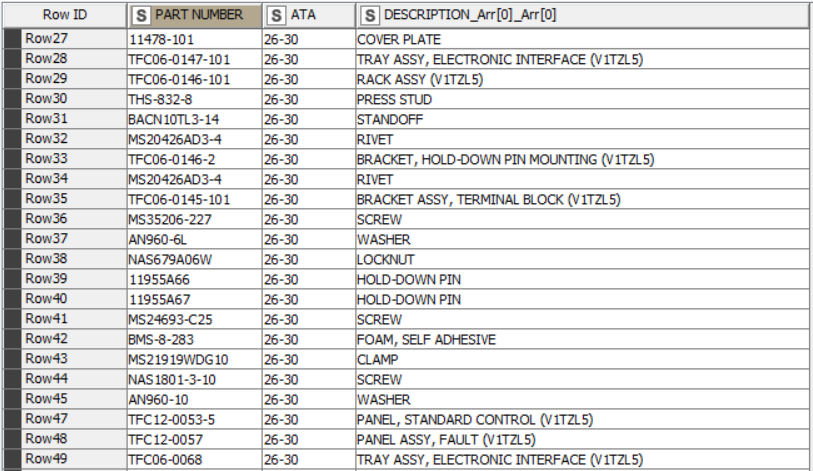
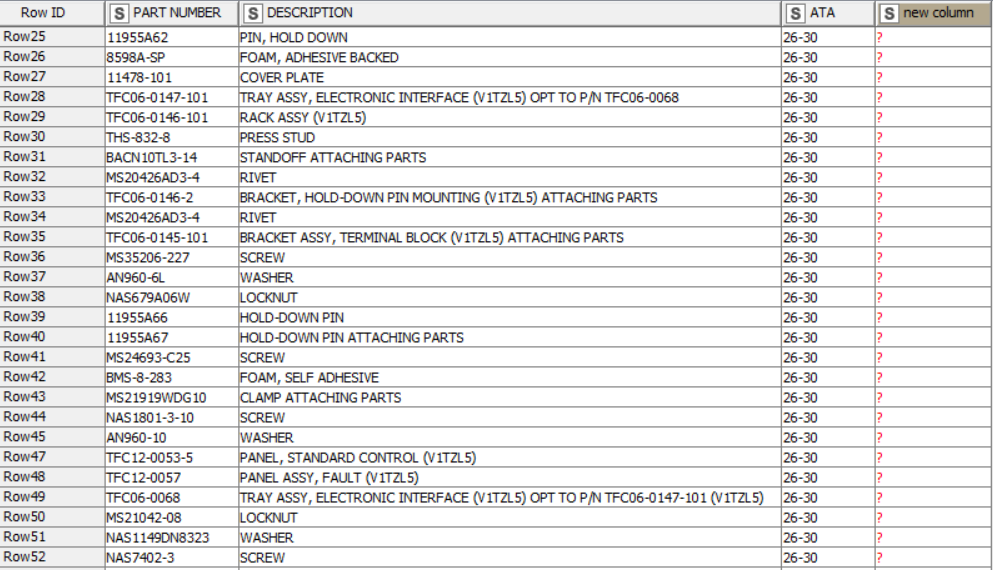
and I want to filter the strings from the column “DESCRIPTION”, by removing everything after certain words. In the example above I want to trim the strings after the words “ATTACHING” and “OPT”. So the output would look like this:
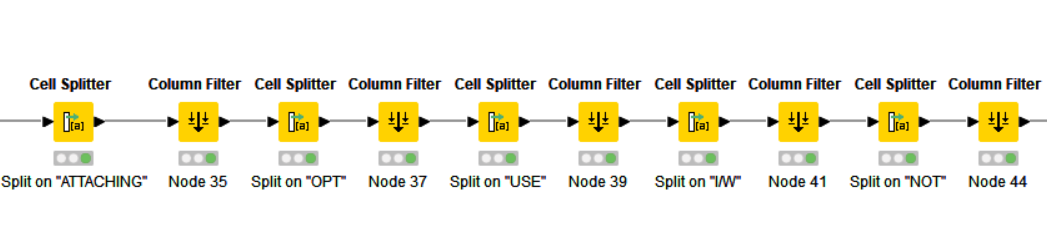
For this, I used the node Cell Splitter, where I split the “DESCRIPTION” column on those words and then keep the first column and delete the second one. Something like this:
However, as there are a lot of words that I want to trim on, this method becomes inefficient. Any ideas for a better way to do this? Ideally, I would provide a list of words as input and based on all these words the strings would be trimmed. The workflow that I used and the input file can be found below.
hI @mmelbaghdadi ,
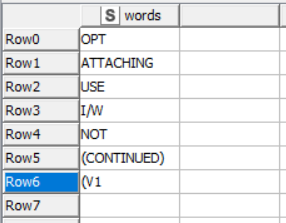
maybe this workflow can solve the problem. The words “ATTACHING”, “OPT” etc. must be written in a table, then they are concatenated using the “pipe” as a separator. The resulting string is used in a regexReplace expression KNIME_temp.knwf (11.9 KB)
I tested the workflow, it indeed worked with words. Unfortunately, when I used inputs such as: “(V1” and “(CONTINUED)”, it removed the whole string. I assume this is caused by the parenthesis. Is there a way to trim these inputs as well?
you have parentheses in your “words”. Parentheses (every kind of) have a special meaning inside regex, so you have to escape them inside the string you’re looking for, preceding them by a backslash: \( So for example “(CONTINUED)” must become “(CONTINUED)”. Same is true for other special characters, such as “?”, “*” and “.”.
you are searching for both whole words and first characters of words, and that changes the pattern to be searched for by the regexReplace expression. Try replacing it with strip(regexReplace($Description$, "^(.*?[\b| ])("+$${Swords}$$+").*$", "$1"))
Hi @duristef thank you for your response. I have used the new expression but for some reason it still deletes the column.
Here is your workflow (adjusted): Trim.knwf (12.1 KB)