Hi,
this is my first question in this community and I hope, I have chosen the correct place and topic for it. Otherwise, please give me a hint where to place such a question, thank you very much.
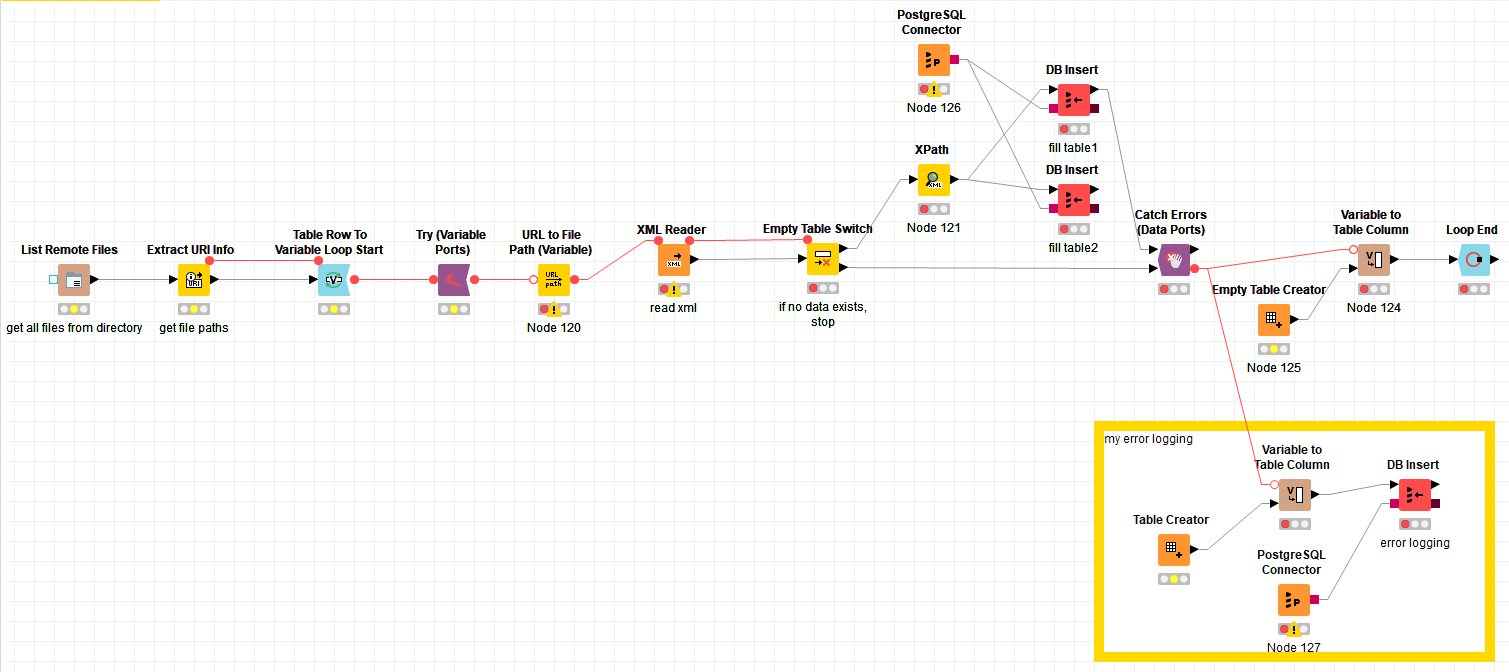
I have a question regarding try-catch constructions, especially w.r.t. multiple catch branches. I have created an example workflow attached to this post. The basic idea of that workflow is as follows: I want KNIME to list all xml files in a given directory and then loop over them in order to read each file and write some of its content into two separate database tables. All xml files have such a structure:
<example_data>
<aaa>value1a</aaa>
<bbb>value1b</bbb>
<ccc>value1c</ccc>
</example_data>
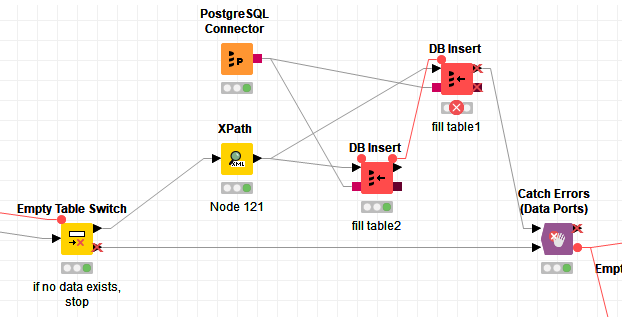
The workflow works correctly as long as my input xml files are correctly filled. However, there might occur errors when trying to write the data into one of the database tables. In order to simulate this, let us assume the database tables do not accept NULL values. As long as all my values are non-NULL, everything works fine. When aaa is not filled, the upper DB Insert Node (for table1) fails, but table2 can be filled correctly. Vice versa, when ccc is not filled, the lower DB Insert Node (for table2) leads to an error, but table1 can be filled correctly. I need a catch-construction hat catches both possible errors.
