I have been working with trying to implement the Try-Catch error handling process in an existing workflow which is working but needs error checking. The routine is working, so no need to troubleshoot that, all I need is to comprehend how I can include all nodes within a Try-Catch.The connectors for the database nodes all exist and work, they are just not pictured. I am struggling with which Try-Catch type to use and how to connect the nodes. The SQL Executor in the “Error Actions” block writes a failure flag to a db table. I’d like that to only happen upon an encountered error. One of the points of confusion seems to be that it appears both branches before the catch get executed, but the catch carries forward the appropriate path. Is that accurate? If so, wouldn’t my SQL Executor on the error branch always write the failure to the table?
Can anyone provide some direction here?
Thanks…MV
Workflow
You might be able to work around this by writing a flag to e.g. a flow variable in the error actions part of your workflow, and then after the Catch Errors node, use an If Switch (Flow Variable Value) node to only write to the database if that flag is set
Steve
I understand what you’re saying, and it is a good plan, but my first challenge is knowing an error occurred. I can’t set the variable unless I can trap the error, right? or is there another way?
Use the try/catch nodes, and in the catch node, select the ‘always populate error variable’ option, and then put in appropriate defaults:
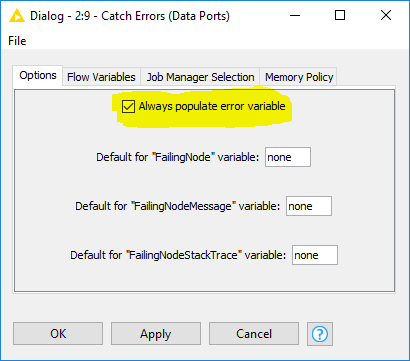
I think that should then let you do what you want
Steve
Which try catch nodes? DB Port, Data Port, or Variable Port? This is my biggest obstacle. All have issues with connection given my workflow…thanks Steve!
Looking at your workflow image, if the Database Reader node annoted ‘Get previous 14 days…’ has no input connections, then I think connecting a Try (Variable Ports) node to the hidden flow variable input port would be the way to go. You would need to connect some sort of flow variable input to the try node - you could make one with e.g. a Java Edit Variable node (possibly putting some sort of default flag in here, or maybe doing nothing at all!). If you actually have a connection to the incoming database port, then you made need to put the preceding nodes in the try section too, as there doesnt appear to be a database connection or ‘Generic Ports’ version of the try nodes.
As for the ‘catch’, you could use either the Variable ports version of the catch node, attached to the output side flow variable of the database writer, or the ‘Generic Ports’ variant if you want to propagate the database connection through the catch. I think the former is more likely to be what you want.
Incidentally, the SQL Executor node is annotated 'Remove previously retrieved records - have you looked at the Database Delete node, which outputs some information at the end of each row as to whether any rows were deleted? That might simplify things depending on exactly what you are doing.
Finally, I’ve seen an issue where some databases “break” workflows if a read transaction fails because the table does not exist. We are hoping to release very soon some ‘IF switch’ type nodes which switch output branch depending on whether a table exists or not. If that sounds useful in your case, then let me know and I will comment here again when it is released.
Steve
1 Like
Steve,
This is helpful, thanks. One thing I was not sure of was if I could mix the try/catch types. So for instance, start with a Try (Var ports) but use a Catch (DB ports) at the end. Your solution sounds great and I will try it today.
On the DB Delete node, I’ll check it out. I am using logic to crrate a date range but nothing that wouldn’t work in a standard DELETE FROM query, so it should work. Thanks for the tip!
Best…MV
1 Like
Yes, you can mix different try/catch types (simliarly If/Case and End If/Case types, and many loop start/ends)
Steve
Steve,
I have been trying to make this work but I can’t seem to get the catch (var ports) to recognize my Java Variable set in the error flow. If I look at the variable outputs for the Java Edit Var node, I see my errorCondition = true. In the Catch node both output and failure branches see the variable but remain with a false value. For some reason the Catch node is not inheriting the flow values from the fail flow despite errors occurring and a direct link of the variable ports. Any thoughts? Thanks…MV
I’m guessing that what you are seeing is a result of the caveat which is in the node dialog in the Flow Variable End If node:
NOTE - Due to the way in which flow variables are handled within KNIME, no matter which the active branch, the flow variable values for any existing flow variables beyond the corresponding “end” node will be those at the top-most port of the “end” node. New variables created in any active branch will retain their correct values. If you need to change the value of existing variables, please either use a new flow variable, or use a variable to tablerow node before a conventional End IF node.
Basically this is a feature of KNIME which there is no avoiding - your best bet is to try one of the options described there, which is admittedly pretty cumbersome!
Steve
Steve,
Thanks for the help. Perhaps I’m out of line, but I would have to say that Try-Catch either needs some work still, or another error catching node needs to be built. The concept of what I need to do is very common, and should be easier. I want to wrap a set of nodes, if any nodes error out I want to trap and report the errors, while allowing the workflow to continue. I don’t see any alternate nodes that appear to do this. You have been great at trying to help me work around this, and that is appreciated. I just can’t believe there hasn’t been a bigger call for this. Anyway, thanks again!