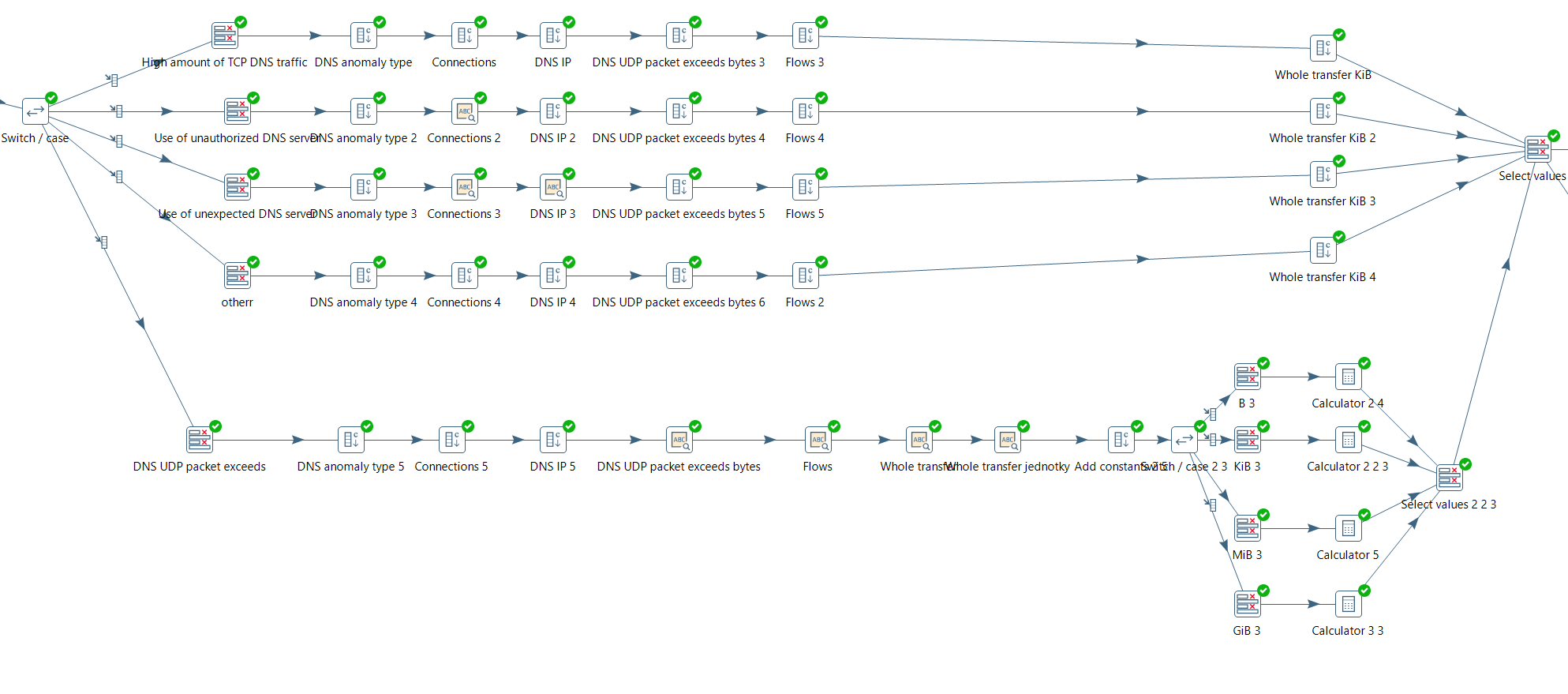
if text begins with High amount of TCP DNS traffic => go into the first branch Use of unauthorized DNS server => go into the first branch
.
etc
.
other => something else which is not defined
in case there occur some undefined text string I can extend this case by another branch like it used to happened with DNS UDP packet exceeds
If you were me which approach you would follow? I think this way with so huge CASE node in KNIME is not possible or can you give me some hint?
Example of another Pentaho huge transformation uses CASE node based on first sentence in text string. I need to know how to solve this approach
Hi Jiri,
you can still use a case switch like that in KNIME, but you have to combine multiple for more than 3 branches. Additionally, to determine the branch you have to use the Rule Engine Variable node with the LIKE operator to calculate the branch to use, then use the flow variable from the rule engine in the CASE Switch Data (Start) node.
Kind regards
Alexander
yes I saw in KNIME only three branches are supported, so in this case I have to combine more nodes and that’s quite tricky and doesn’t look so nice and clean. Flow variables are the problem. I don’t know how to operate with them and in which situations should be variables benefit for me. Even nodes with (Start) is little bit mysterious for me.
I am still in fight with KNIME variables, but I suggest without variables I can not improve my skills.
Would you be so kind and show me some short example? That would be really appreciated.
Hi,
actually, I think there is a better way than the CASE SWITCH. Have a look at the Row Splitter instead. It allows you to split your table based on the content of a column and also supports wildcards, so you can split your table using the pattern “High amount of TCP DNS traffic*”. All rows containing that will go into the top port and the rest into the bottom. Then you can attach another Row Splitter at the bottom port. This allows you to do what you need without any loops or variables and in the end you can just put the table together again using the Concatenate node.
Kind regards
Alexander
sorry Alex that’s once again me. I’ve got it and it works perfectly. But how to deal with some unexpected data on the input which is not gonna be pre-defined in Row Splitter in Pattern?
Hi Jiri,
That data should come out of the bottom port of the last row splitter, right. There you should implement your own logic to deal with those cases, if you do not simply want to ignore them.
Kind regards
Alexander