Hi there,
I have issues understanding how to use the try-catch nodes within a loop.
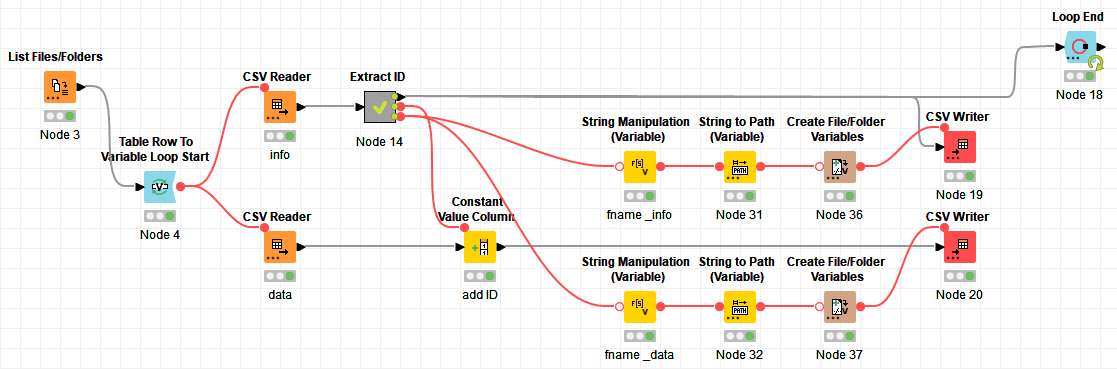
My task is to go through all csv files in a folder, load different parts of the file, perform some operation on it and save the result into two seperate files.
Want I would like to do: If there is an error somewhere in a loop execution, just continue with the next file. Would be pretty easy in Python, but I don’t know how to do it in KNIME. I tried to play around with different error handling nodes but the workflow never works as expected.
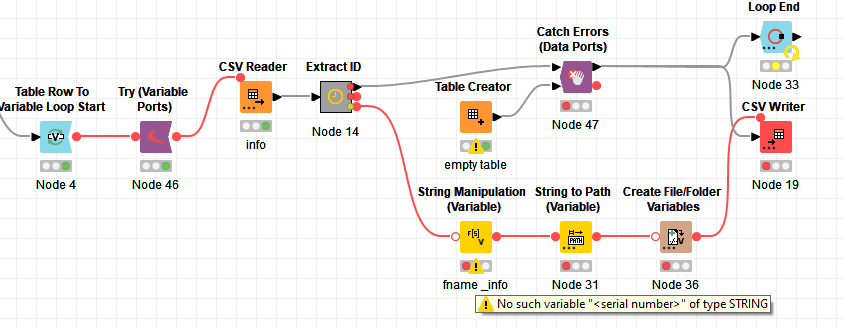
Any hints on how to achieve it? Here is a screenshot of my workflow:
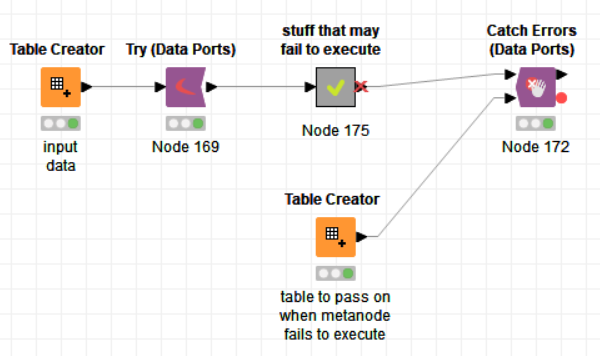
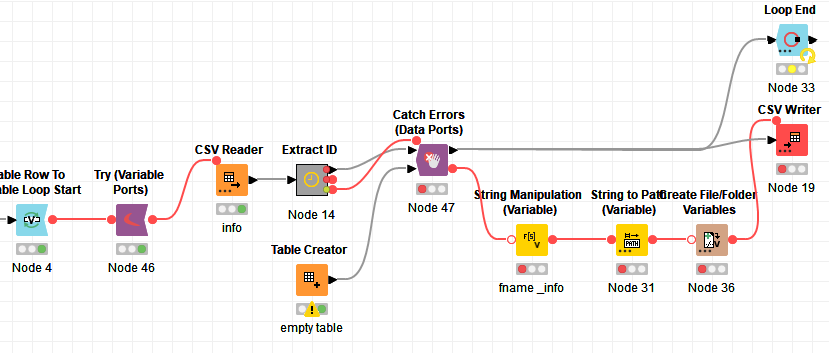
The easiest way would be to put the entire loop body into a try-catch block. I started building that, but then I figured you might not want to write the csv files in case of a failure? In the screenshot below you’ll find the general application of a Try-Catch block. The fallback table is mandatory.
