I have a question about how to use the Correlation Filter node.
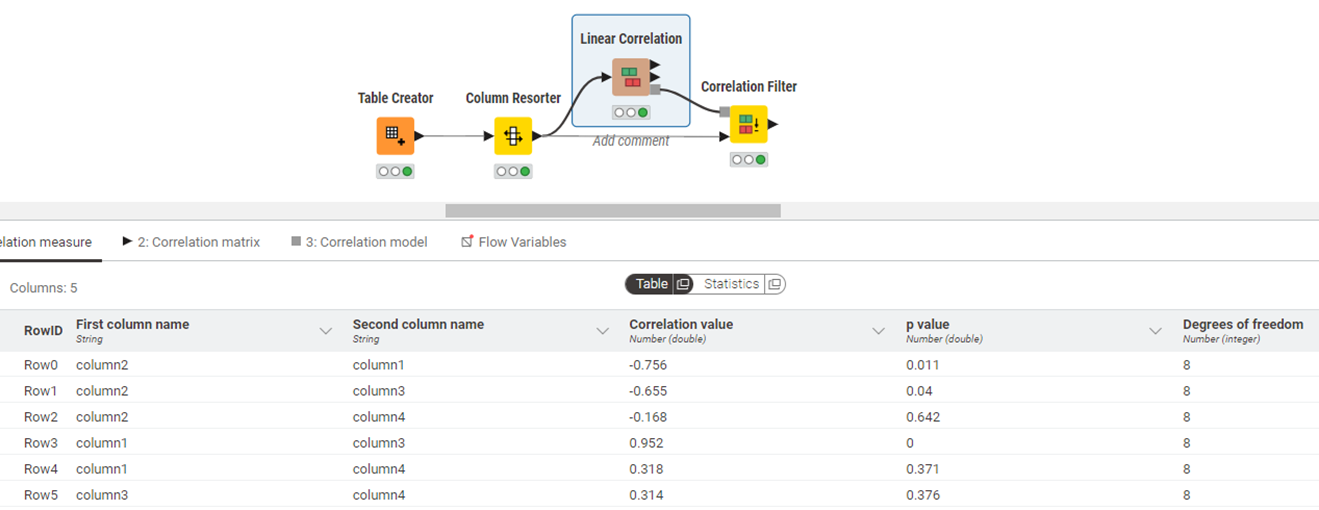
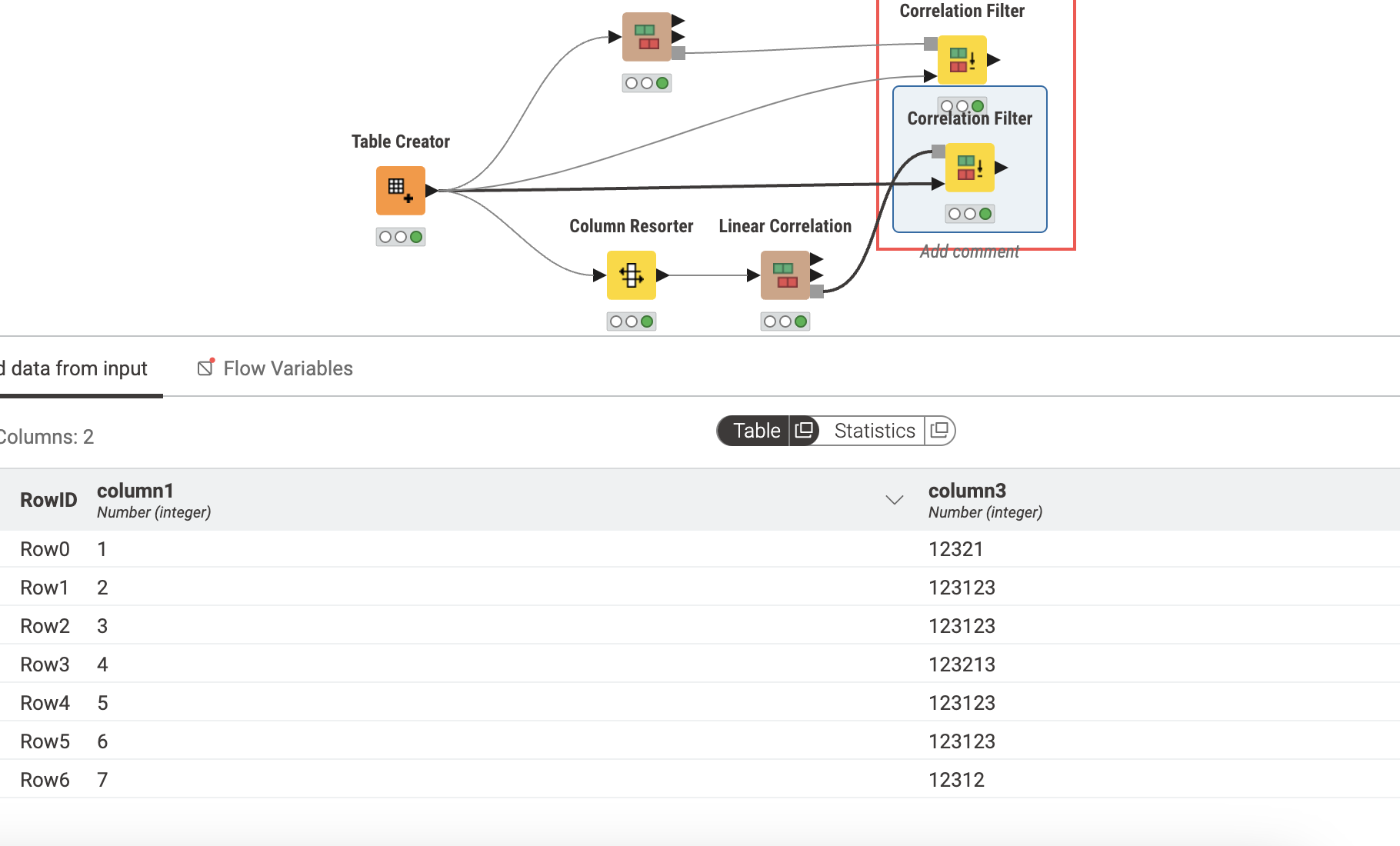
Below is a result table showing the correlation coefficient between the first and second columns when running Linear Correlation.
I have set the threshold value of the Correlation Filter to 0.7.
I understand that the logic is to compare the first and second columns one by one by the specified threshold and delete the second column if the absolute value is greater than 0.7.
When this happens, it proceeds from the first row and column1 should be deleted, but it is not.
If the above deletion logic is correct, the order of deletion should be :
column1 is deleted from the first row.
since column1 is deleted, the deletion logic for column3 and column4 is skipped.
eventually, only column1 is deleted because there is no absolute value above 0.7.
and only column 2,3,4 remain, right?
But the result is that column1 and column4 are left.
Is this incorrect logic? Or am I misunderstanding the mechanics of the Corrleation Filter?
Hi @JaeHwanChoi, the Correlation Filter checks columns one by one. If a column is removed due to the threshold, the filter skips all checks with that column. That’s why only columns 1 and 4 are left.
Row0. Compare columns 1 and 2; 0.756 > 0.7 == True → remove col 2 as it is redundant You said,
If the first column is column2 and the second column is comparing column1, why is the second column, column1, not cleared and the first column, column2, is cleared?
This is the most curious reason. If column2 is the most important variable and is in the front, it should be cleared by comparing the correlation coefficients of the other variables based on that variable, but does this automatically clear one of the two columns based on the ascending order of the columns?
What is the priority of being cleared? A quick answer would be appreciated.
