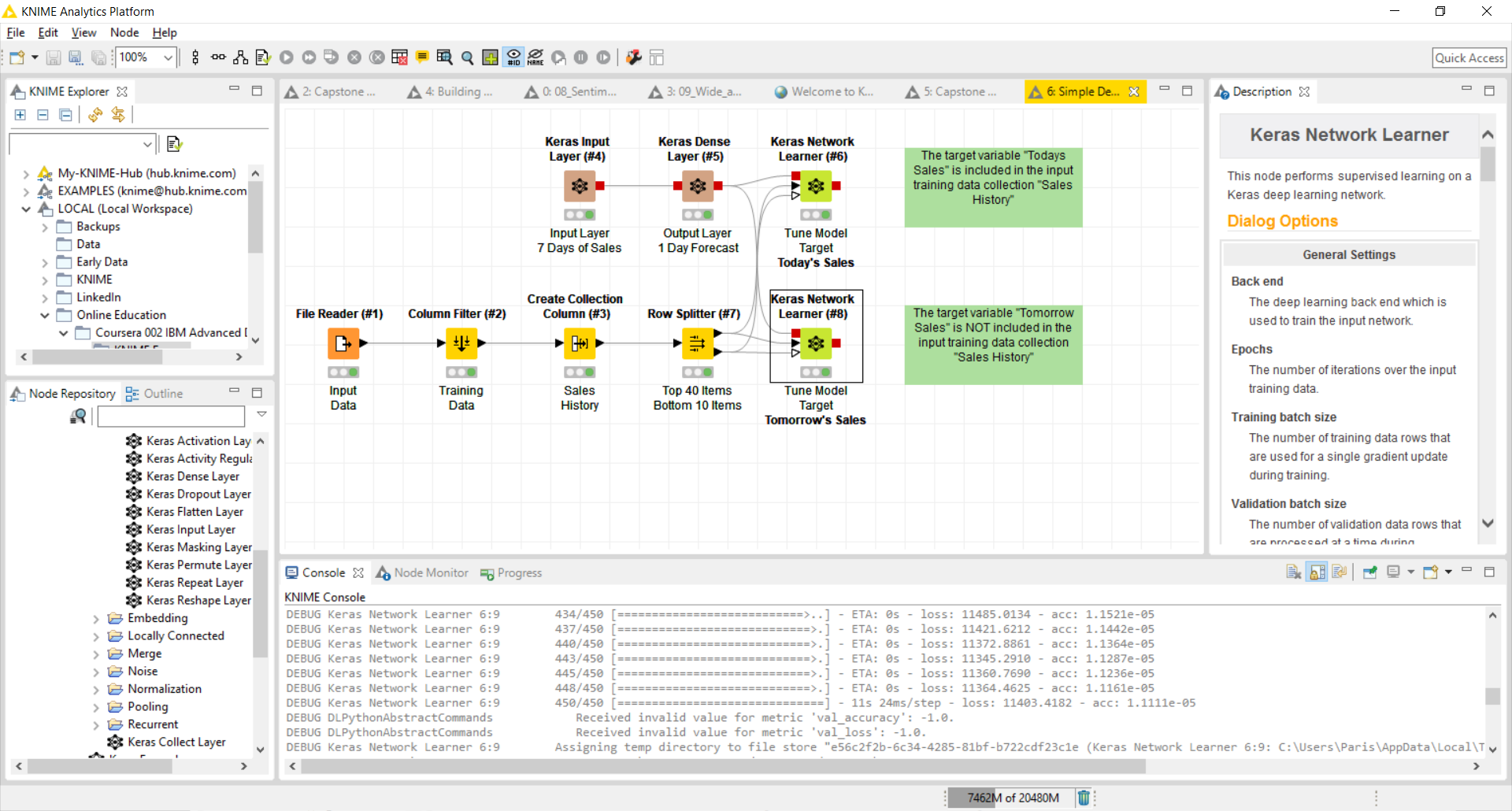
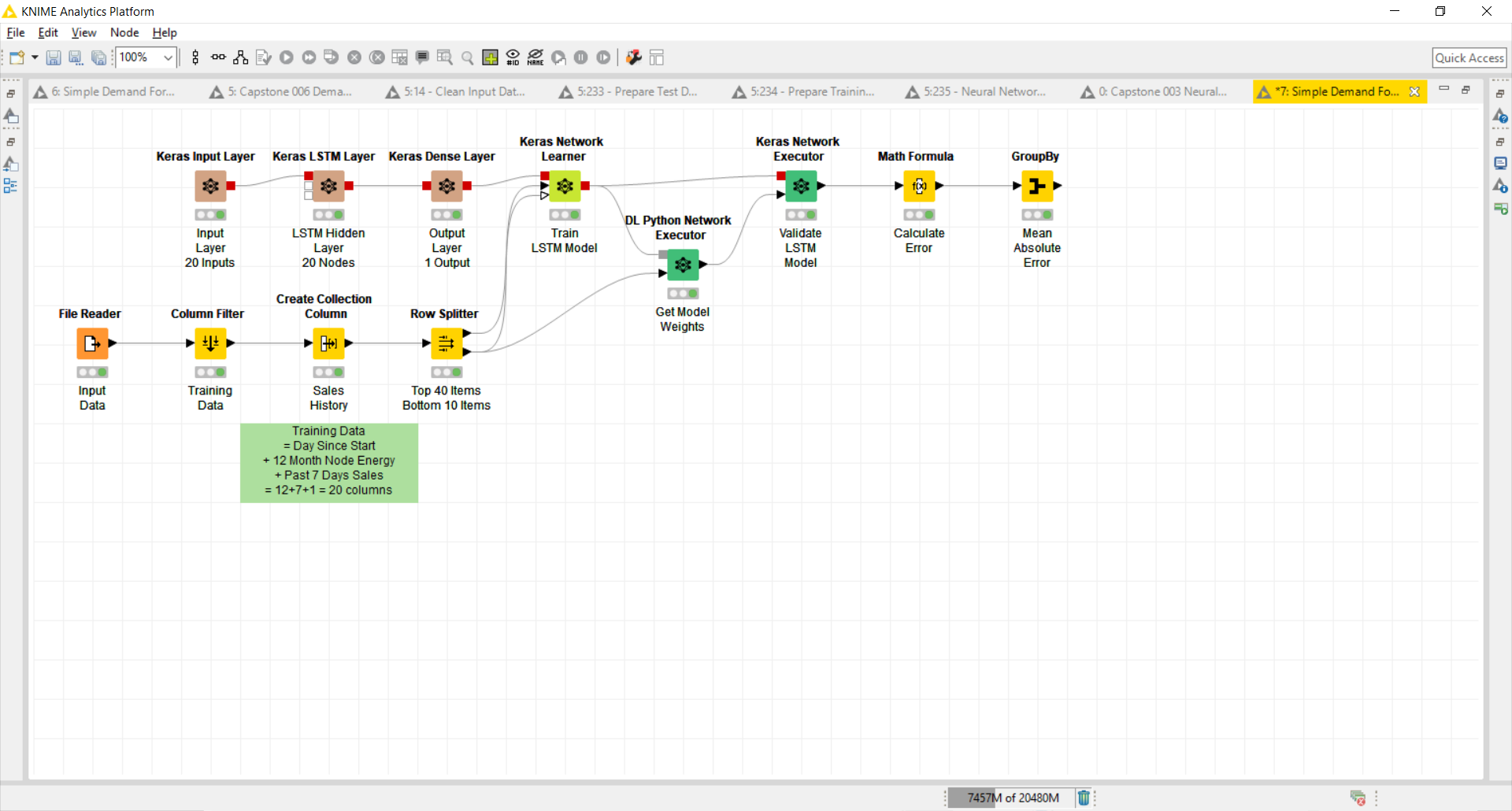
Can somebody please help me tune this neural network?
