@harshadbarge I’ll walk you through my troubleshooting process. Hopefully this is more instructive than me just throwing out what seems like random suggestions.
This error message suggests that there’s something wrong with one of your columns. Basically, the CSV Reader node wants only strings, integers, or double-precision floating-point numbers, so there must be some column that’s misbehaving.
When I open the results of the Loop End node (the last node to complete successfully), I look at the column headers, and I immediately see something strange - there’s a question mark in the Cost Centre column header. What’s going on there?
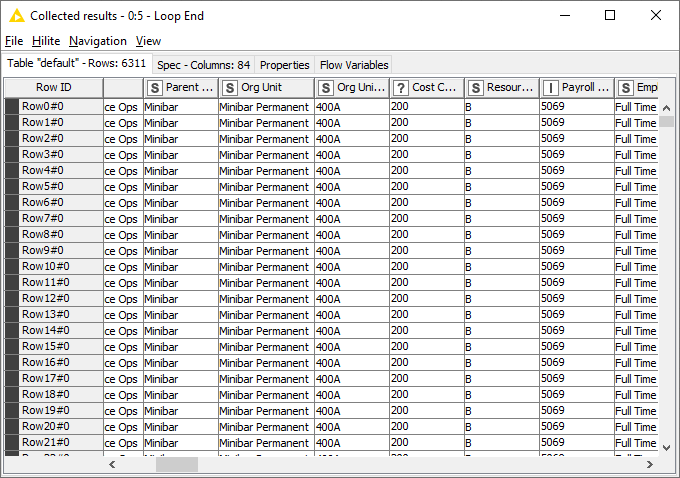
The numbers all look like integers, so why isn’t this being reflected in the header?
I switch over to the Spec tab to get more details:
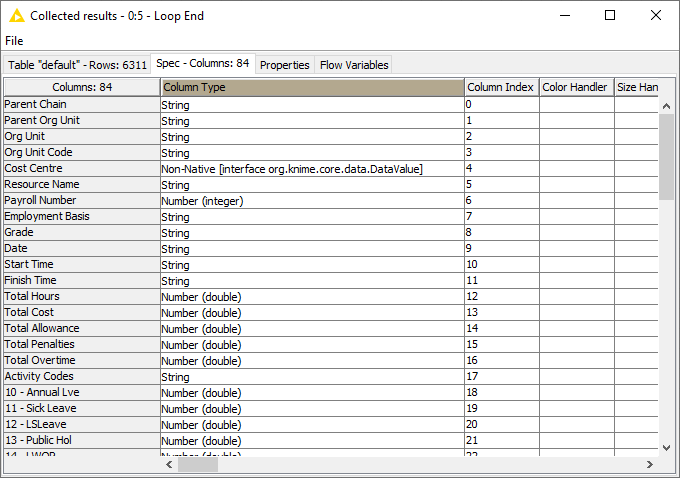
Weird. The column type is marked as “Non-Native”.
I scroll down to see what else is in the column:
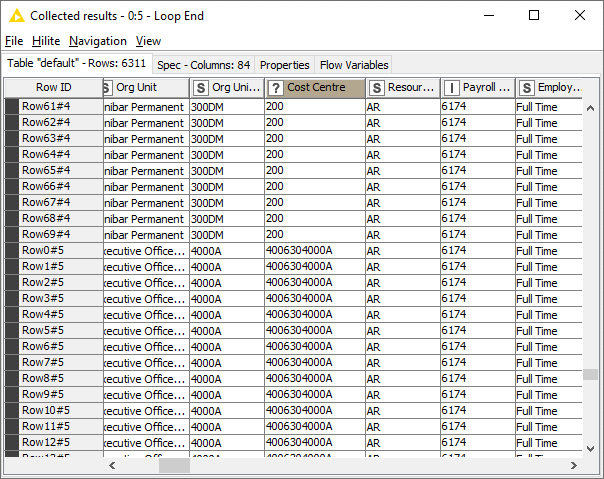
Now I see that there aren’t just integers in the column. There are strings as well. So the column type should be string.
I recall that this table is a result of concatenating several csv files, and I had to scroll down pretty far to get to values that weren’t ‘200’.
I run one iteration of the loop and see that Cost Center is recognized as integer:
I examine all the csv files in Excel, and piece together the following:
In the first csv file, the values in this column are integers, and KNIME recognizes them as such and sets the column type to integer. But in one csv file, the values are strings, and KNIME has no idea what to do with it since the format changes mid-loop. It resolves this conflict by assigning the column an “unknown” format, and the loop ends successfully.
However, as we saw above, the CSV Reader can’t deal with unknown formats.
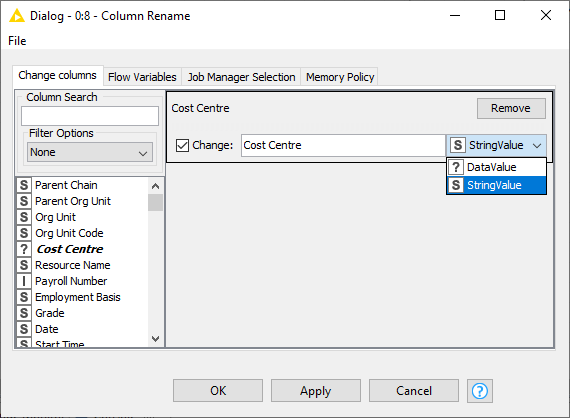
A solution is to insert a Column Rename node after the Loop End node before the CSV Writer, telling KNIME to switch the column type to string:
Good luck!