In the example workflow, I have created some own kind of “error logging”. For each file, some log information is written into a (third) database table. In case of any error, the catch-node should forward the error information and the subsequent nodes write that information to that log-table.
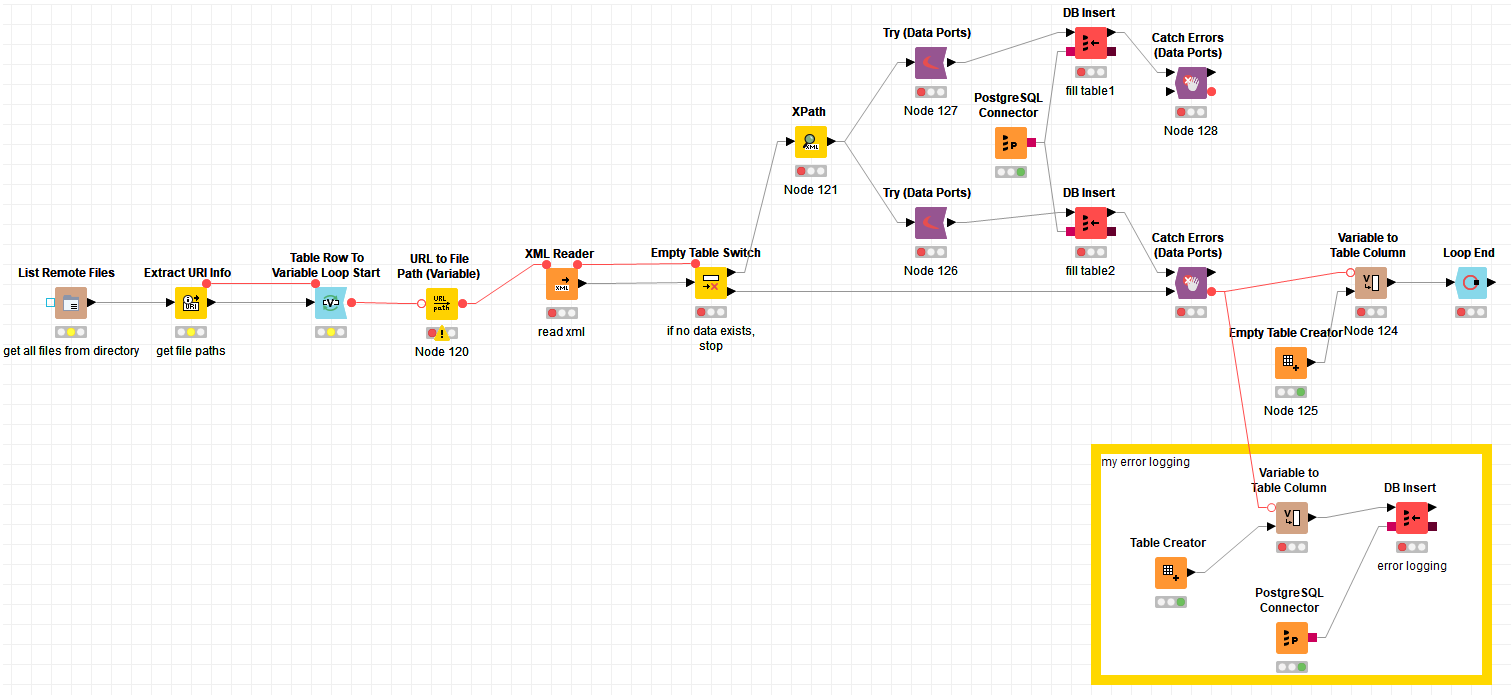
My problem: In my example workflow, the catch-node only reacts to errors w.r.t the upper branch (table1). Errors w.r.t. the lower branch (table2) are not detected and therefore do not show up in my log-table. I need a way to somehow give both DB insert outputs as input to the catch-node. Or do I need two catch-nodes (for only one try-node)?
How can I construct a try-catch construction for this example workflow that has the following properties:
- Independent of whether any errors occurs or not, the loop always loops over all files in the directory. (That is, when an error occurs, the workflow does not simply stop, but continues with the next file.)
- When an error occurs either w.r.t. to table1 or w.r.t table2, the error is catched by a catch-node such that it gets written into my log-table. If possible, it would be preferable to also log some information where the error(s) occurred (e.g., by getting their node ID(s)).
- When no error occurs, the log-table still gets a new line, but it only shows “-“ in the error-columns.
How can I achieve this?
Thank you very much for your help!
try_catch_example.knwf (49.7 KB)
minimal_example_data_1.xml (94 Bytes)
By the way, I’m a KNIME beginner, so my workflow might be overly complicated. If you have any suggestions how to simplify it (for example, w.r.t. the loop-end node), I’m happy to hear about it, too. Thank you.