Simple Demand Forecast Neural Network 001.knwf (3.4 MB)
I’m trying to reproduce my Python Keras neural networks in KNIME and I can’t even get a simple feed-forward network to tune.
I’ve started with a traditional 3-layer neural network comprising of the following layers:
- Input Layer
- Hidden Layer (implied)
- Output Layer
I’ve pulled historic sales data from a Kaggle challenge (https://www.kaggle.com/c/demand-forecasting-kernels-only/data) and I’m trying to train this neural network to recognize weekly sales trends. That is, I want the model to recognize that last Monday’s sales are proportional to this Monday’s sales. I’ve got 7 input nodes (each with sales data from the last 7 days) and 1 output node (used to predict the sales for tomorrow). Once I get things working I’d like to train the model to recognize seasonality as well as year-over-year growth.
To test the network I’ve made it even easier by asking the neural network to predict today’s sales, where today’s sales are actually passed within the last 7 days of data.
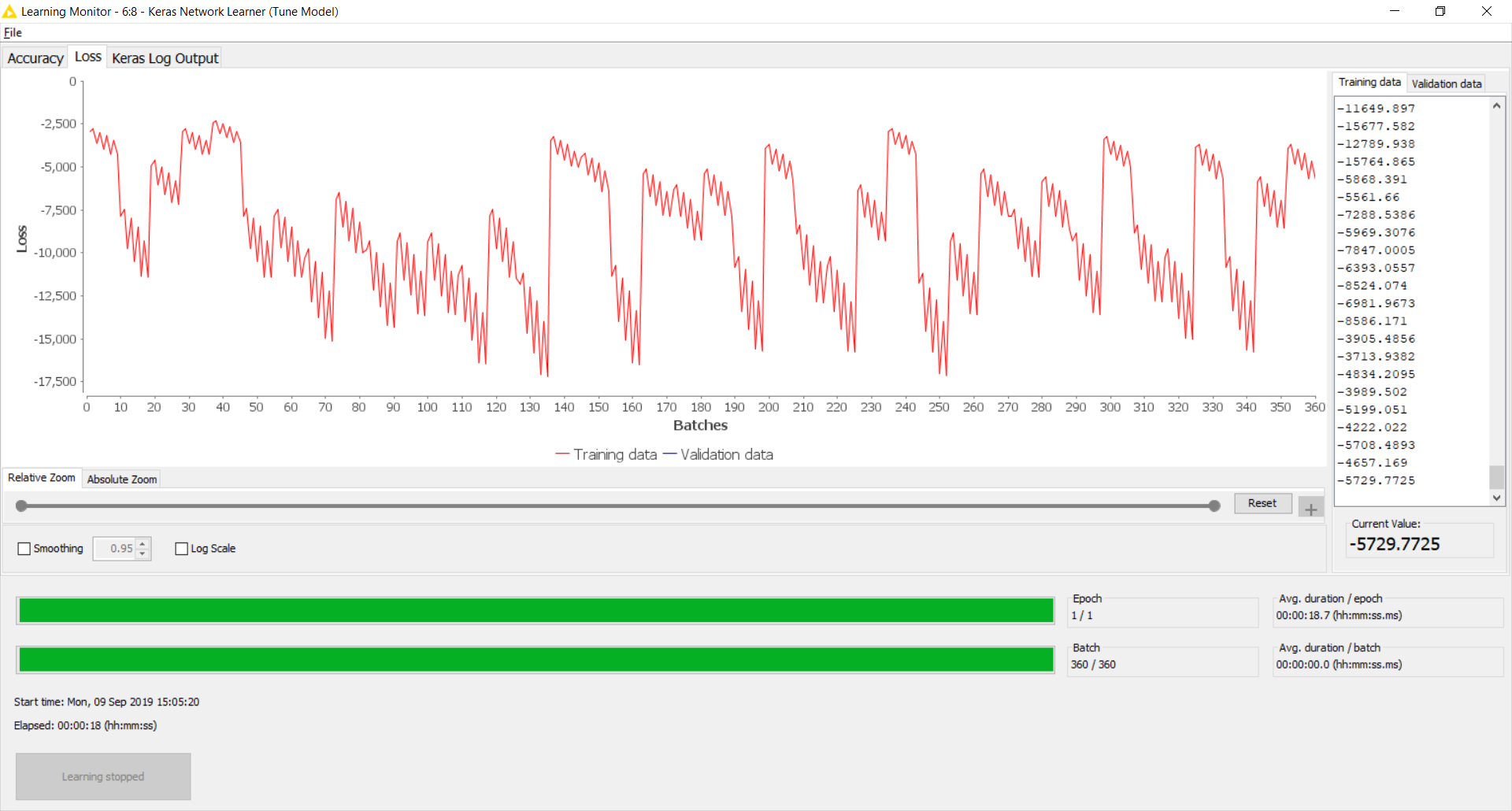
But my results are horrendous!
