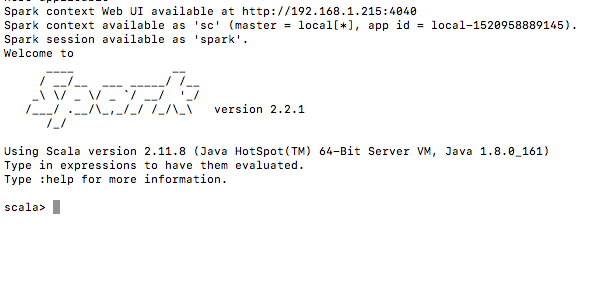
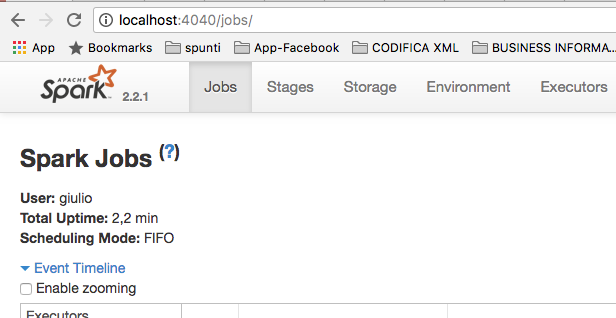
Hi, I’m trying to setting-up the Spark Context Connection.
I have already modified the connection setting (both in preferences>Knime>BigData>Spark and within the node) like that:
When I type in command line the “spark-shell” command everything went fine and I got UI at http://localhost:4040
You can see that in the images above:
But when I try to start Spark Context in Knime it returns an error:
ERROR Create Spark Context 2:204 HTTP Status code: 302 | Response Body:
ERROR Create Spark Context 2:204 Execute failed: Spark Jobserver gave unexpected response (for details see View > Open KNIME log). Possible reason: Incompatible Jobserver version, malconfigured Spark Jobserver
Here below the error_log trace:
org.knime.bigdata.spark.core.exception.KNIMESparkException: Spark Jobserver gave unexpected response (for details see View > Open KNIME log). Possible reason: Incompatible Jobserver version, malconfigured Spark Jobserver
at org.knime.bigdata.spark.core.context.jobserver.request.AbstractJobserverRequest.createUnexpectedResponseException(AbstractJobserverRequest.java:154)
at org.knime.bigdata.spark.core.context.jobserver.request.AbstractJobserverRequest.handleGeneralFailures(AbstractJobserverRequest.java:123)
at org.knime.bigdata.spark.core.context.jobserver.request.GetContextsRequest.sendInternal(GetContextsRequest.java:62)
at org.knime.bigdata.spark.core.context.jobserver.request.GetContextsRequest.sendInternal(GetContextsRequest.java:1)
at org.knime.bigdata.spark.core.context.jobserver.request.AbstractJobserverRequest.send(AbstractJobserverRequest.java:72)
at org.knime.bigdata.spark.core.context.jobserver.JobserverSparkContext.remoteSparkContextExists(JobserverSparkContext.java:410)
at org.knime.bigdata.spark.core.context.jobserver.JobserverSparkContext.access$3(JobserverSparkContext.java:408)
at org.knime.bigdata.spark.core.context.jobserver.JobserverSparkContext$1.run(JobserverSparkContext.java:240)
at org.knime.bigdata.spark.core.context.jobserver.JobserverSparkContext.runWithResetOnFailure(JobserverSparkContext.java:341)
at org.knime.bigdata.spark.core.context.jobserver.JobserverSparkContext.open(JobserverSparkContext.java:230)
at org.knime.bigdata.spark.core.context.SparkContext.ensureOpened(SparkContext.java:64)
at org.knime.bigdata.spark.node.util.context.create.SparkContextCreatorNodeModel.executeInternal(SparkContextCreatorNodeModel.java:155)
at org.knime.bigdata.spark.core.node.SparkNodeModel.execute(SparkNodeModel.java:242)
at org.knime.core.node.NodeModel.executeModel(NodeModel.java:567)
at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1172)
at org.knime.core.node.Node.execute(Node.java:959)
at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:561)
at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:179)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:110)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:328)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:204)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
The problem is that in the installation guide procedure are completely missing the steps for install/configure it on Mac machine. for example the “useradd” command is not recognized. So, this bunch of operations below:
Hi,
I’m sorry but we do not support the installation of the Spark Job Server on Mac. Even though I guess it should work if spark-submit is working as well.
Unfortunately I’m no Mac expert to give you a translation of the different Linux commands but you might get help with that from somebody else in the forum or on the Spark Job Server page.
If you only want to try out the KNIME Big Data Extensions you could also have a look at the new local big data environment extension which is available in our nightly build. You simply need to install the extension (see screenshot) and you are done. The extension comes with a Spark 2.2 runtime, hive and hdfs access to your local hard drive all packaged within a new Create Local Big Data Environment node.
Hi @tobias.koetter ,
thank you for the interesting suggestion. I’ll give a try for sure.
