Hello Everyone,
I am writing to you because I found a solution for a little challenge, but it is very vulnerable for errors when I want to change something later and ask for advice on how to make it better.
I would show you here what I did.
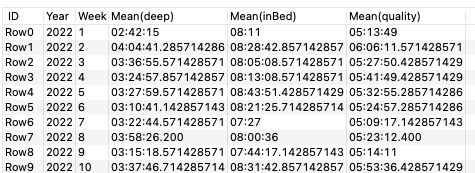
My Input is the following table of sleep measurements:
I wanted to get the correlation of it, but it is not possible because the Mean values are all Time types and not Decimal.
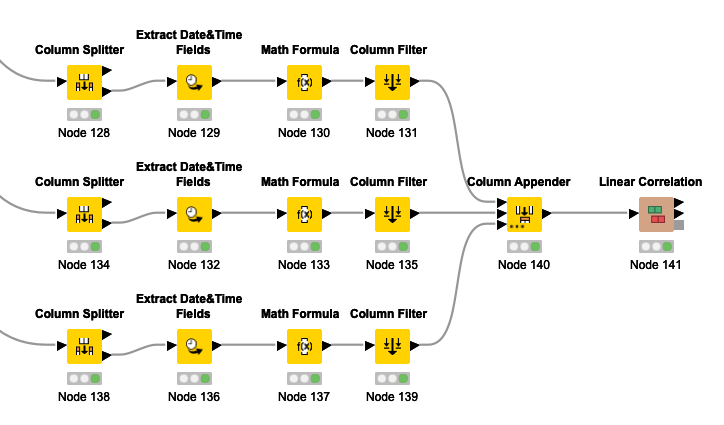
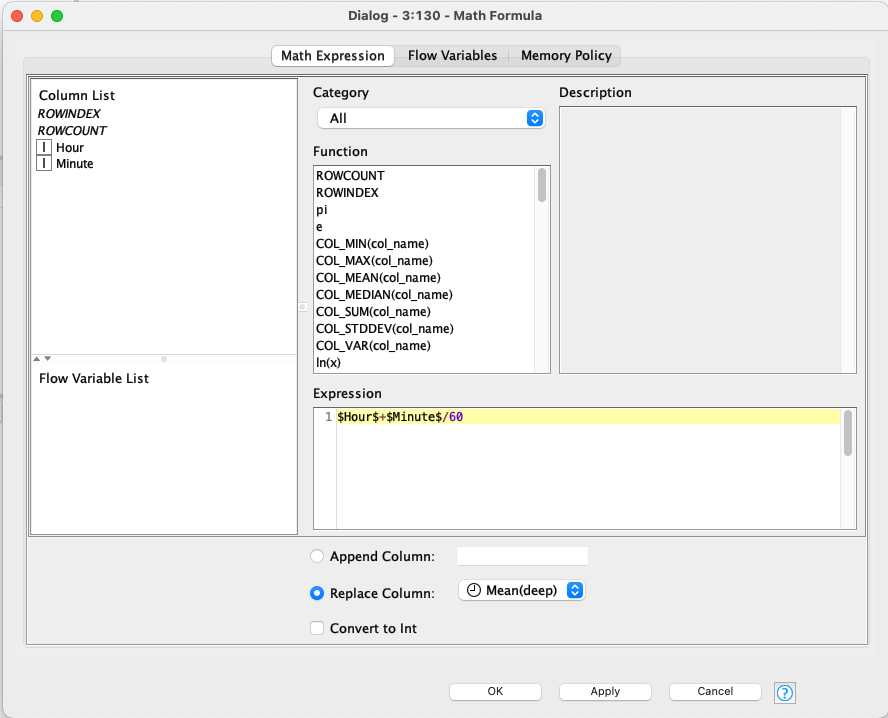
Therefore, I have built the following pipeline to transform each row separately to a decimal type:
This worked, and I could determine the Correlation between the three columns afterwards.
But, as you can see, it is cumbersome and not easy to maintain. It would be much nicer to use a multicolumn function which can transform generally a timespan to a decimal number.