The log from the Learning Monitor for [target = Today] looks like this:
Epoch 1/1
1/360 [..............................] - ETA: 1:12 - loss: 41.1427 - acc: 0.0050
6/360 [..............................] - ETA: 15s - loss: 1308.4251 - acc: 8.3333e-04
9/360 [..............................] - ETA: 12s - loss: 1380.3868 - acc: 5.5556e-04
12/360 [>.............................] - ETA: 11s - loss: 3253.8582 - acc: 4.1667e-04
15/360 [>.............................] - ETA: 10s - loss: 5183.7564 - acc: 3.3333e-04
17/360 [>.............................] - ETA: 10s - loss: 6294.8577 - acc: 2.9412e-04
20/360 [>.............................] - ETA: 9s - loss: 6610.1236 - acc: 2.5000e-04
23/360 [>.............................] - ETA: 9s - loss: 6184.6507 - acc: 2.1739e-04
26/360 [=>............................] - ETA: 9s - loss: 6232.6921 - acc: 1.9231e-04
28/360 [=>............................] - ETA: 9s - loss: 6035.7421 - acc: 1.7857e-04
31/360 [=>............................] - ETA: 8s - loss: 5638.0236 - acc: 1.6129e-04
32/360 [=>............................] - ETA: 9s - loss: 5464.3688 - acc: 1.5625e-04
35/360 [=>............................] - ETA: 8s - loss: 5203.6640 - acc: 1.4286e-04
38/360 [==>...........................] - ETA: 8s - loss: 4900.0533 - acc: 1.3158e-04
41/360 [==>...........................] - ETA: 8s - loss: 4603.7346 - acc: 1.2195e-04
44/360 [==>...........................] - ETA: 8s - loss: 4405.1444 - acc: 1.1364e-04
47/360 [==>...........................] - ETA: 8s - loss: 4480.1594 - acc: 1.0638e-04
50/360 [===>..........................] - ETA: 8s - loss: 4743.8953 - acc: 1.0000e-04
53/360 [===>..........................] - ETA: 7s - loss: 5436.0964 - acc: 9.4340e-05
55/360 [===>..........................] - ETA: 7s - loss: 5715.3838 - acc: 9.0909e-05
59/360 [===>..........................] - ETA: 7s - loss: 5987.4896 - acc: 8.4746e-05
61/360 [====>.........................] - ETA: 7s - loss: 6137.9276 - acc: 8.1967e-05
64/360 [====>.........................] - ETA: 7s - loss: 6749.1277 - acc: 7.8125e-05
67/360 [====>.........................] - ETA: 7s - loss: 7116.1035 - acc: 7.4627e-05
69/360 [====>.........................] - ETA: 7s - loss: 7593.8689 - acc: 7.2464e-05
72/360 [=====>........................] - ETA: 7s - loss: 8103.8618 - acc: 6.9444e-05
75/360 [=====>........................] - ETA: 7s - loss: 8307.9650 - acc: 6.6667e-05
78/360 [=====>........................] - ETA: 7s - loss: 8440.0061 - acc: 6.4103e-05