What parts of the loop do you expect to fail? I can see 3 parts (reading, manipulation, writing) in each branch and depending on where something might go wrong, and what you want to do in that case, the solution will be different.
Or in more simpler terms: Are you fine with writing only one of the files, or would you rather have both or none?
Basically, I want to cancel the current loop iteration if any kind of error occurs within the 3 parts you have identified and not write any file in that particular loop iteration.
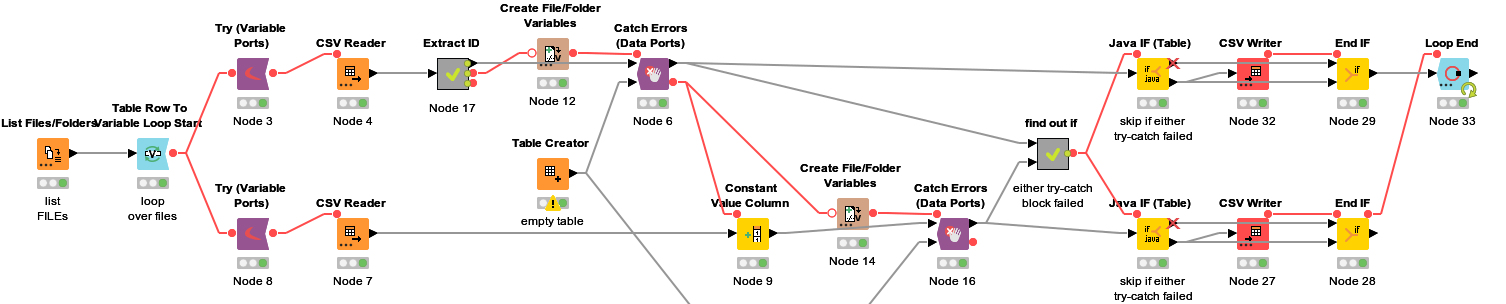
I tried to put the entire loop body in a try-catch block, starting from the beginning of my loop using the “Try (Variable Ports)” node. But then I don’t know where to put a catch node and which kind of node to use. Also I get an error in the csv reader node that the Path variable is missing (which should be propagated by the loop start node): Errors overwriting node settings with flow variables: Unknown variable "Path"
@Daniel_Weikert But then it could happen that only one of the files gets written.
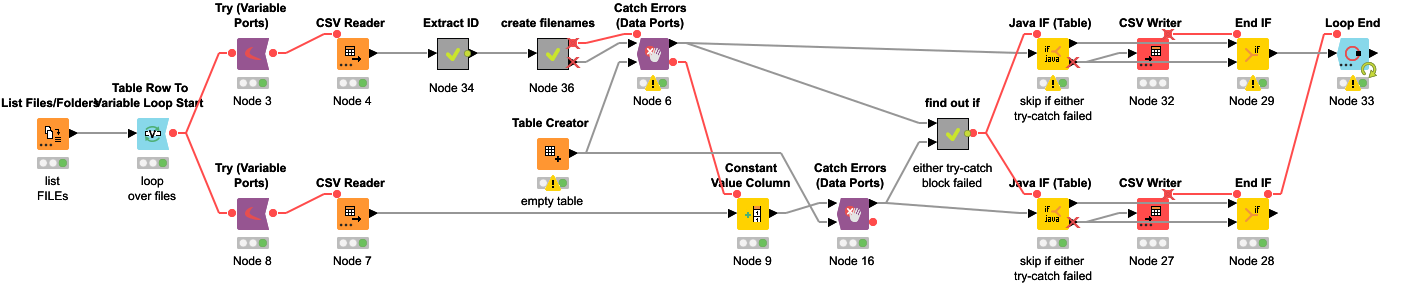
Here’s what I came up with. Maybe it could be handled better, I’m not using Try-Catch that much. The lower branch got pushed back a little because connections really can’t leave a node block.
