Hi,
I have a question concerning the stemming procedure. Is there a way of retrieving the unstemmed terms?
The stemming is performed on a document cell, and creates altered documents. Afterwards, I create bag of words with the stemmed terms. I also tried to create a Bag of words with the unstemmed documents, however, there is no clear matching between the two bag of words. The problem is that the length of the bag of words differs, as there are less stemmed words than unstemmed. There is a workflow in the from words to wisdom book, to join those two together but it’s not producing correct results. I can imagine of some fuzzy matching between stemmed and unstemmed terms on a per document level, which would be quite complicated.
I would like to have unstemmed words to create a word cloud as the stemmed words and not nice to view.
Thanks for your help!
Hi @Lukasa -
Have you looked at this workflow from the hub that demonstrates how to join terms from bags of words that have been stemmed differently?
As for visualization, one way to handle that might be to branch your workflow at the stemming phase, such that you have one branch dedicated to viz, and another for whatever analysis it is you want to do.
Here’s an example of a portion of a preprocessing workflow where the Stanford Lemmatizer node is used to produce human readable words explicitly for a word cloud in one branch, and the Snowball Stemmer node is used to prepare documents for a classification model further downstream.
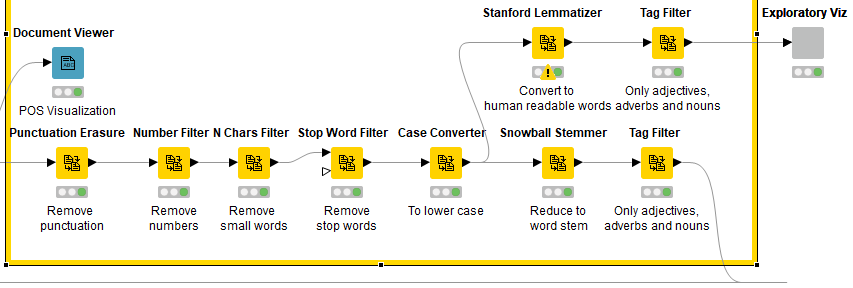
Hi Scott,
thanks for your quick reply! I will try to split my workflow and do the viz independtly from the stemming. But I would also combine the words with the same stem vor the word cloud. I came so far and found the workflow on hte KNIME Hub, but unfortunenately it doesn’t solve the issue. I have the following sentence (sorry for the german):

After stemming, the two terms in red become equal so that afterwards the bag of words of the stemmed and not-stemmed documents are of different length and the join on “rowID” does not match anymore for the lower part:
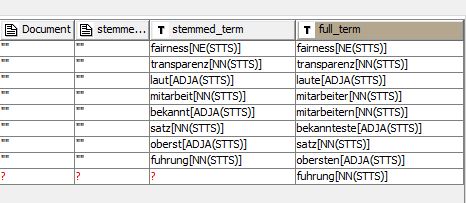
Maybe its a german specific issue as the two red terms are tagged equal. But so far I cannot resolve it… And a word cloud with stemmed words is not really an option.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.