So i took a look at the source code for the node, it does not immediately stand out to me why such is the case, however if you go into the source code below:
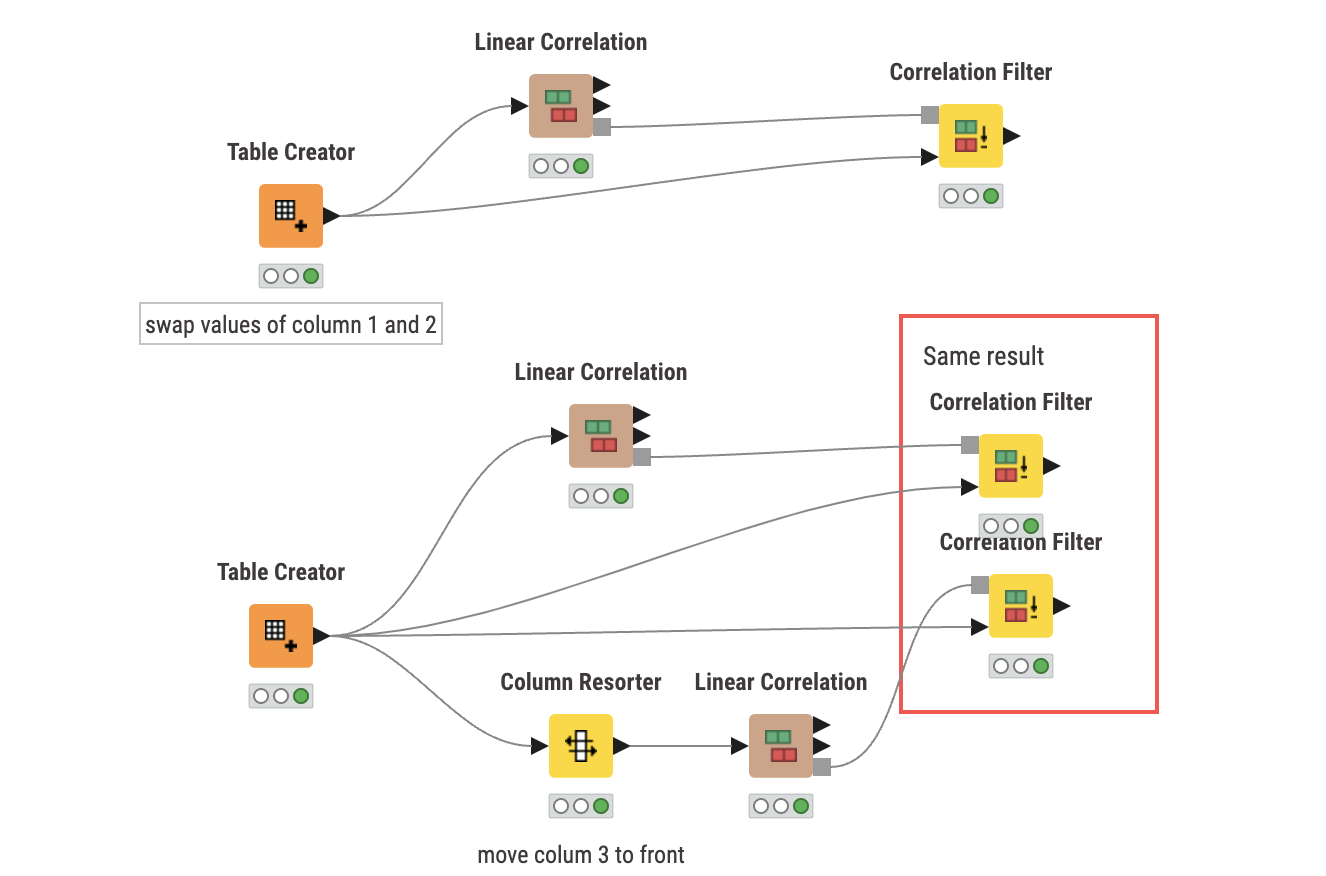
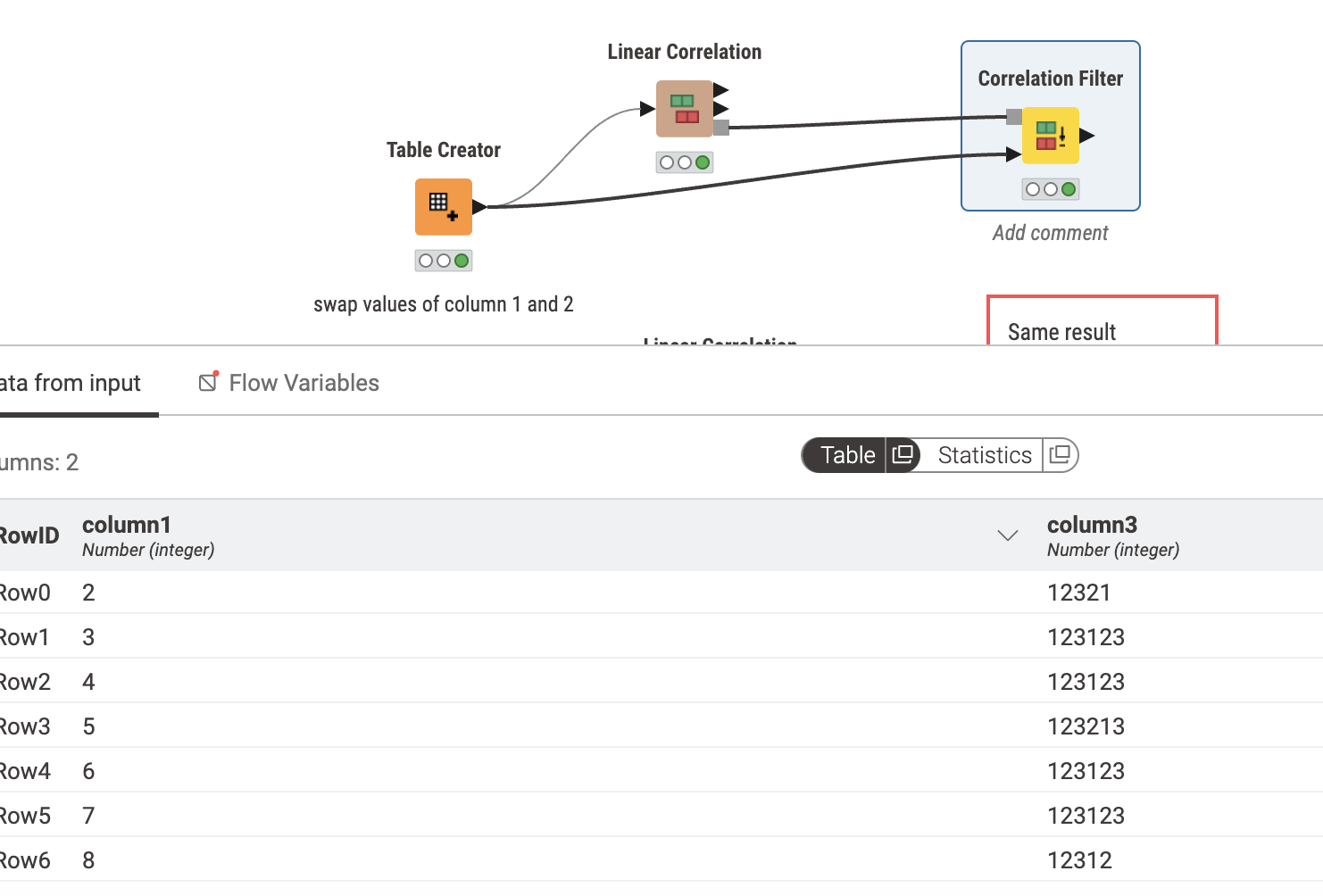
I believe you want to look at line 206 and past. It iterates based on index so I am assuming column_1 is technically still tied to index of 1. To test this, I have a sample workflow below where I swap the numbers between column 1 and 2 to see if we actually keep columns 2 values:
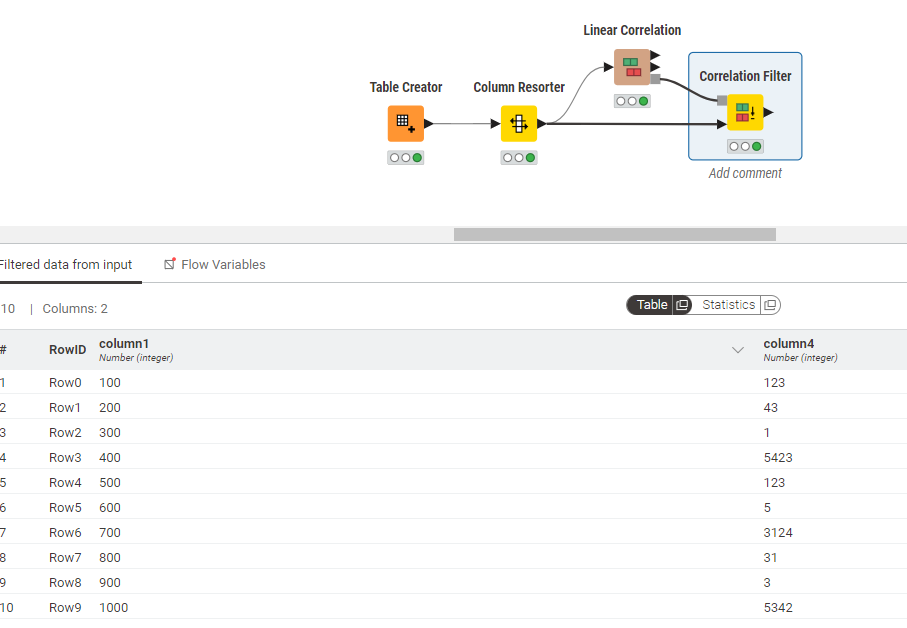
So let’s look at the bottom part, I will explain what is going on. I have a set of values where I expect to have columns 1 and 3 as output. I try rearranging column 2 to the front but I still get the same output.