Also, you’ll need to change the Loop End to allow changing table specifications or it will fail. Another option is to replicate the columns of the Extract ID Metanode in the table creator. The only thing that’s important is that the table stays empty, because the error detection would break and to prevent appending any data from failed iterations to the final output table.
Again, thanks for the help. The empty table check is a nice way to prevent that only one file gets written. Will definitely use it once the whole thing works.
I tried to implement it, but again no luck. For testing, I removed the nodes for the second file but I can’t even get a single try-catch path to work… apparently this is more complicated in KNIME than I thought.
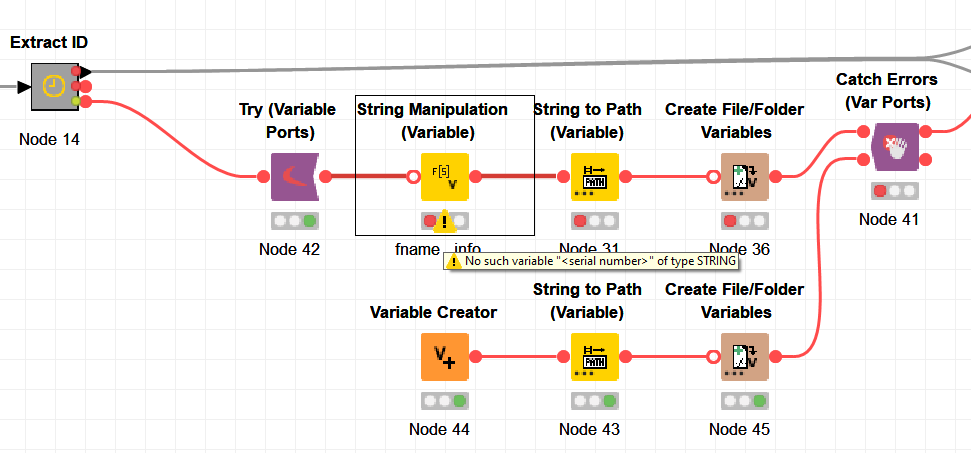
To simulate an error I removed the ID (serial number) from one of my test files. I have the feeling that the mix between variable and data ports makes it tricky. I tried every possible combination I could come up with, I have no idea why the error is not handled correctly. The execution still stops within a loop.
Here are a few things that I have tried:
Yeah, that’s because missing Flow Variables is a configuration error, not an execution error. The Try-Catch won’t trigger here.
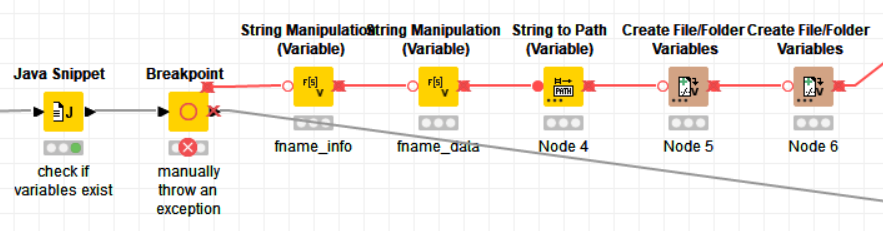
Usually I try to avoid using any of the scripting nodes in forum answers, but I’m not sure this is even possible without them. The idea is to manually throw an exception using the Breakpoint node. It deactivates the downstream nodes and can be remote controlled via a Flow Variable.
I have tidied up and put the filename creation stuff in a separate metanode. The first step is to check for the existence of all required Flow Variables in a Java Snippet node, using a try-catch block.
It stores the info throw/no-throw in a variable for the Breakpoint node.
After that, the following variable nodes will either be deactivated or execute normally.
I have seen though that the “Extract ID” metanode isn’t done executing. I don’t know what’s inside there, but you’ll probably need to move the Breakpoint upstream, or use another one. If you know Python, I’m sure you can adapt my approach to that issue. If not, feel free to ask for further help. I’ll most likely need you to share your workflow and some example data in that case though. Dummy data would be fine also.
Here’s the code:
out_error = 0;
//try-block fails if one of these Flow Variables doesn't exist
try {
//list of all Flow Variables to check
getCell("serialNumber", tString);
}
catch (Exception e) {
out_error = 1;
}
Ah, thanks for clarifying this. Now I understand why missing flow variabels are not handled the way I expected within a try-catch block.
Also, thanks for the code, very useful. I will do it that way and throw an exception manually. That should work!