81/360 [=====>........................] - ETA: 7s - loss: 8445.4454 - acc: 6.1728e-05
84/360 [======>.......................] - ETA: 7s - loss: 8799.0436 - acc: 5.9524e-05
87/360 [======>.......................] - ETA: 6s - loss: 9094.5771 - acc: 5.7471e-05
90/360 [======>.......................] - ETA: 6s - loss: 9409.4286 - acc: 5.5556e-05
93/360 [======>.......................] - ETA: 6s - loss: 9734.1981 - acc: 5.3763e-05
96/360 [=======>......................] - ETA: 6s - loss: 9980.4404 - acc: 5.2083e-05
98/360 [=======>......................] - ETA: 6s - loss: 10204.8440 - acc: 5.1020e-05
100/360 [=======>......................] - ETA: 6s - loss: 10370.7380 - acc: 5.0000e-05
103/360 [=======>......................] - ETA: 6s - loss: 10467.4699 - acc: 4.8544e-05
105/360 [=======>......................] - ETA: 6s - loss: 10624.3502 - acc: 4.7619e-05
108/360 [========>.....................] - ETA: 6s - loss: 10754.4471 - acc: 4.6296e-05
110/360 [========>.....................] - ETA: 6s - loss: 10957.5650 - acc: 4.5455e-05
113/360 [========>.....................] - ETA: 6s - loss: 11366.7011 - acc: 4.4248e-05
116/360 [========>.....................] - ETA: 6s - loss: 11862.1118 - acc: 4.3103e-05
118/360 [========>.....................] - ETA: 6s - loss: 11987.4646 - acc: 4.2373e-05
121/360 [=========>....................] - ETA: 6s - loss: 11999.5912 - acc: 4.1322e-05
124/360 [=========>....................] - ETA: 5s - loss: 11925.4825 - acc: 4.0323e-05
126/360 [=========>....................] - ETA: 5s - loss: 12003.1657 - acc: 3.9683e-05
129/360 [=========>....................] - ETA: 5s - loss: 12310.0577 - acc: 3.8760e-05
132/360 [==========>...................] - ETA: 5s - loss: 12622.5914 - acc: 3.7879e-05
133/360 [==========>...................] - ETA: 5s - loss: 12671.4426 - acc: 3.7594e-05
137/360 [==========>...................] - ETA: 5s - loss: 12898.7462 - acc: 3.6496e-05
140/360 [==========>...................] - ETA: 5s - loss: 12759.9382 - acc: 3.5714e-05
143/360 [==========>...................] - ETA: 5s - loss: 12552.1473 - acc: 3.4965e-05
146/360 [===========>..................] - ETA: 5s - loss: 12340.1664 - acc: 3.4247e-05
149/360 [===========>..................] - ETA: 5s - loss: 12175.1636 - acc: 3.3557e-05
151/360 [===========>..................] - ETA: 5s - loss: 12061.2759 - acc: 3.3113e-05
154/360 [===========>..................] - ETA: 5s - loss: 11994.9607 - acc: 3.2468e-05
156/360 [============>.................] - ETA: 5s - loss: 12077.8994 - acc: 3.2051e-05
