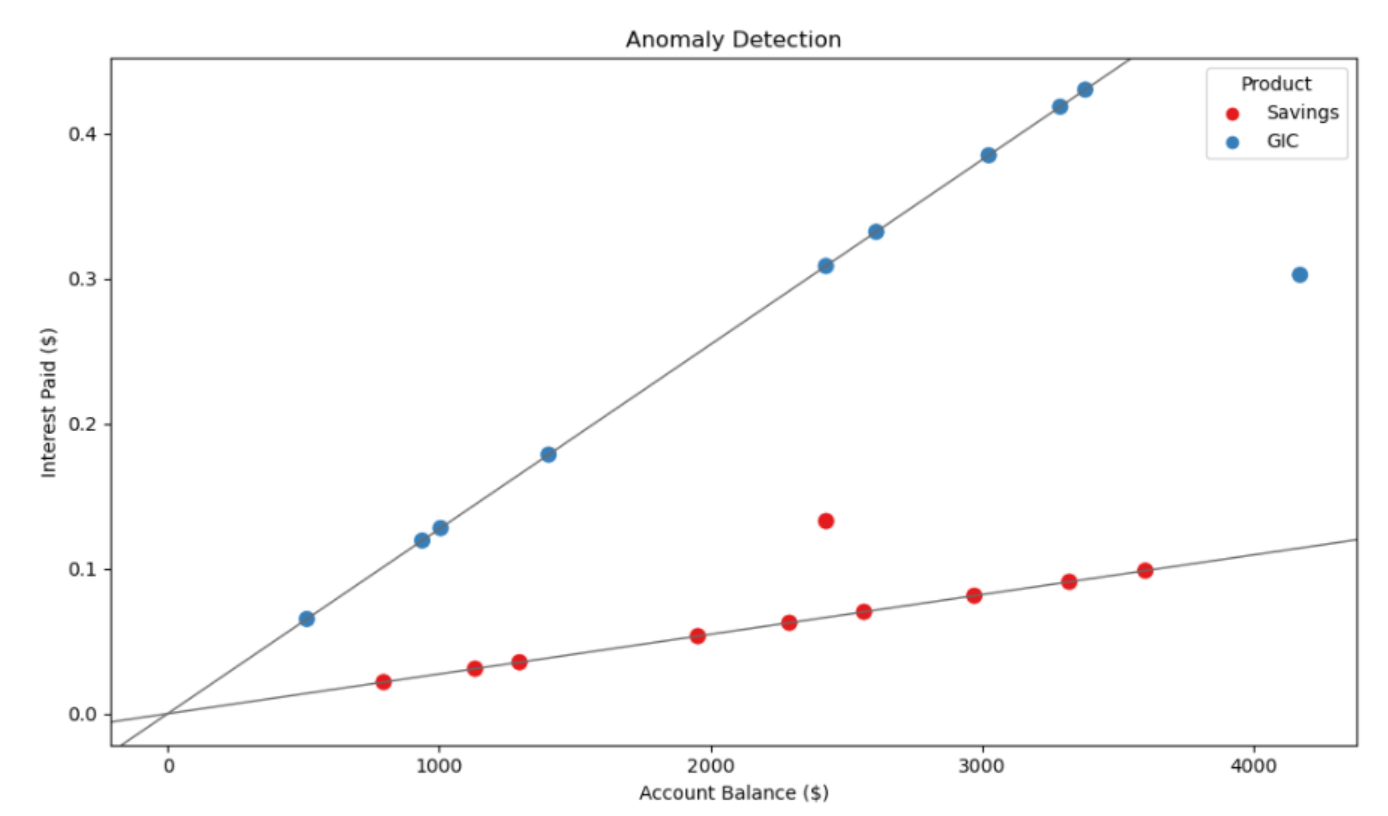
I’m excited to share with you a KNIME workflow for anomaly detection that I’ve been working on. This powerful tool can help you identify and investigate unusual patterns or outliers in your data (specifically, where interest rates are applied to account balances).
I would love to get your feedback on this workflow! If you find it helpful or have any suggestions for improvement, please let me know in the comments below. Your input means a lot!
Now, here’s a key question for you: In what stage of an internal audit (planning vs. fieldwork) would you use this tool, and why? Let me know your thoughts down below!
I’m curious to know your thoughts on this, but I have some exciting news to share: our team at Fidelity Canada had the opportunity to use this tool in practice last month. And I have to say, it has really transformed our audit approach when applying data analytics to large volumes of data!
But that’s not all! I’m happy to announce that I’ll be making a presentation to our group about this workflow in June 2023. So, mark your calendars for the presentation in June, and get ready to dive into the world of anomaly detection. I’ll be sharing why we developed this tool, how it compares to typical audit re-calculations, and how it has reshaped our audit approach and opened up new possibilities for data-driven analysis.
It worked for me, I had to install some Python libraries first (e.g. seaborn).
I am now thinking how to use in our audits. The first thing that comes to mind is in credit risk, to see if there is any correlation between the risk rating attributed to loans and their days past due. I will also check with other colleagues in what other occasions we can use this.
Generally speaking, I like the idea of using scatterplots during the planning stage to quickly identify any correlations. The nice thing about scatterplots is they can be used to analyze any data set with 2 numerical fields. They also make good visualizations for reports.
I believe KNIME also has a 3D scatterplot functionality if I’m not mistaken.
Welcome to the forum. Looks good. I have a similar approach where I use the regression nodes for x and y variables to work out the differences between expected and actual observations. I use the column name node to change the fields into x and y and that allows the script to be applied to more audit applications. I am reasonably new to knime myself. I am using it for payroll at the moment, ie base salary to tax paid, super % etc. Same script just different columns to regress. I have the script extract the exceptions with the variable names in column ie. Regressed Field column has say “Base Salary+Base Salary with Allowances and Overtime” that way I can collate all the exceptions into one node and then do a pivot of the exceptions identifed against the employee. It saves followup separate exceptions when they are all related normally