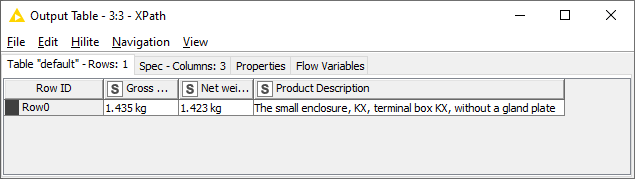
I have an Excel list of products with article number, the products can be searched by the article numbers on the company website. I would like to add columns of product description and weight to the excel.
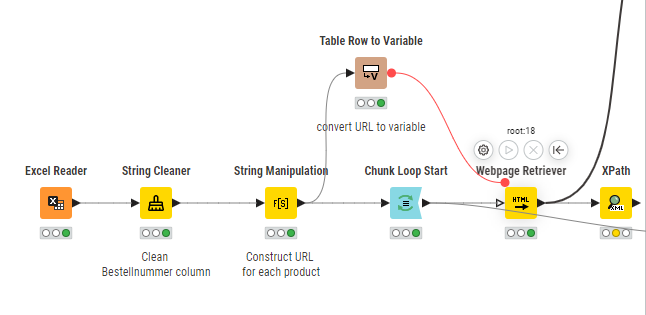
My current workflow looks like this
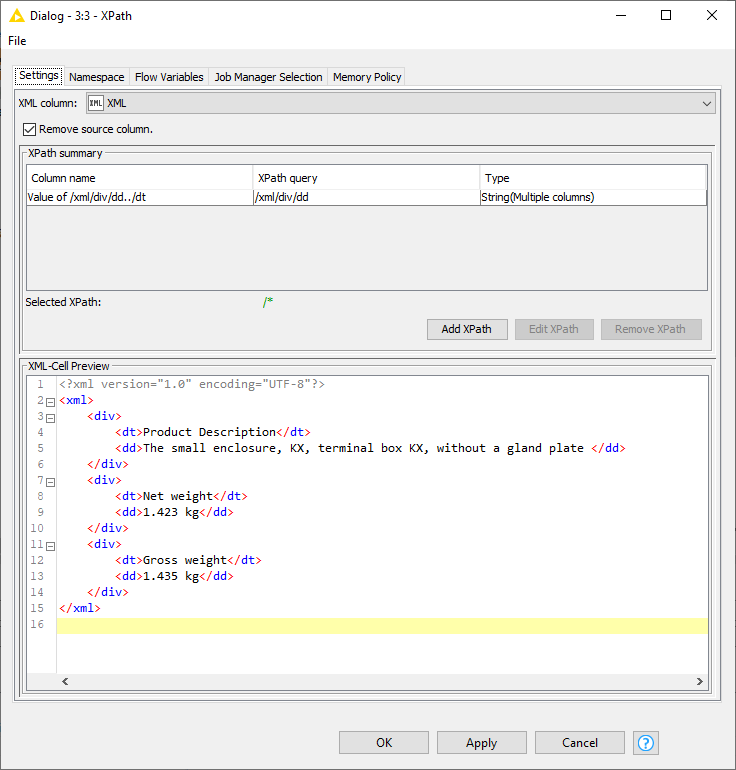
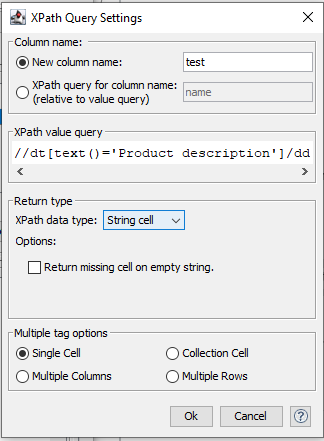
Now I’m stuck on the XPath node as I cannot find the correct XPath expression to get the information I need. (Error: selected XML element is not a tag nor an attribute)
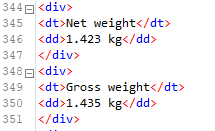
The XML of the information I want to extract looks like this:
Would be great if someone can give me suggestions on how to solve this.
Are there other ways to extract information from websites?
Hi
thank you so much for your reply. I actually don’t know how XPath works (don’t know how to make sense of the structure of an XML file), so I asked the KNIME AI assistant to suggest me a XPath query
Here is what it suggested, and it didn’t work out:
Update: I have read the basics of XPath from W3School. Then I made several attempts to find the right XPath query, but failed.
The webpage XML is quite complex and I am not sure which levels should be included in the XPath query and which can be neglected.
Is there a best practice to define XPath query from complex XMLs?
Thank you.
I have looked at your case. I see that the issue comes from the fact that the GetRequest / Webpage Retriever Node not producing an XML column, but rather a string column instead, which in this specific case is not parse-able to JSON/XML.
Trying the KNIME Web Interaction (Labs) on this was a success for the first time on a non-headless browser, and then fails the second time due to Cookie wall. Seeing examples of workflows on the hub on how to get around that is by knowing the Cookies Xpath beforehand, which I have no idea how to obtain that info.
If someone here could help you on that issue, you would head into the right direction.
If you’re still not able to solve this after a few days, tag me and I’ll give you an alternative route:
Hello, thank you for your reply.
The output of my WebPage retriever node did return a XML column, so I didn’t think it could be the problem, is it not in the right format?
The XML column generated in this case barely works, probably since it’s not of a valid structure. You’ll get a valid one with the different routes I mentioned in previous reply. (Also, a python route could also be viable).
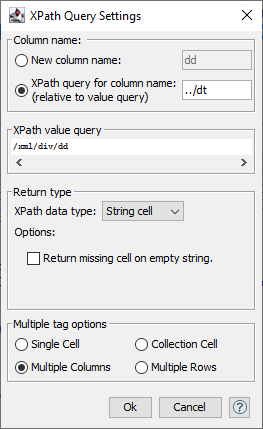
Alternatively, there’s also a manual route (without Palladian), but I wouldn’t recommend it since if you encounter an issue in the future, you’ll have to have some HTML knowledge and be able to identify patterns to fix it. Here’s what I get if I break things down manually:
Ok got it, thank you so much for the insight. I have installed NodePit and Palladian. Would be glad to learn the alternative route.
And yes, there’s so many possibilities in KNIME and so much to explore!
As you can see, there are possible “outliers” in certain webpages. Rest assured that this has nothing to do with the way the Xpath query is done here. Rather it’s because the webpage adds two additional rows in their table for that particular page, making it to have a slightly different layout than the rest.
You will need to inspect your results before you export them to your Excel file, otherwise you’d end up with these outliers.
To deal with the outliers, you’d have to manually isolate the affected rows from the output, and re-run the workflow with a different Xpath query, which I think you’ll have no trouble doing it on your own, but let me know if you need help with that.
Update @HSCH , use this revised version if you’d like to manually inspect for oddities. It returns all rows containing the strings that you want regardless of how many copies there are in the corresponding webpage table, and regardless of which row position they are located in for cases where the page has more rows than usual.
In this case, the table has two rows with the substring “Product description”, while just one row for Gross weight and Net weight.
Using this info, you shall configure the last node (GroupBy) accordingly. Suppose you want the last non-missing row for the Product Description, here’s how you do it: