I am trying to read data from various sources into Knime. The data comes in XML format and is accessed using a link. Once you click on the link, the data is being downloaded right away.
If I first download the data to my PC and then read it using “XML Reader” then everything works as expected - there is a column with XML and then I can parse it with XPath node.
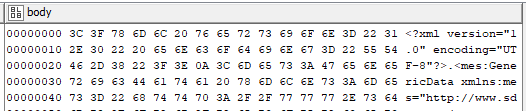
However, the aim is to download the data straight away into Knime, without the need of downloading it first into my PC. If I use “GET Request”, it returns BLOB column and seems to be something random:
If I use XML Reader with “Custom/Knime URL” settings, it also doesn’t work.
The BLOB column is binary data. On the left you see the row number, in the middle there’s the data represented as HEX and on the left there’s the data represented as String. You can see it looks like the beginning of an XML. You can also right-click the column and select a different renderer, but it doesn’t reveal much more information.
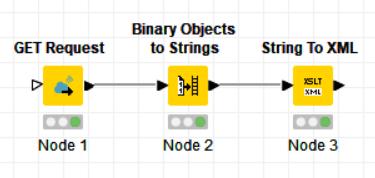
To get the binary data into the XML format, I first transformed it to String and then to XML, using the Binary Objects to Strings node and then the String to XML node.
If you feed the GET Request node a table, it will process the entire table, but make sure to set delays, otherwise you’d flood the target server with requests
Hi @wytux10 and welcome back to KNIME Community Forum,
You can read the XML directly in KNIME:
First, use the HTTP(S) Connector node and input the base URL (https://osp-rs.stat.gov.lt) then add a connection port to the XML Reader node and connect them. The rest of the path can be used as the file location (rest_xml/data/S3R167_M3010214/?startPeriod=2010&endPeriod=2020)
Or
If for any reason you wanna stick with the Get Request node, then the HTML Parser node is enough to convert the binary object to XML.
If you are experienced, by any chance, could you help me parse this XML? I have dealt with XMLs before however I am having trouble making this into a normal table. Thanks in advance!
If you know XPath (the query language) then you should be able to quickly learn how the XPath node works with the help of the node description. If you want to do it the hard way, like myself, here’s a summary of the most important features:
As a general rule, I use one XPath node for each hierarchy level of the XML.
Return type: Which data type you want. Node cell means you want to query for a portion of the XML
Multiple tag options: How the results should be if there’s more than one match:
a) single cell → take the first element
b) collection cell → return result array in a single KNIME cell, as collection
c) multiple rows/columns → each element goes in one row/column