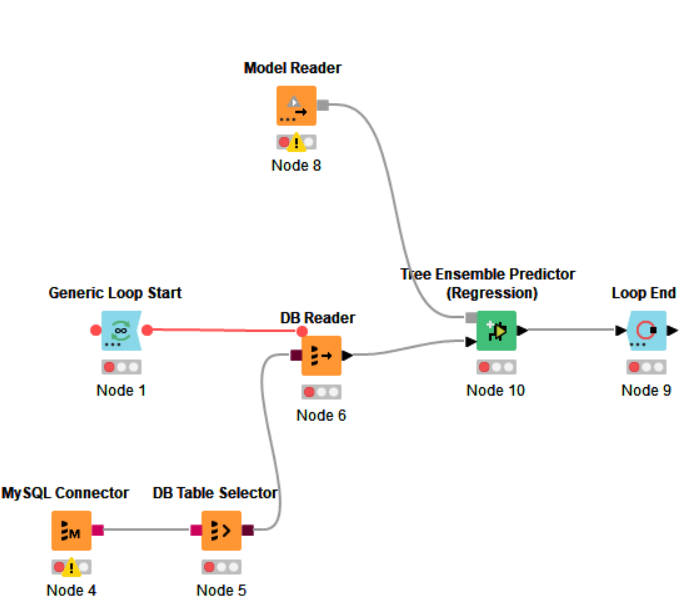
I have a time critical loop in which Tree Ensemble Predictor (Regression) is executed within the loop.
In each iteration of the loop, the predictor is applied on few records using the same Tree Ensemble model.
The trees model, is quite a large model, but keep the same within each iteration, and is not being reset between iterations.
it appears that the Tree Ensemble Predictor (Regression) requires a significant setup time in each iteration (few seconds), although you would expect such a setup time to be applied only in the first iteration.
Could you please consider that issue for next version,
Or suggest any idea on how to bypass that latency issue?
@gmoran could you give us an idea how large the model is and why you only apply a few lines per loop. Would it be possible to apply the model to more lines. Also you could check the memory in your KNIME installation.
Even if the model is being loaded outside the loop the node applying it will have to reload every time the loop executes.
If you want to do this operation by chunks streaming might be another option to explore.
Hi @mlauber71,
The model is ~100MB in size, the the node setup time is very reasonable, only thing is that it repeat on each iteration,
There are only few lines per loop, because my mission is to read new records from DB, apply scoring on them and save results as fast as I can.
It works perfectly with KNIME, except of that setup time, on each iteration.
Do you think KNIME is the proper tool for that, or should I try other tool in which such a setup time is not required on each iteration?
@gmoran maybe you can provide us with a screenshot or a sample file of your setup. I think every tool will have to load and provide the model being used. You might try to keep the loading outside your loop (which you did?). But a large model will always have to be loaded. If you have a model that supports PMML you could try to compile it and gain some speed.
Or you try another model like from the H2O.ai family that support compressed models. More options:
Sure,
see a simple demonstration screenshot:
The issue is that you expect all initializations (done internally) within the “Tree Ensemble Predictor”
Node to be done on the 1st iteration, and the next iterations to be very fast, because it is using the same model. however analyzing the execution times, it appears that the few seconds of initialization happen in each iteration,
Hope the issue is more clear now.
Do you think KNIME is the proper tool for that, or should I try other tool in which such a setup time is not required on each iteration?
I´m not really sure. How does KNIME internally handle the memory and loading of the model? Is it read the model from disk (model reader), hold it in memory and than in the predictor node initialize this node with the memory (Tree Ensemble Predictor)? If this is the case and the issue seems to be the initialization, than KNIME seems not to persist the initialization between loop runs (which is sad).
In other languages/systems you load the model, initialize it and hold the initialization in memory so that when you want to make a prediction everything is ready and fast.
But before we blame KNIME let me ask you why you use a “Tree Esemble Predictor” and why the model is so big? Could you share Tree and Esemble Options of the learner? Maybe and alternative is to use something that provides as good as and prediction result, but is much smaller (for example Gradient Boosted Trees)
@gmoran I think the way you set it up will cause the Reader to always re-read the model. You could try to force the placement outside the loop and make sure the model is being cached in memory. You will not be able to avoid the setup within the Predictor since this is what this will do.
Hi Paul (@goodvirus),
Indeed, the issue is with the initialization that seem to be not persist between loop iterations,
And was hoping it can be fixed in a future release.
The reason for using Random Forest (Tree Ensemble) is being a stable and most accurate model after we tuned and optimized its options.
The reason for preferring it over “Gradient Boosted Trees” is the need to optimize the options (e.g. number of trees) when new training data is introduced to the model with “Gradient Boosted Trees”, but with Random forest, the new data improving accuracy with no need to perform new parameters tuning.
Hi @mlauber71,
Nope, the model reader is placed out of the loop and hence being called only once.
The reason for iterating over the DB reader, is because in each iteration, only new records are fetched (i.e. records that hasn’t existed in the previous iteration few seconds ago)
How do you measure the time the -Tree Ensemble Predictor (Regression)- node is taking per iteration?
I would suggest to add the -Timer Info- node within your loop just before the -Loop End- node and add a second input to the -Loop End- node to gather the -Timer Info- node tables:
This would allow to have a more precise idea of what is going on (execution times) in your loop declined by node execution time over different iterations.
Once it is implemented, maybe you could share here the resulting -Timer Info- gathered information in Excel format so that we can better understand what is going on. This resulting table should already help you to better analyze the behavior of your workflow.
Hi Ael (@aworker),
Indeed, I am using Timer Info for analyzing the execution time,
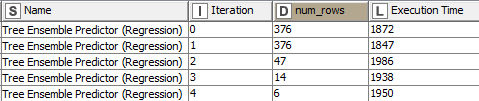
Please see results:
I added a column, num_rows, indicating how many rows were processed in each iteration.
From the results, it appear that most of the execution time is devoted to set-up.
We can tell, because the execution time is not correlated to the number of rows processed.
It is very inefficient, and expected that such set-up time would exist only in the 1st iteration, because all iterations using same model, whose port is not being reset between iterations.
Hi @tobias.koetter and team,
Yet struggling with this, could you please assist,
The issue is simple,
There is high set-up time latency of “Tree Ensemble Predictor (Regression)” within loop iterations although the model remains the same and never been reset between iterations.
Could you please consider a fix such as the node would require such a set-up time only in the 1st loop iteration and skip that setup on the next iterations in case the model was not reset?