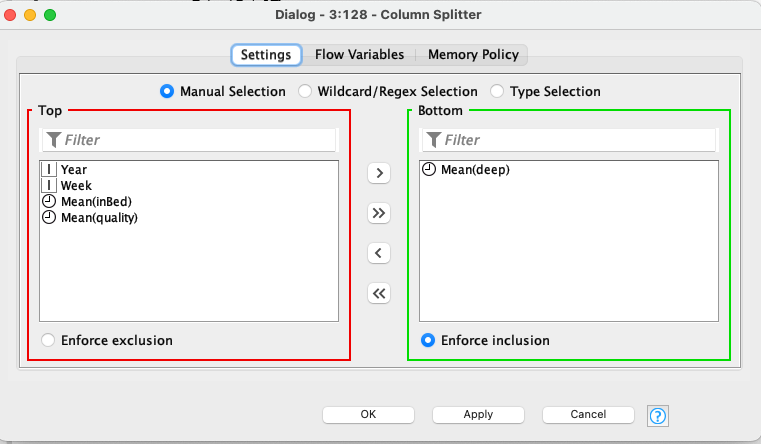
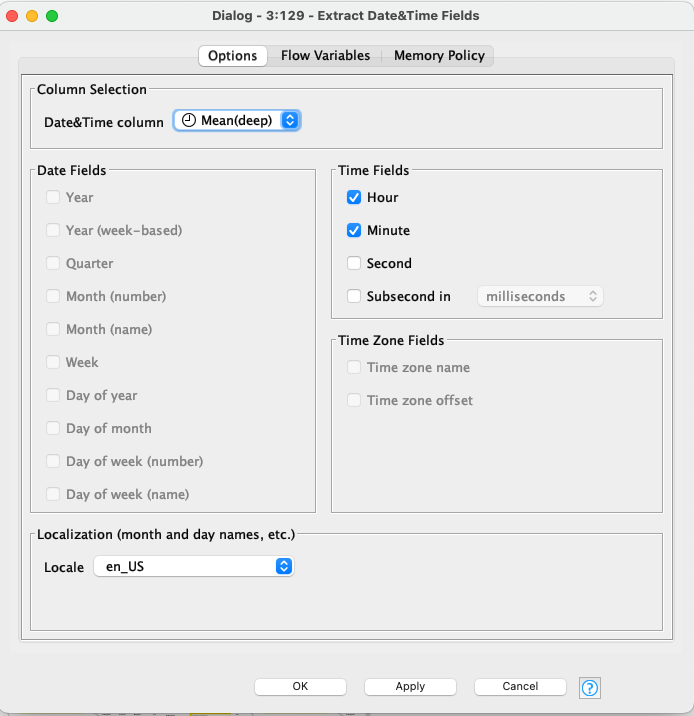
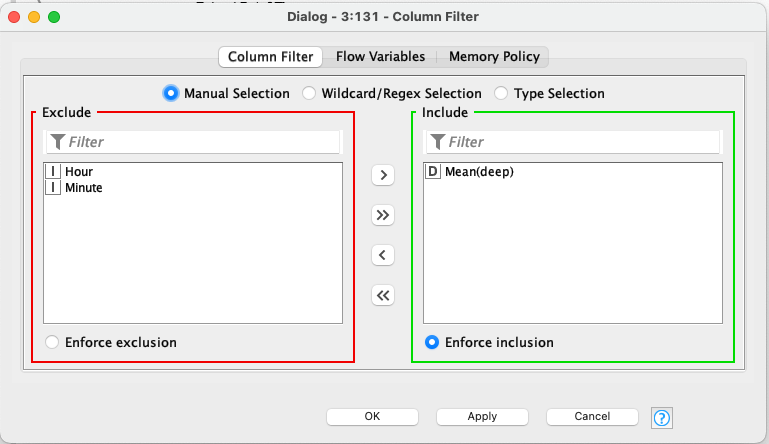
To give you some details what I did in each of these pipelines, here are the settings of the top pipeline stages:
I split the columns separately to make the transformation:
That’s what I did for all three Mean values of the table at the beginning.
As a little background information, I thought of using the String Manipulation (Multi Column) block, but do not know how to insert the right formulae to transform my inputs to a decimal number.
Thank you very much to everyone which is helping me to make this a better and cleaner stream.
I wish you a nice rest of the day.
