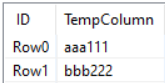
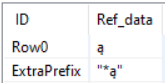
Output of Column Rename (Regex) node with a single column of data
Output of Transpose node with a single column of data
I’m getting the following error message: Invalid data table column. I think that Transpose node generates the output that is not recognized as table by Reference Row Splitter.
I’ve tried to use Table Column to Variable node, however it generates empty table
Any suggestions on how to prepare reference table properly?
Thank you in advance for any support,
Kaz
Hi Kaz,
What type does the Ref_data column have? You can open the table output view of the Transpose node and check in the “Spec” tab. I assume that it is not “String” like it is for the “TempColumn”. What you can do to fix it is to add a String Manipulation node after the Transpose and use the expression string($Ref_data$) to convert the column to a proper String column.
Kind regards,
Alexander
This indicates a problem with data table and not reference table. I have tested it a bit and seems Reference Row Splitter (and also Reference Row Filter) don’t like changing column names (both data and reference) after being configured. Then you need to reconfigure them which obviously isn’t cool if you want to automate something with flow variable holding column name. Would call it a bug.
From the top of my head can’t come up with a workaround. Maybe Alex will come up with something.
and before going into further investigation I will revert my approach: instead of looking for root-cause of the issues, I will start from the very beginning.
My sample input data is:
Index
Data1
Data2
Data3
Data4
aaa111
djąej
irut
erwiuj
gisjer
bbb222
fdsnf
dudą
wrejr
htrjyt
ccc333
sdn
rqruj
ąewru
hrtw
ddd444
htdyh
rydhy
uyk
eraf
Reference data is: Ref_data
ą
ć
Expected output is:
Index
Data1
Data2
Data3
aaa111
djąej
bbb222
dudą
ccc333
ąewru
Please note that real life reference data will contain single characters as well as words and phrases.
What could be the workflow to generate expected output?
I’m sure I’m making some silly mistake.
Hi Kaz,
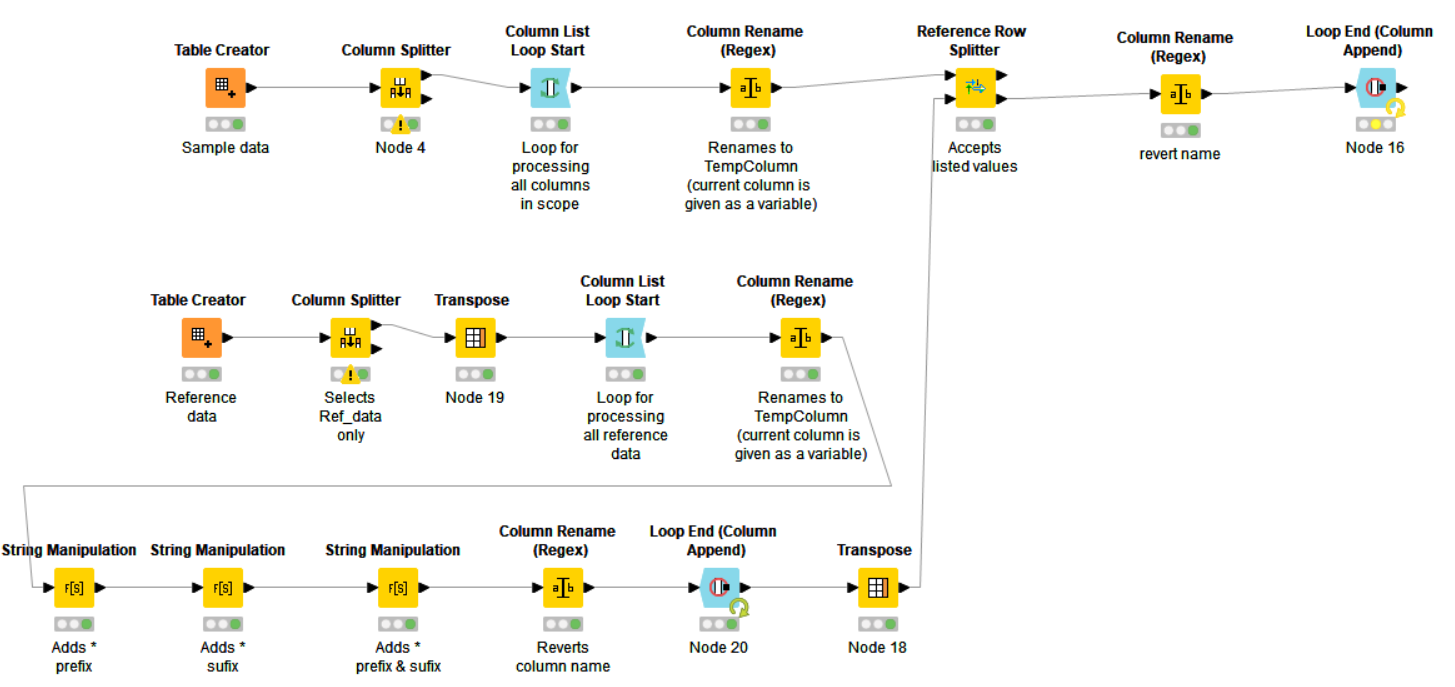
I think you are much better off using Unpivoting and Pivoting for this. This makes it easier to treat each cell. Please have a look at the workflow I just uploaded to KNIME Hub: Filtering Cells containing String – KNIME Community Hub.
Kind regards,
Alexander
Hi @AlexanderFillbrunn
Your workflow works like a charm! Thank you so much.
Now, I need to learn more about unpivoting and pivoting in KNIME.
Happy KNIMEing,
Kaz