You can see column 1 and 3 output. But, if we go the top and swap the values, we do see columns 2 values being outputted now. I am certain it is based on original index of the column which is why you see column 1 being kept and not 2 despite rearranging them using a node.
I tried the repositioning and it does not work in that respect. You would have to make a new table with the data you want to be retained to be at the front.
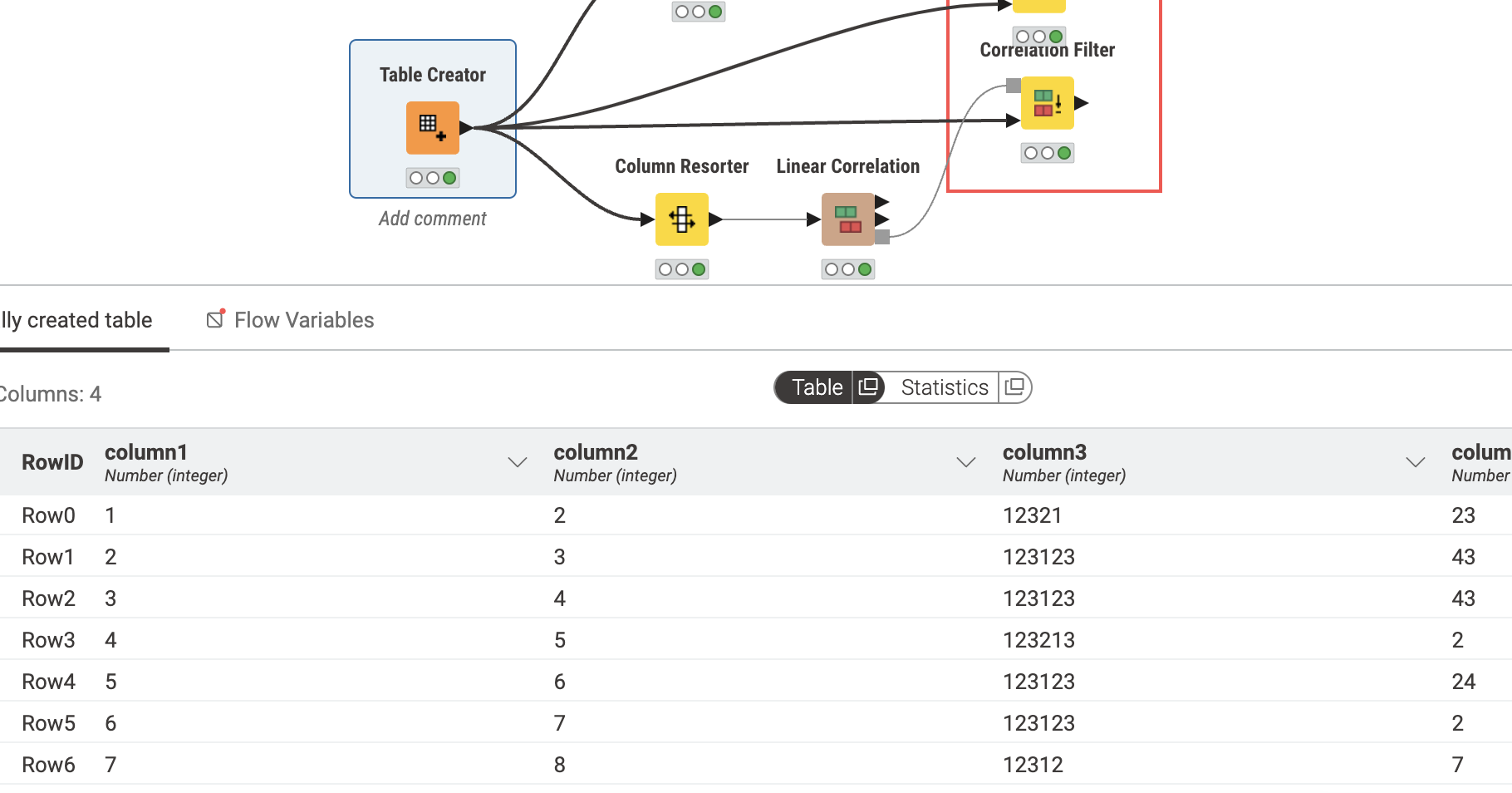
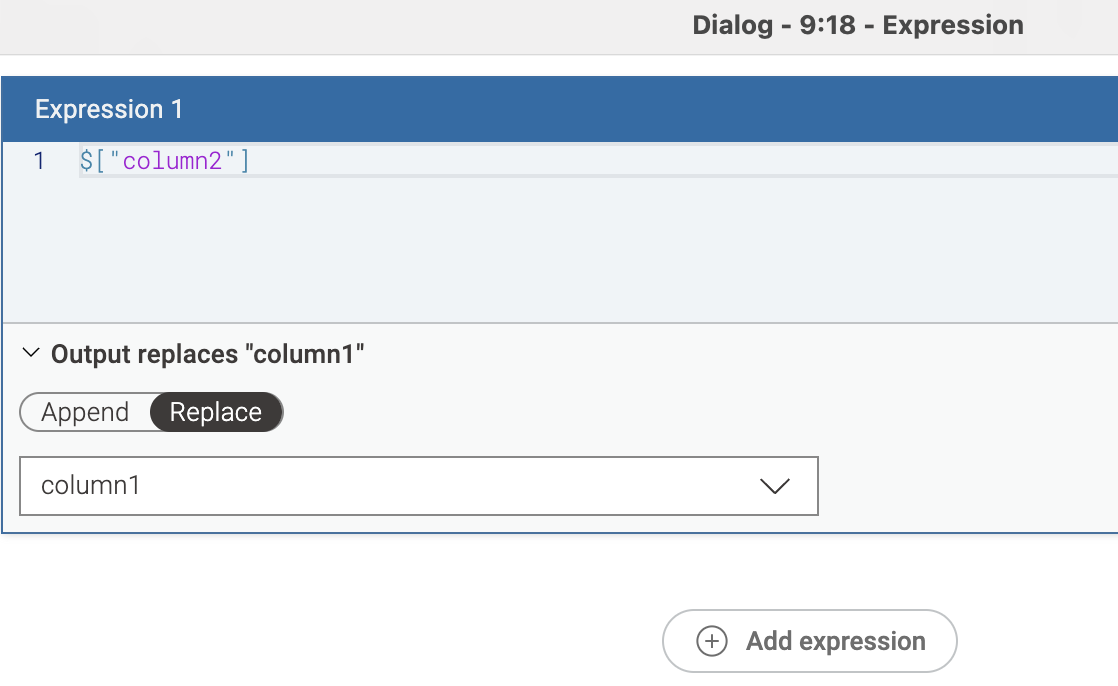
You can use the Expression node as such to swap values. However, you need to store the column you are replacing in a temporary column then remove it after you are done:
Store column1 in a temp column → replace column1 with columnX → replace columnX with temp column → remove temp column (column filter)