Kind regards, Alex
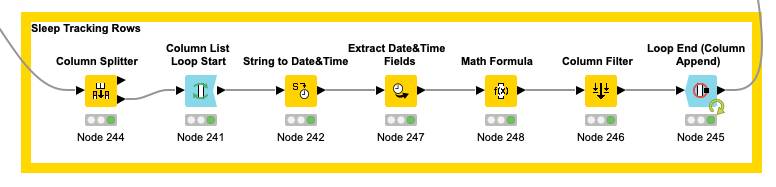
In case you are copy pasting the same kind of operation multiple times with the same intent, I would opt for either a loop, metanode or component depending on the situation. That will make your life a lot easier since you only have to apply any changes once instead of in all 3 data flows. It will depend on your actual use case which option is feasible, also keeping performance in mind.
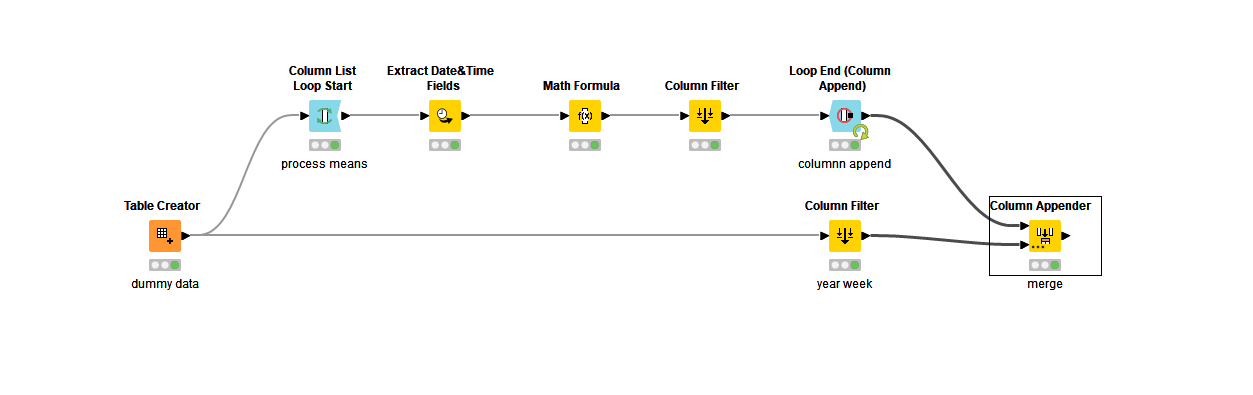
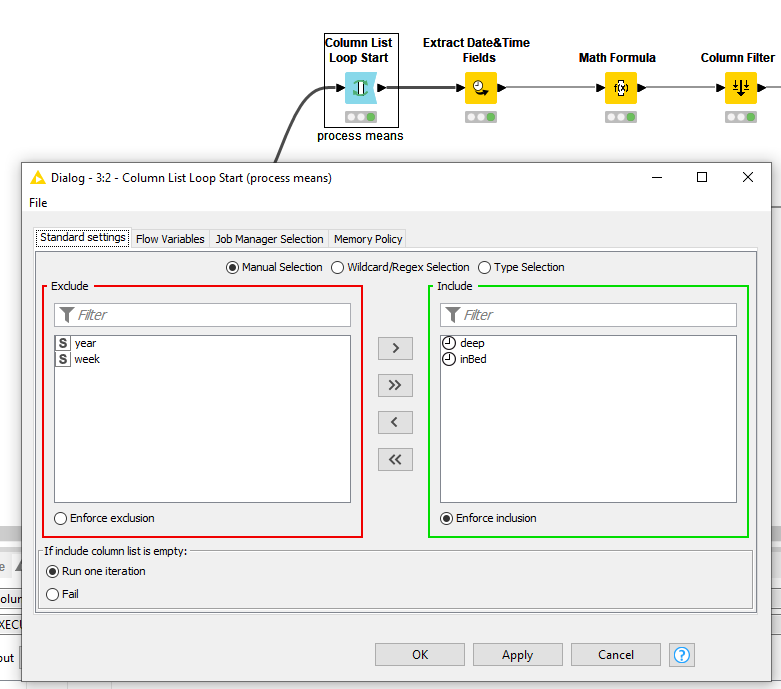
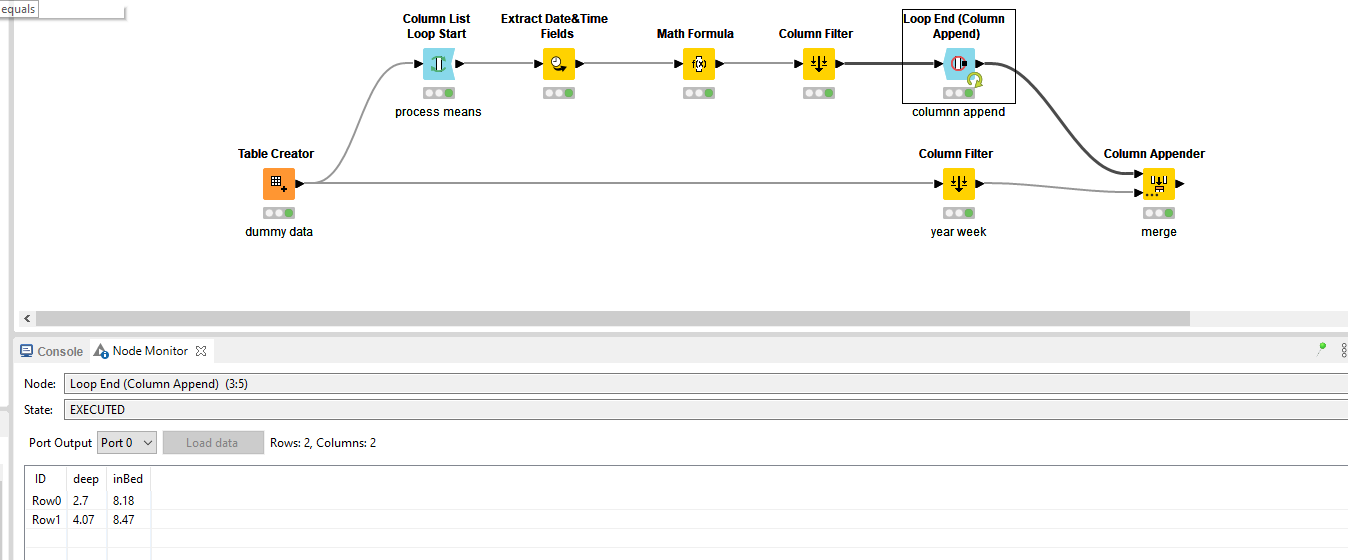
To illustrate, in this case you can opt to use a Column List Loop. Here, you can define which columns should be processed.