159/360 [============>.................] - ETA: 5s - loss: 12353.0585 - acc: 3.1447e-05
163/360 [============>.................] - ETA: 4s - loss: 12623.3139 - acc: 3.0675e-05
166/360 [============>.................] - ETA: 4s - loss: 12537.7248 - acc: 3.0120e-05
168/360 [=============>................] - ETA: 4s - loss: 12462.8419 - acc: 2.9762e-05
171/360 [=============>................] - ETA: 4s - loss: 12333.8680 - acc: 2.9240e-05
174/360 [=============>................] - ETA: 4s - loss: 12267.9013 - acc: 2.8736e-05
177/360 [=============>................] - ETA: 4s - loss: 12190.9796 - acc: 2.8249e-05
179/360 [=============>................] - ETA: 4s - loss: 12167.1833 - acc: 2.7933e-05
182/360 [==============>...............] - ETA: 4s - loss: 12073.5335 - acc: 2.7473e-05
186/360 [==============>...............] - ETA: 4s - loss: 11934.0249 - acc: 2.6882e-05
189/360 [==============>...............] - ETA: 4s - loss: 11824.2404 - acc: 2.6455e-05
192/360 [===============>..............] - ETA: 4s - loss: 11940.1421 - acc: 2.6042e-05
194/360 [===============>..............] - ETA: 4s - loss: 12013.8136 - acc: 2.5773e-05
198/360 [===============>..............] - ETA: 3s - loss: 12227.3909 - acc: 2.5253e-05
200/360 [===============>..............] - ETA: 3s - loss: 12244.4892 - acc: 2.5000e-05
203/360 [===============>..............] - ETA: 3s - loss: 12136.9278 - acc: 2.4631e-05
206/360 [================>.............] - ETA: 3s - loss: 12018.5440 - acc: 2.4272e-05
209/360 [================>.............] - ETA: 3s - loss: 11952.3829 - acc: 2.3923e-05
212/360 [================>.............] - ETA: 3s - loss: 11968.1454 - acc: 2.3585e-05
215/360 [================>.............] - ETA: 3s - loss: 12084.7486 - acc: 2.3256e-05
218/360 [=================>............] - ETA: 3s - loss: 12107.6915 - acc: 2.2936e-05
221/360 [=================>............] - ETA: 3s - loss: 12289.4988 - acc: 2.2624e-05
224/360 [=================>............] - ETA: 3s - loss: 12489.4115 - acc: 2.2321e-05
227/360 [=================>............] - ETA: 3s - loss: 12525.3862 - acc: 2.2026e-05
230/360 [==================>...........] - ETA: 3s - loss: 12428.8609 - acc: 2.1739e-05
233/360 [==================>...........] - ETA: 3s - loss: 12422.4053 - acc: 2.1459e-05
235/360 [==================>...........] - ETA: 3s - loss: 12351.1595 - acc: 2.1277e-05
237/360 [==================>...........] - ETA: 2s - loss: 12281.3554 - acc: 2.1097e-05
239/360 [==================>...........] - ETA: 2s - loss: 12192.0119 - acc: 2.0921e-05
