I am wokring with cross-validation nodes and I have a couple of questions concerning them.
Firstly, I am doing a 10-fold cross-validation for a logistic regression model (a learner and a predictor). Now, after the 10-fold validations are done, a predictive model is stored in the learner node. My question is: is the stored model an average of all 10-folds or is it the model for the final fold?
The other thing I want to ask about is the "leave-one-out" of "jackknifing". This method leaves one sample as the test sample and uses all other obesrvations for building the model at a time, My sample is a 1000 observation so the calcualtion is made a 1000 times. When I check the error rates from this method, it gives strange numbers, for example it says the error rate is "0.123" for one of the folds. How come? as far as I can understand, this method is testing one sample at a time, so the answer is only TRUE or FALSE, or 1 and 0, how can this method give me an error rate of "0.123" for one of the folds?
The model that the learner outputs is the last trained model and not an average model.
For the second question, I suspect that you are using the wrong set as input for the predictor. You can easily check whether the predictor node outputs only one row or several.
The model is being established based on a certain set of data, which is coming from "column filter" node. The cross validation node is using the leave-one-out method, and the error rates are shown in the box. I hope this made things more clear.
Ah, you are doing regression. For regression (i.e. numerical values) the difference between the correct value and the predicted value is computed and that can take on almost arbitrary values.
I have a question about the confusion matrix generated by the cross-validation. I used the
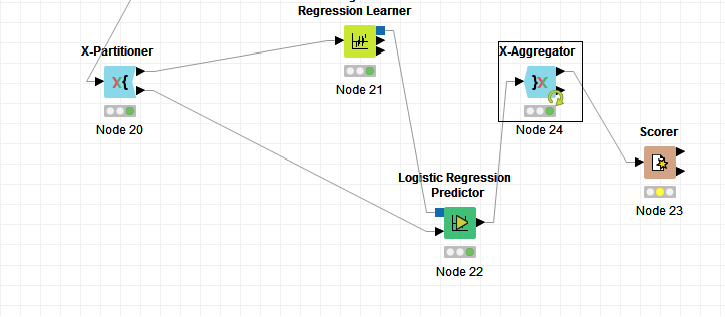
X-aggregator before the predictor node. My question is: are the numbers generated by the confusion matrix from one best model from the 10 tests or from the average of these ten folds?
Can you share the relevant part of your workflow? The predictor node should precede X-aggregator, like in the example shared by @Error404 above. If you calculate a confusion matrix on the output of the aggregator node, then you run it on the out-of-fold predictions for the complete data set. This is for sure different from the predictions from the best model (and you should not use such “best” model out of those N trained models in N-fold split).
{kind=link}