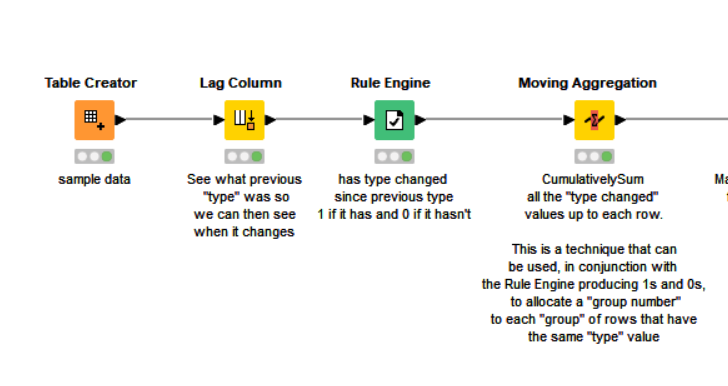
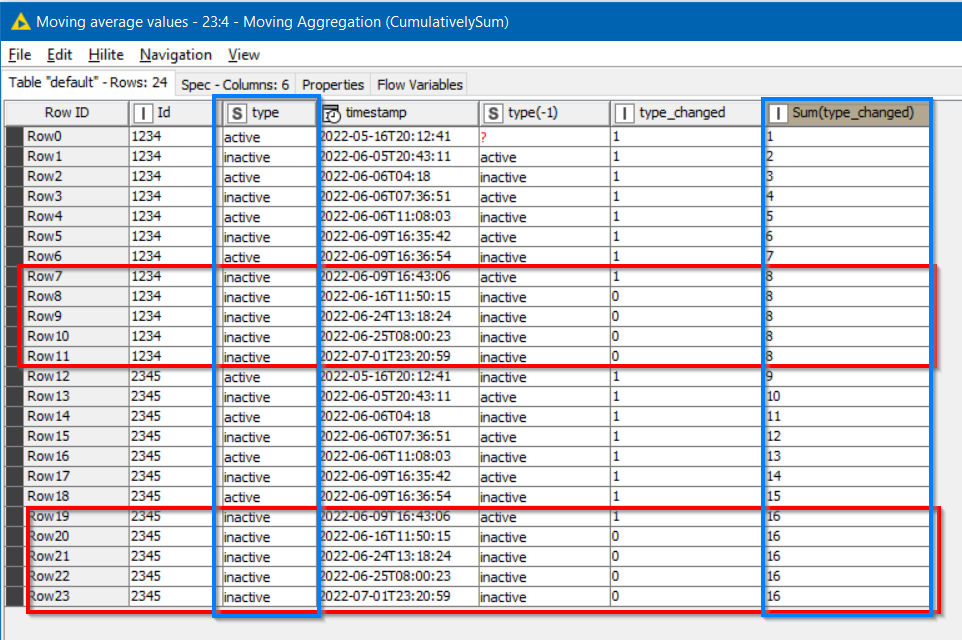
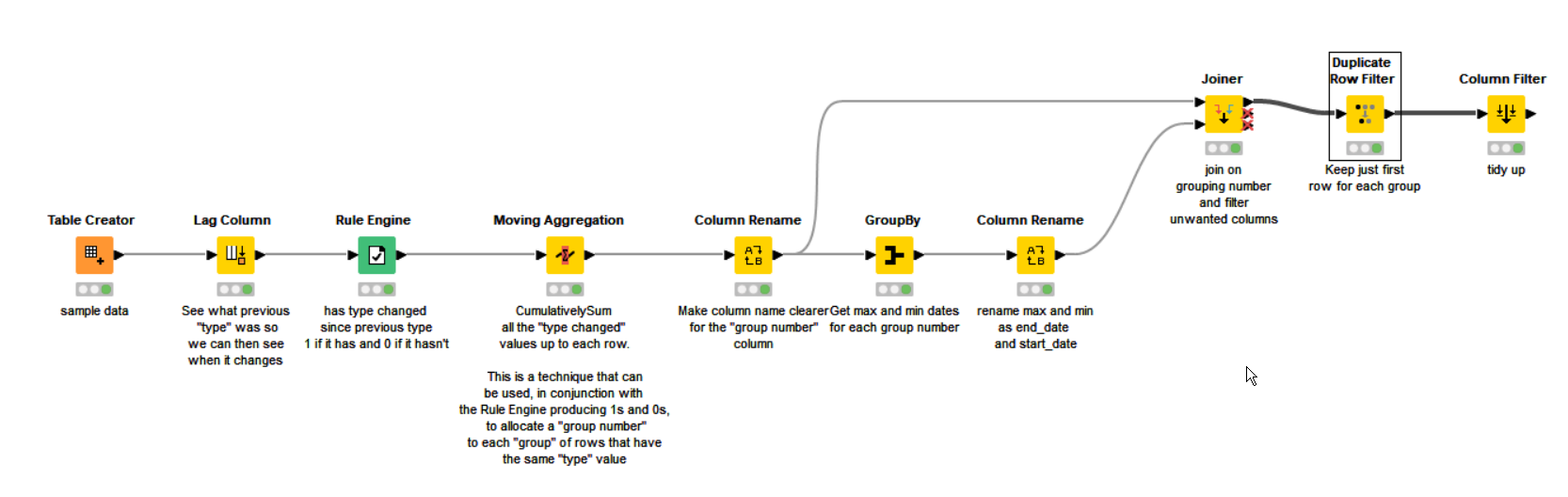
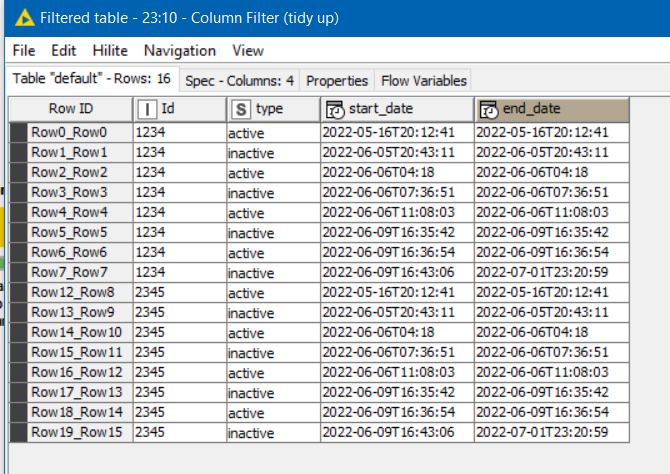
Hello!
I have these data in a table:
| Id | type | timestamp |
|---|---|---|
| 1234 | active | 2022-05-16T20:12:41 |
| 1234 | inactive | 2022-06-05T20:43:11 |
| 1234 | active | 2022-06-06T04:18 |
| 1234 | inactive | 2022-06-06T07:36:51 |
| 1234 | active | 2022-06-06T11:08:03 |
| 1234 | inactive | 2022-06-09T16:35:42 |
| 1234 | active | 2022-06-09T16:36:54 |
| 1234 | inactive | 2022-06-09T16:43:06 |
| 1234 | inactive | 2022-06-16T11:50:15 |
| 1234 | inactive | 2022-06-24T13:18:24 |
| 1234 | inactive | 2022-06-25T08:00:23 |
| 1234 | inactive | 2022-07-01T23:20:59 |
| 2345 | active | 2022-05-16T20:12:41 |
| 2345 | inactive | 2022-06-05T20:43:11 |
| 2345 | active | 2022-06-06T04:18 |
| 2345 | inactive | 2022-06-06T07:36:51 |
| 2345 | active | 2022-06-06T11:08:03 |
| 2345 | inactive | 2022-06-09T16:35:42 |
| 2345 | active | 2022-06-09T16:36:54 |
| 2345 | inactive | 2022-06-09T16:43:06 |
| 2345 | inactive | 2022-06-16T11:50:15 |
| 2345 | inactive | 2022-06-24T13:18:24 |
| 2345 | inactive | 2022-06-25T08:00:23 |