Next, apply the calculations you already established. Those seems to work fine and are manageable. I don’t immediately see a reason to approach that differently.
If you end with a Loop End (Column Append), all the processed results from the loop iterations will be outputted.
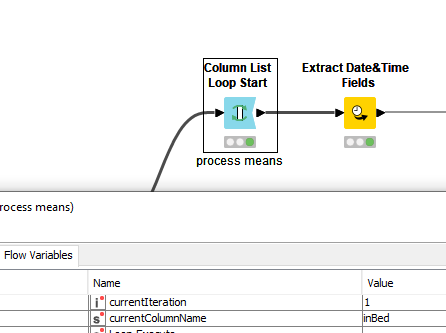
Important to note, the Loop Start automatically keeps track of which column it is processing in a flow variable.
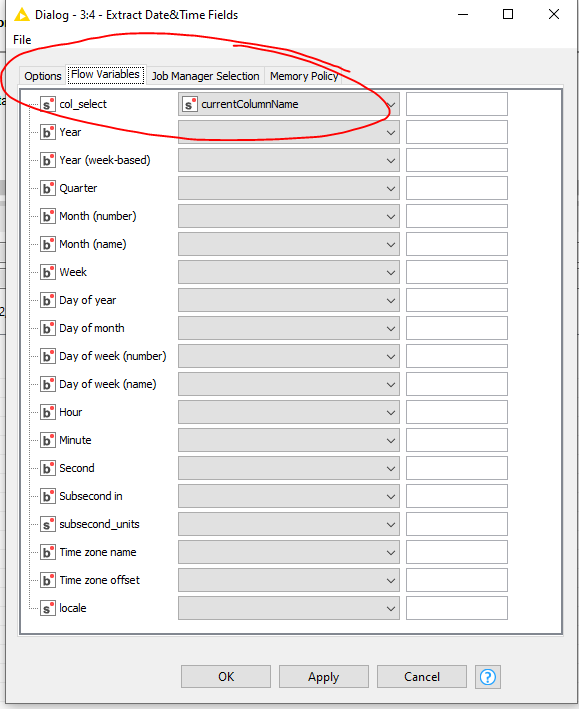
Make sure that you use this throughout the nodes within the loop. This ensures that all columns entered in the loop are used properly. Navigate to the flow variables tabsheet of a the nodes and find the equivalent entry for the current column and apply the default flow variable currentColumnName.