243/360 [===================>..........] - ETA: 2s - loss: 12020.3736 - acc: 2.0576e-05
246/360 [===================>..........] - ETA: 2s - loss: 12069.1666 - acc: 2.0325e-05
249/360 [===================>..........] - ETA: 2s - loss: 12303.1701 - acc: 2.0080e-05
252/360 [====================>.........] - ETA: 2s - loss: 12436.7261 - acc: 1.9841e-05
256/360 [====================>.........] - ETA: 2s - loss: 12601.9745 - acc: 1.9531e-05
258/360 [====================>.........] - ETA: 2s - loss: 12640.4291 - acc: 1.9380e-05
261/360 [====================>.........] - ETA: 2s - loss: 12667.2074 - acc: 1.9157e-05
263/360 [====================>.........] - ETA: 2s - loss: 12686.5048 - acc: 1.9011e-05
266/360 [=====================>........] - ETA: 2s - loss: 12595.4022 - acc: 1.8797e-05
269/360 [=====================>........] - ETA: 2s - loss: 12541.3375 - acc: 1.8587e-05
273/360 [=====================>........] - ETA: 2s - loss: 12491.4365 - acc: 1.8315e-05
276/360 [======================>.......] - ETA: 2s - loss: 12481.2461 - acc: 1.8116e-05
279/360 [======================>.......] - ETA: 1s - loss: 12464.7419 - acc: 1.7921e-05
281/360 [======================>.......] - ETA: 1s - loss: 12466.3107 - acc: 1.7794e-05
284/360 [======================>.......] - ETA: 1s - loss: 12383.0751 - acc: 1.7606e-05
286/360 [======================>.......] - ETA: 1s - loss: 12347.9585 - acc: 1.7483e-05
289/360 [=======================>......] - ETA: 1s - loss: 12346.7884 - acc: 1.7301e-05
292/360 [=======================>......] - ETA: 1s - loss: 12348.0108 - acc: 1.7123e-05
295/360 [=======================>......] - ETA: 1s - loss: 12396.0276 - acc: 1.6949e-05
297/360 [=======================>......] - ETA: 1s - loss: 12428.4331 - acc: 1.6835e-05
301/360 [========================>.....] - ETA: 1s - loss: 12360.6918 - acc: 1.6611e-05
304/360 [========================>.....] - ETA: 1s - loss: 12259.6471 - acc: 1.6447e-05
306/360 [========================>.....] - ETA: 1s - loss: 12194.8393 - acc: 4.9020e-05
310/360 [========================>.....] - ETA: 1s - loss: 12196.0194 - acc: 4.8387e-05
312/360 [=========================>....] - ETA: 1s - loss: 12218.6873 - acc: 4.8077e-05
316/360 [=========================>....] - ETA: 1s - loss: 12301.3521 - acc: 4.7468e-05
319/360 [=========================>....] - ETA: 0s - loss: 12332.4387 - acc: 4.7022e-05
321/360 [=========================>....] - ETA: 0s - loss: 12401.6317 - acc: 4.6729e-05
324/360 [==========================>...] - ETA: 0s - loss: 12458.0278 - acc: 4.6296e-05
