Hello, I am new to KNIME ,trying to create my first workflow and having trouble loading the data into CSV Reader. Getting this error message
Execute failed : New line in quoted string (or closing quote missing). in line 2
Data set info as follows,
memory usage: 31.2+ MB
RangeIndex: 289331 entries, 0 to 289330
Data columns (total 15 columns)
dtypes: bool(1), float64(1), int64(1), object(12)
Hi @HakobAvjyan -
Have you tried using the File Reader node instead? It’s a little more robust about dealing with inconsistencies in CSV files.
1 Like
Hi Scott, thanks for your response.
Yes !
File Reader works fine and it loads the data set, but I am running into a different issue, unfortunate it doesn’t recognize the data structure, instead of 15 columns it combines everything into one column.
I tried to modify the column delimiter , but that didn’t help .
Are you able to post a small example file, or is the data proprietary?
2 Likes
My experience is that sometimes you could import ‘messy’ csv files with the help of the R package readr.
2 Likes
I haven’t tried to shrink the data set yet, but for the sake of the end result it is important to be able to examine the data in its entirety and yes the data is proprietary .
Thank you ,
I am trying this out now, but looks like the List Files node dose not recognize CSV format files …
Getting Error message while executing String To URI
ERROR String to URI 4:17 Execute failed: java.lang.RuntimeException: The file to the URI “file:/C:/Users/HAvjyan/Desktop/KNIME/knime-full_4.0.2/number,description,short_description,category,state,active,activity_due,additional_assignee_list,approval,approval_history,approval_set,assigned_to,assignment_group,business_duration,cmdb_ci” does not exist
The List Files node definitely supports listing of CSV files, so there’s something going on with the configuration here.
It looks like you’re somehow passing the header of your file as part of the filename…?
Are you able to successfully execute mlauber71’s workflow using his data (not your own yet)?
1 Like
I think you would have to provide a location where the CSV file is located. I modified another example, maybe you could have a look:

1 Like
So somehow , in Row ID I have a Row0 and its corresponding values are my 15 column names and it’ s under Col0 …
I downloaded mlauber71’s workflow but it doesn’t have data , when I try to load my data I run into new errors.
That sounds like improper parsing of column headers. If you’re using the File Reader node, make sure you check the box to read column headers, and then examine the preview window closely.
mlauber71’s workflow does come with data - I was able to execute it myself. The problem you might run into there is if you don’t already have the R readr() package installed.
If you’re able, it would help us a lot if you can post an example workflow with a dummy dataset. That would make troubleshooting much smoother 
2 Likes
Like @ScottF said, you might try to get the File Reader working by trying different configuration and see what the preview window shows.
If you actually have R installed and the readr package you could try to use an R Source Table node with a more simple code.
library(readr)
file_location <- "C:/Users/HAvjyan/Documents/my_data.csv"
# enter the correct delimiter like , comma ; semicolon, | pipe
knime.out <- as.data.frame(read_delim(file_location, delim=",", col_names = TRUE))
2 Likes
thank you so much , I downloaded r_read_single_csv_file workflow and trying to pass the file path in R Source Table , but getting a new error 
Error: ‘\U’ used without hex digits in character string starting "“C:\U”
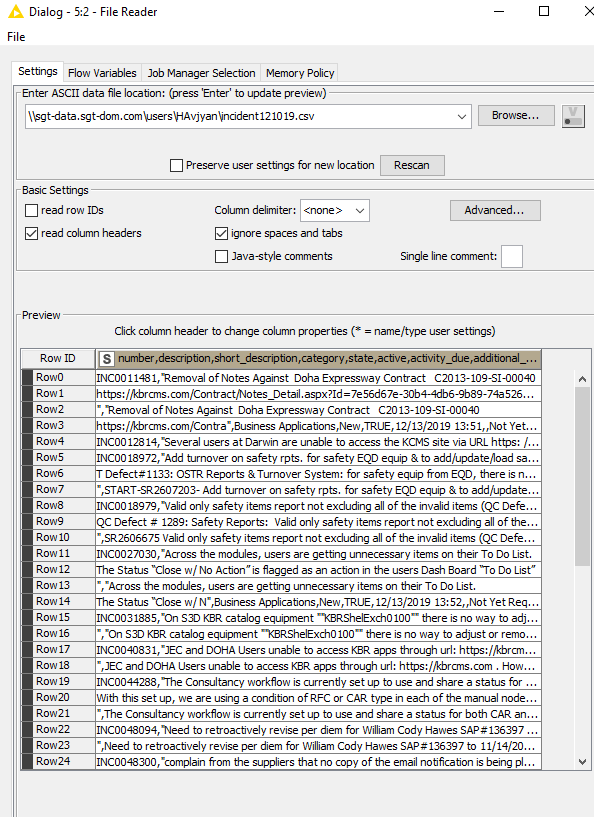
Thank you Scott ,
I am selecting read column headers and this is what I am getting, all of the column headers are merged into into one column
The c: … was just a guess from my side you need to enter the correct path.
From the screenshot the data looks super messy with comma as separator and then some text some quoted text and also it seems data could run for more than one line for a single case that seems to have an ID starting with INC…
You will have to determine with a good text editor what is the structure and what are the line delimiters (carriage return or what). It might be necessary to read the whole thing as one text column and split it later or write some sort of parser.
Without seeing the original data or some data closely representating that you will have a hard time getting it anywhere.
You could try to make readr work. Or you might ask your source for a different format or a better delimiter like pipe (|). We used to use the ASCII 164 (¤) the ‘flat turtle’ back in the days to safely separate CSV file columns.
2 Likes
Looks like a CSV file with comma as a delimiter containing multiline entries (each new “row” begins with “INC<number>”). That’s why the data looks so messed up in your screenshot.
In order to load something like this, first set Column delimiter from <none> to “,” (comma) in the dropdown menu.
Then click on “Advanced…” and in “Quote support” tab enter double quote (") as a quote character.
You might also want to check the option “support esc character”.
Make sure to “Add >” so that the double quote (and escape) character is listed under “currently set quotes”)
Also enable “Quoted strings can extend over multiple lines”.
Click on OK and the Preview should already look much better.
6 Likes
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.