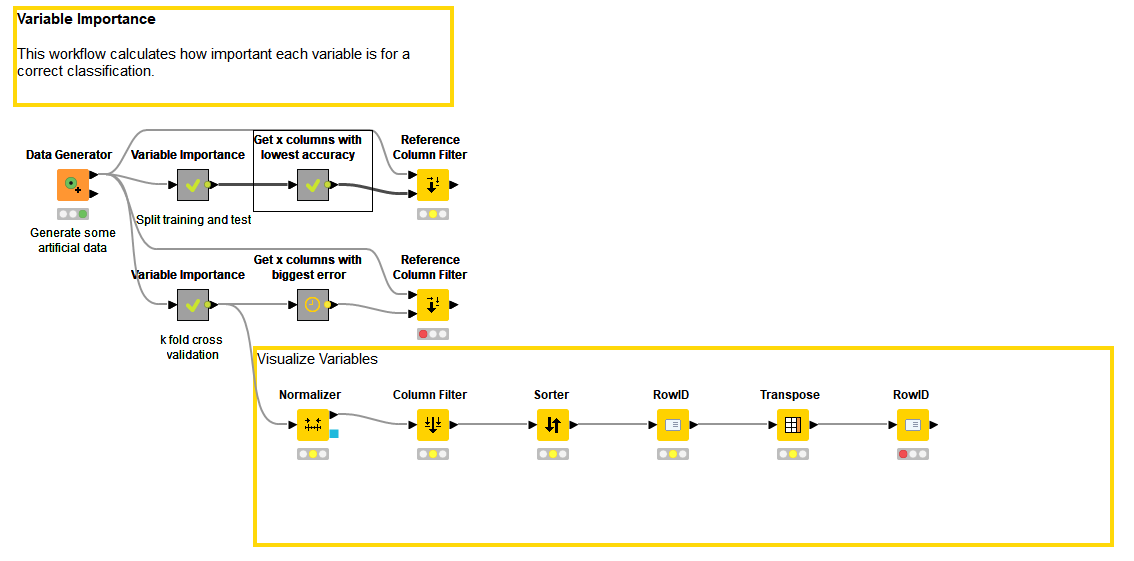
There is one example workflow given in the KNIME public server named variable importance.
after running the workflow I have this as output. i would like to know what does the exactly show. Does this mean Universe_1_3 has the maximum amount of errors in the prediction model??? And then how do we get to know which input variable has the maximum influence on the output classification??
I assume you are talking about the workflow /04_Analytics/11_Optimization/04_Meassuring_Variable_Importance.
The Split Training and Test is the simpler case:
We are spliting the data into training and test set.
We are learning n models. Each is learned on n-1 features (so one feature k is left out).
The model is now evaluated on the test set.
The error of this model (without feature k) is the variable importance of feature k. The higher this error the more important feature k is for this model.
And this is what you see in the plot. The variable importance for each feature normalized from 0 to 1.
The k fold cross validation does the same but calculates the error using k-fold cross validation.
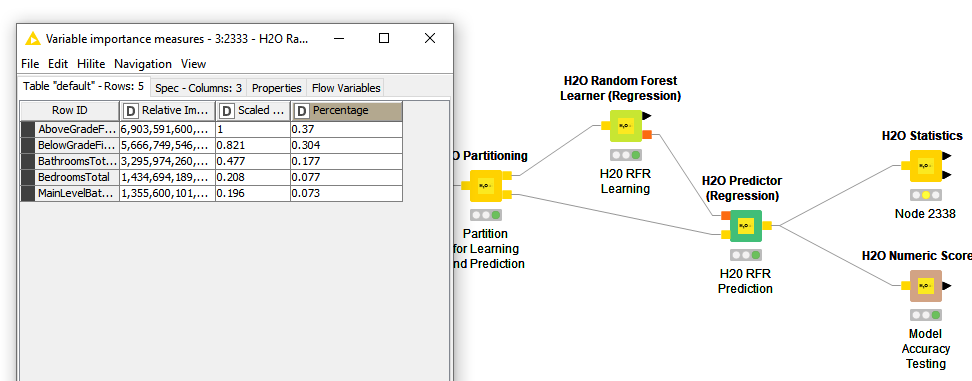
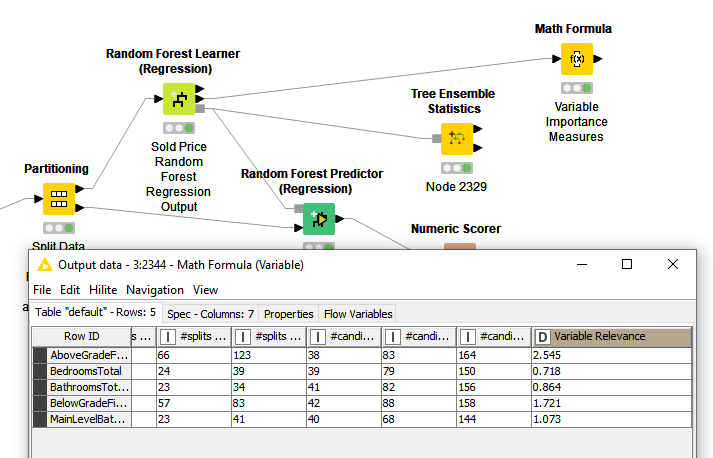
Does the H20 Random Forest (regression) output “variable importance measures” (graphic below) and/or the KNIME Random Forest (regression) math formula for variable importance “divide #splits by #candidates and sum” (graphic below) safely replace the workflow “measuring variable importance” (graphic below)? Do you receive the same general outcome of variable importance using any of these three tools? thanks