I am trying to use the Tree Ensemble Learner node for feature extraction.
The target column is not showing columns that have newlines in them. Unfortunately, the data that I downloaded has newlines. On the other hand, the Include/Exclude filters are showing those attributes.
(Side note: it would be nice to have a search/filter option for the target column just like include/exclude filters. there are way too many columns in my dataset)
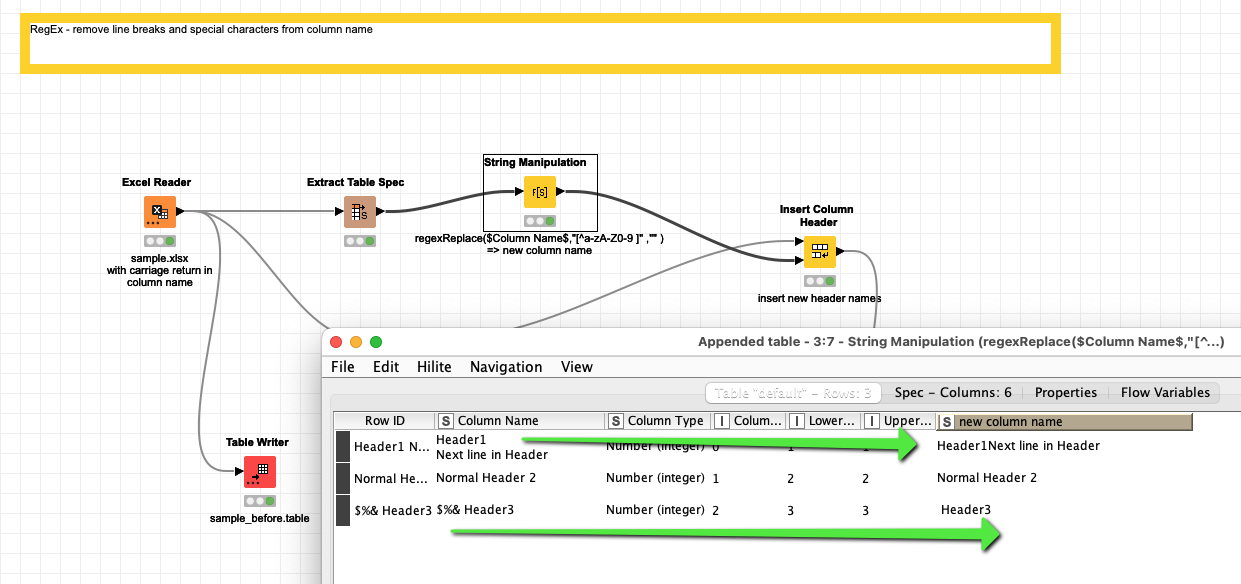
@tims you could use a regex function and a “Insert Column Header” node to clear your variable names. The logic is you remove everything that is not explicitly permitted. In this case a blank is OK. You might edit that to your needs.
@mlauber71 your solution worked excellently in removing junk characters from column names. However, I still don’t see the column of my interest in “Target Column” dropdown of “Tree Ensemble Learner”
It is of double data type and is visible in the “Insert Column Header” node, all special characters gone and with only alphabets and underscores in it.
Is there any other reason why a column name would not show up in the “Target Column”?