| 2345 | inactive | 2022-07-01T23:20:59 |
And I want to change this structure like that:
| Id | type | start_date | end_date |
|---|---|---|---|
| 1234 | active | 2022-05-16T20:12:41 | 2022-06-05T20:43:11 |
| 1234 | inactive | 2022-06-05T20:43:11 | 2022-06-06T04:18 |
| 1234 | active | 2022-06-06T04:18 | 2022-06-06T07:36:51 |
| 1234 | inactive | 2022-06-06T07:36:51 | 2022-06-06T11:08:03 |
| 1234 | active | 2022-06-06T11:08:03 | 2022-06-09T16:35:42 |
| 1234 | inactive | 2022-06-09T16:35:42 | 2022-06-09T16:36:54 |
| 1234 | active | 2022-06-09T16:36:54 | 2022-06-09T16:43:06 |
| 1234 | inactive | 2022-06-09T16:43:06 | 2022-07-01T23:20:59 |
| 2345 | active | 2022-05-16T20:12:41 | 2022-06-05T20:43:11 |
| 2345 | inactive | 2022-06-05T20:43:11 | 2022-06-06T04:18 |
| 2345 | active | 2022-06-06T04:18 | 2022-06-06T07:36:51 |
| 2345 | inactive | 2022-06-06T07:36:51 | 2022-06-06T11:08:03 |
| 2345 | active | 2022-06-06T11:08:03 | 2022-06-09T16:35:42 |
| 2345 | inactive | 2022-06-09T16:35:42 | 2022-06-09T16:36:54 |
| 2345 | active | 2022-06-09T16:36:54 | 2022-06-09T16:43:06 |
| 2345 | inactive | 2022-06-09T16:43:06 | 2022-07-01T23:20:59 |
Any idea how I do that?
Than you!
Razvan