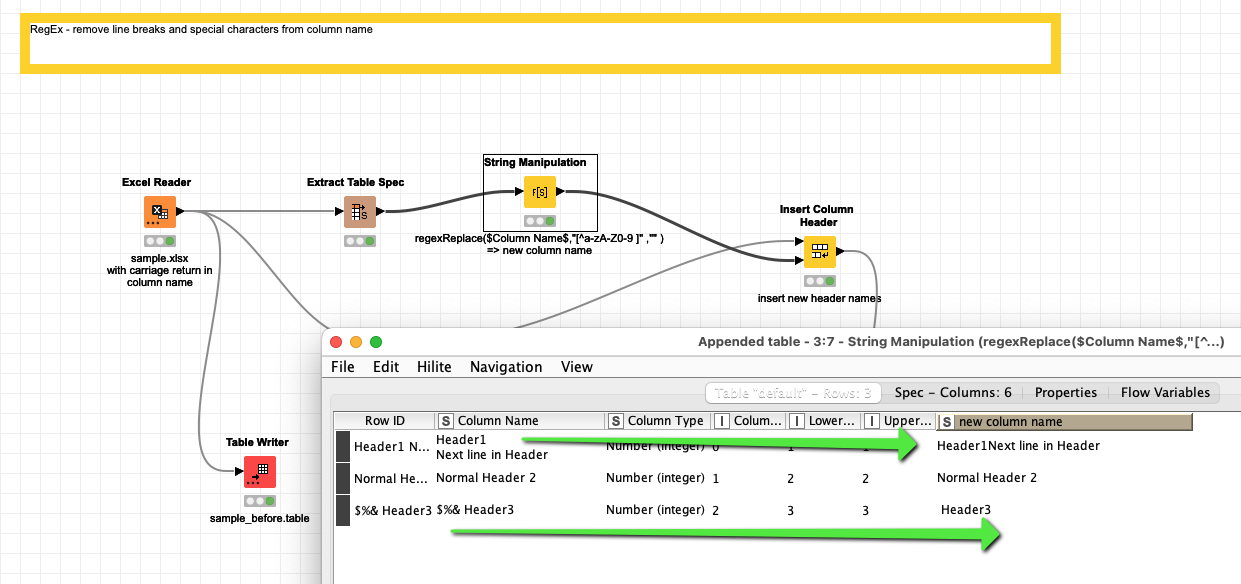
@tims you could use a regex function and a “Insert Column Header” node to clear your variable names. The logic is you remove everything that is not explicitly permitted. In this case a blank is OK. You might edit that to your needs.
regexReplace($Column Name$,"[^a-zA-Z0-9 ]","")