Dear @ArjenEX,
Thank you so much for your time and effort for preparing your post.
I made the steps, as you suggested, and like the result very much! That was the first time of me using a Flow Variable, and now I understand the practicality behind it and like it so much.
Next time I will try to prepare also a minimal data sample for making it easier to prepare an answer. Thank you again for your effort and details during your answer, this helped really a lot.
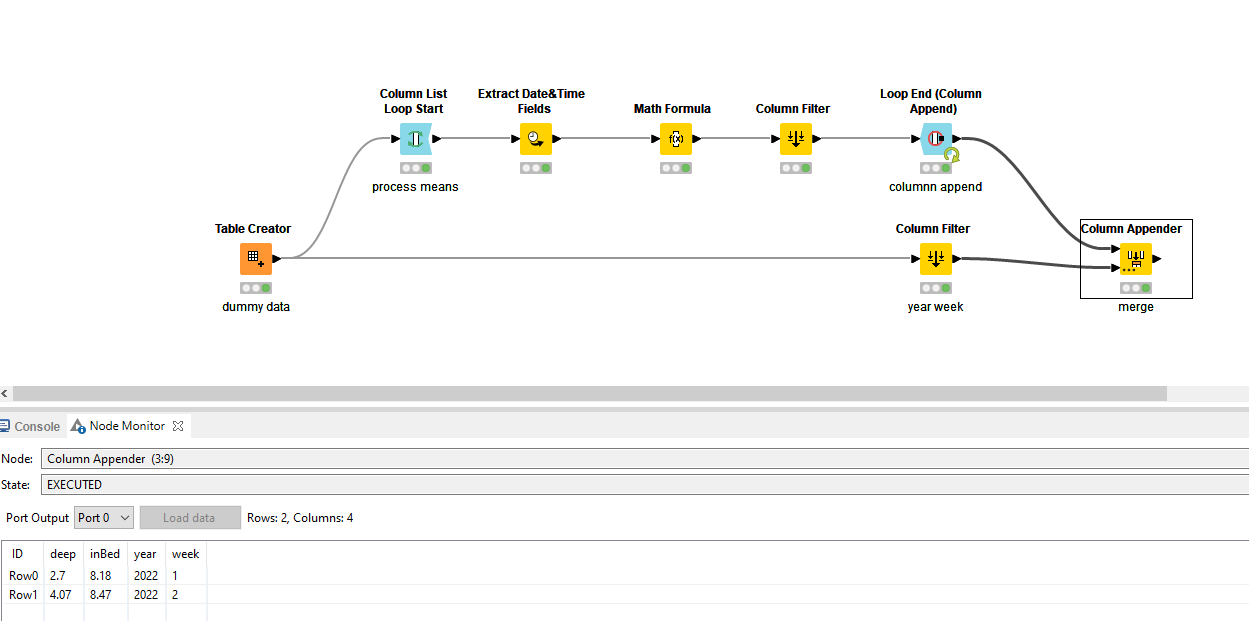
I could even include more operations in the flow, and it stays nicely manageable:
Maybe out of interest in terms of efficiency, could it be that the Loop will not be as efficient as a component or metanode? I could imagine that the component and metanode is executed in parallel and the loop will be executed sequentially.
But, currently, I do not have any time constraints and therefore the loop is perfect.
I wish you a good week, and thanks For the help.
Greetings Alex
Generally speaking yes, but this will always be a trade-off depending on your use case. This is driven by factors like; the amount of data that you have, the type of operation you are performing within the loop, the amount of columns you are putting into the loop, etc.
In your example, we are probably talking about milliseconds. Then the manageability aspect comes around the corner which favors a column list loop rather than maintaining those 3 indentical data flows in a metanode.