327/360 [==========================>...] - ETA: 0s - loss: 12453.6503 - acc: 4.5872e-05
329/360 [==========================>...] - ETA: 0s - loss: 12393.3611 - acc: 4.5593e-05
332/360 [==========================>...] - ETA: 0s - loss: 12315.8433 - acc: 4.5181e-05
335/360 [==========================>...] - ETA: 0s - loss: 12299.0822 - acc: 4.4776e-05
336/360 [===========================>..] - ETA: 0s - loss: 12320.2354 - acc: 4.4643e-05
339/360 [===========================>..] - ETA: 0s - loss: 12426.3547 - acc: 4.4248e-05
343/360 [===========================>..] - ETA: 0s - loss: 12538.7709 - acc: 4.3732e-05
345/360 [===========================>..] - ETA: 0s - loss: 12509.6730 - acc: 4.3478e-05
348/360 [============================>.] - ETA: 0s - loss: 12468.1871 - acc: 4.3103e-05
350/360 [============================>.] - ETA: 0s - loss: 12444.8846 - acc: 4.2857e-05
352/360 [============================>.] - ETA: 0s - loss: 12402.9514 - acc: 4.2614e-05
355/360 [============================>.] - ETA: 0s - loss: 12325.5229 - acc: 4.2254e-05
358/360 [============================>.] - ETA: 0s - loss: 12241.9661 - acc: 4.1899e-05
360/360 [==============================] - 13s 37ms/step - loss: 12194.5712 - acc: 4.1667e-05 - val_loss: 10412.9327 - val_acc: 0.0000e+00
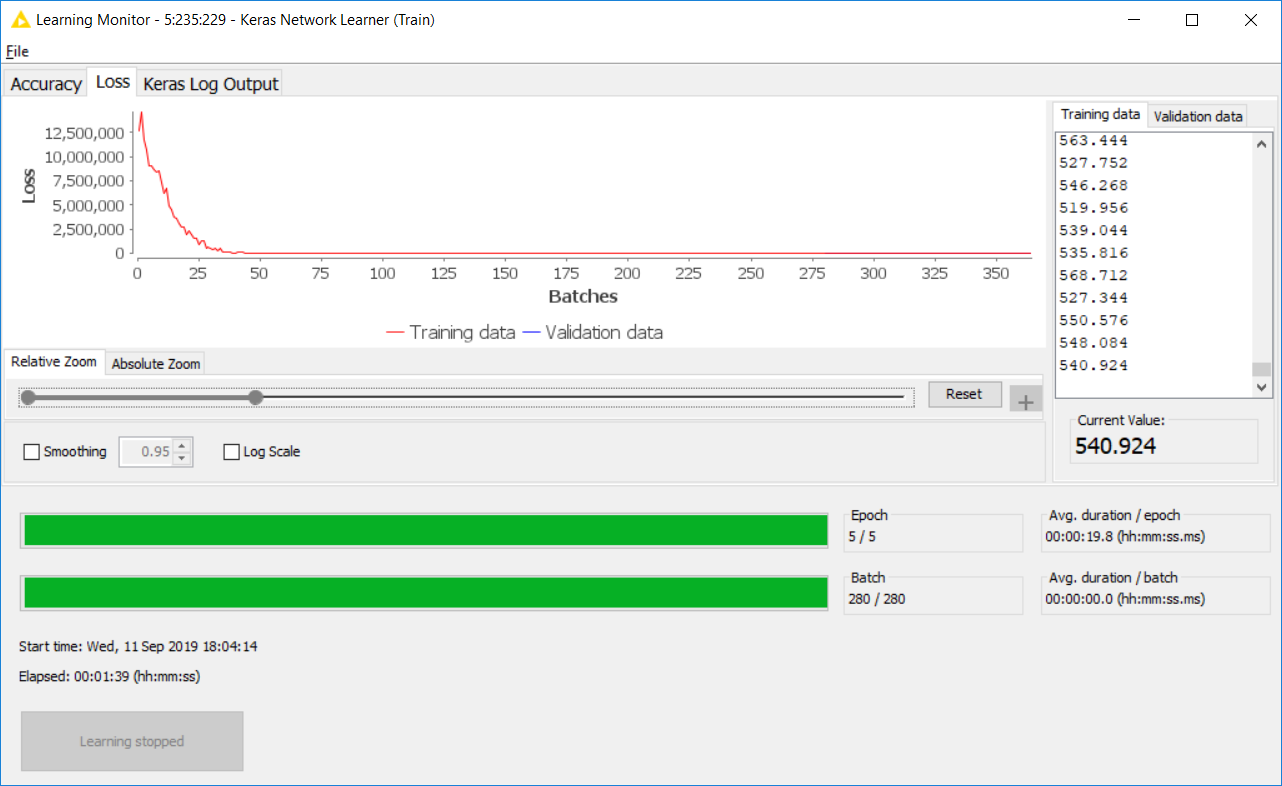
On the other hand, the results I get from Python look ok (Python is running in IBM Watson Studio - not within KNIME).
My node weights from Python for [target = Today] look like this:
Sales(-6) = 0.0000
Sales(-5) = 0.0001
Sales(-4) = 0.0001
Sales(-3) = 0.0000
Sales(-2) = -0.0001
Sales(-1) = 0.0000
Sales(0) = 0.7391
Conclusion: the Python network correctly predicted that today’s sales is proportional to sales from day 0 (that is, sales from today).
And my node weights from Python for [target = Tomorrow] look like this:
Sales(-6) 1.0840
Sales(-5) -0.0591
Sales(-4) 0.0850
Sales(-3) 0.0487
Sales(-2) -0.1068
Sales(-1) 0.0940
Sales(0) 0.2058
Conclusion: Again, the Python network correctly predicted that tomorrow’s sales is proportional to sales from Sales(-6) (that is, sales from 7 days ago).
What am I doing wrong with KNIME?
Additional Question #1: Is there a way to see the compiled Neural Network topology from within KNIME (similar to the Python model.summary() command)?
Additional Question #2: Is there a way to see individual node tuning weights from within KNIME (similar to the Python layer.get_weights() command)?
Simple Demand Forecast Neural Network 001.knwf (3.4 MB)