Hey there!
I’m currently trying to replicate an algorithm regarding Network Anomaly Detection, based upon cascading K-means and the C4.5 decision tree. It’s actually my first time using Knime, up until now I have only worked with a couple Python libs.
Sadly I’m not able to progress successfully with my current workflow. I’m trying to cluster the WIFI on ICE (Deutsche Bahn) dataset based on geodata and ping, but I have not been able to replicate the mentioned algorithm correctly and would appreciate some help. Apparently I keep feeding the correct information into the decision tree learner unintentionally, which results in a 100% accuracy rate.
Thats the current workflow:
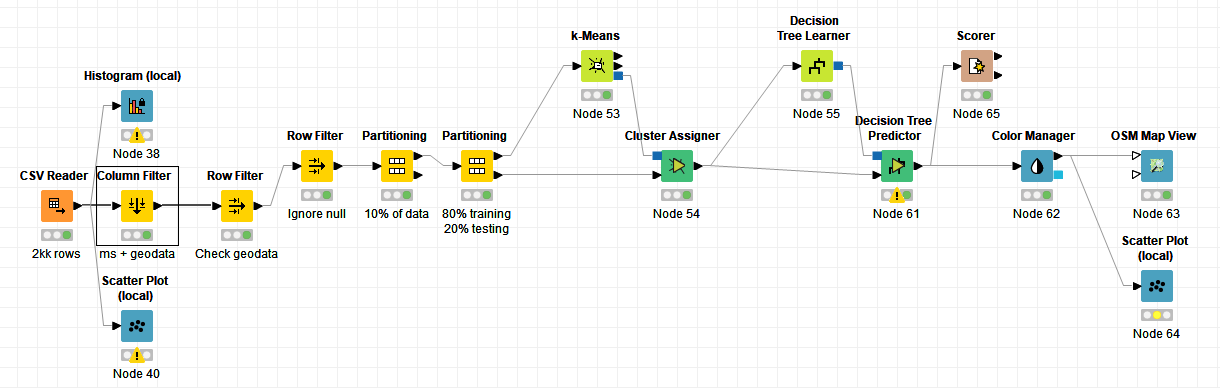
Thanks in advance!