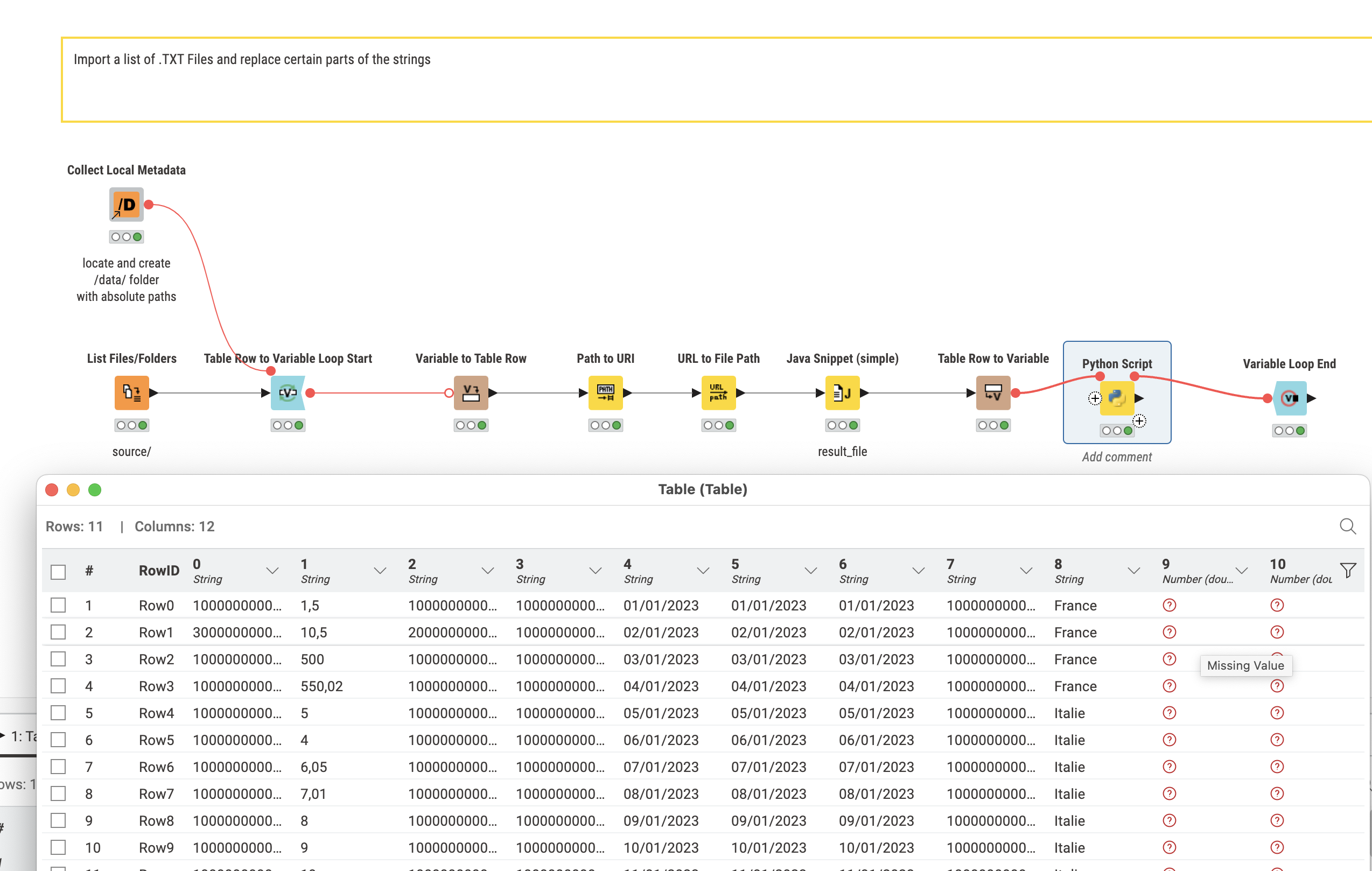
I don’t want to beat a dead horse, but here’s a workflow using only native Knime nodes. Its no improvment over @mlauber71’s solution. My Python and Java skills are practically nonexistent so I always look for a Knime solution with no coding. That’s not always possible, but in my opinion its preferable when possible.
3 Likes
Hello
Thank’s again, I’ll have a look to this alternative. My python & java are not better than yours so havoing a solution with no coding is interesting. I’ll learn from your both solution suggestions.
Thank’s again.
JMarc
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.