Anyway, if for example I want to run the Spark context without the Create Local Big Data Environment node, what I need to do is:
first of all install spark 2.1from the apache spark site (…or this is an unnecessary step because spark is already present in the Cloudera CDH 5.13? I know that probably for you this question is obvious, but I want to be sure of the steps)
install that specific Cloudera CDH 5.13 (compatible with Spark 2.1)…honestly I didn’t understand what are the installation instructions for this step, cause the link points to a cloudera datasheet page.
install that specific Spark Job server (CDH 5.7 - 5.13, for Apache Spark 2.1)
Did I have missed something? Cause the pdf with installation instruction only refers to how to setup the Spark Job Server, but not the previous steps.
What I don’t understand is why I need to install those cloudera resources…(Important: are they free or not? ) I mean, it shouldn’t be the same thing to install the compatible hadoop version directly from the hadoop site?
And I have also another questions… what’s the main difference between installing spark with these installation steps(for example with cloudera) and using just the new Create Local Big Data Environment node? I would like to understand if the final result is just the same or if there are huge differences as configuration and final practical use.
Did I have missed something? Cause the pdf with installation instruction only refers to how to setup the Spark Job Server, but not the previous steps.
Cloudera CDH, Hortonworks HDP are both Hadoop distributions that simplify the installation, configuration and administration of Hadoop clusters. Both CDH and HDP are free of cost, however both vendors charge money for some enterprise features and support. Our PDF guide explains how to install Spark Jobserver on CDH/HDP clusters.
I mean, it shouldn’t be the same thing to install the compatible hadoop version directly from the hadoop site?
In principle you can do that, it’s just a lot harder to operate then. I guess it is useful for the learning experience, but when you want to do a proper deployment you use one of the Hadoop distributions like HDP or CDH.
And I have also another questions… what’s the main difference between installing spark with these installation steps(for example with cloudera) and using just the new Create Local Big Data Environment node? I would like to understand if the final result is just the same or if there are huge differences as configuration and final practical use.
The Create Local Big Data Environment is completely local, i.e. there is no cluster behind it. Also you do not have to install Spark Jobserver then. However, you are limited by the power your machine where KNIME runs on.
The node is mostly useful for three use cases:
Learning how to use the KNIME big data nodes (on small/medium data).
Rapid prototyping of big data workflows in KNIME on a local subset of the real (large) data
If you have a single big machine (lots of CPU cores and RAM), you can use Spark on “medium” sized data there.
If you are thinking about solving real-world big data use cases, e.g. learning models on giga- or terabytes of data, then you need an acutal Hadoop cluster with Spark Jobserver.
Hi @bjoern.lohrmann, thank you for the reply, much appreciated.
I think I have quite understand the different scenarios.
I wanna ask you another important question:
Is the big data/spark extension also compatible with cloudera CDH 5.14 (which is the latest version)? Cause in the list of compatible version is only present till the 5.13 version.
And another question is about the default spark version included in CDH that is the 1.6. Why they don’t provide the last version of Spark by default? It’s already available the 2.x version. In this circumstance is it fine if I manually install the Spark 2.x version after CDH installation? Will it work or not because there is the default Spark 1.6 version?
Then, I have another question about the step of the pdf installation guidelines called “HOW TO INSTALL ON A KERBEROS-SECURED CLUSTER”. Can some one clarify me how to proceed step-by-step? Are they mandatory for let work the spark knime extension or we can skip these steps? Cause actually my Ubuntu Machine configured with CDH 5.13 has no kadmin command. So I assume that I would need to type:
apt-get install krb5-user
or should I activate Kerberos from cloudera manager panel first? Cause actually is disable by default
Why I ask if these steps are mandatory? Because I have already configured the spark-job-server and when I open Knime platform and try to run again the ‘Create Spark Context’ node it still doesn’t work.
Is the big data/spark extension also compatible with cloudera CDH 5.14 (which is the latest version)? Cause in the list of compatible version is only present till the 5.13 version.
CDH 5.14 will be officially supported with the KNIME summer 2018 release. Until then it is not on the “officially” supported list, but it will work.
And another question is about the default spark version included in CDH that is the 1.6. Why they don’t provide the last version of Spark by default? It’s already available the 2.x version.
This is something you have to ask Cloudera. Probably because they have a lot of customers on 1.6 and migrating from 1.6 to 2.x is a big step. Cloudera provides additional parcels for Spark 2, so you can install Spark 1.x and 2.x in parallel on the same cluster. The documentation for that is on the Cloudera website: https://www.cloudera.com/documentation/spark2/latest/topics/spark2.html
In this circumstance is it fine if I manually install the Spark 2.x version after CDH installation? Will it work or not because there is the default Spark 1.6 version?
I would advise against a manual installation of spark 2.x on a Cloudera cluster. Use the Cloudera Spark 2 parcels and follow their documentation:
Then, I have another question about the step of the pdf installation guidelines called “HOW TO INSTALL ON A KERBEROS-SECURED CLUSTER”. Can some one clarify me how to proceed step-by-step? Are they mandatory for let work the spark knime extension or we can skip these steps?
The steps in this section are mandatory, if you already have a Kerberos-secured cluster. If you don’t, then you don’t have to do these steps. If you are unsure whether or not that is the case, then most probably your cluster is not Kerberos-secured.